



tesseract ocr是款功能非常强大的图像识别类库,软件一开始是由惠普进行开发的,画面成为了Open source,而且软件推出之后,成绩一直都是相当的理想,不过由于时间的不断增加,软件也就越来越显得力不从心,不过软件的许多的功能还是相当的不错的,而且拥有的一些技术也是相当的超前,使它一直的都在不断的保持着竞争力;软件的操作简单,运行稳定。
软件功能
托管所有代码
存储库帮助您将代码保存在一个位置,即使您使用SVN或使用Git LFS处理大文件也是如此。
由于所有GitHub计划都包含无限的私有存储库,您可以根据需要创建或导入任意数量的项目。自信地进行更改
以精确的提交更改代码,以便您可以快速搜索修订历史记录中的每个提交消息以查找更改。
使用blame视图来跟踪更改,并发现您的文件和您的代码基础是如何演变的。包和发布代码
当您准备好分享时,您可以将最近关闭的里程碑或完成的项目的更改打包到新版本中。
草拟和发布发行说明,发布预发布版本,附件,并直接链接到最新的下载。
软件特色
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
Tesseract目前已作为开源项目发布在Google Project,其项目主页在这里查看,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。
不像其他OCR引擎(例如美国邮政业用于分类邮件的),Tesseract不能识别手写,而且只能识别一共大约64中字体的文本。
Tesseract需要一些处理来改善OCR结果,图像需要被放缩,图像有非常多的差异,另外还有水平排布的文字。
最后,Tesseract仅仅支持Liuux,Windows,Mac OS X。
使用方法
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:
附录:
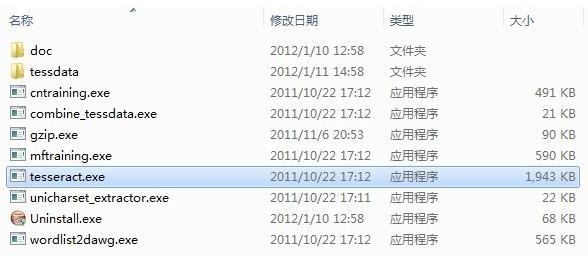
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:
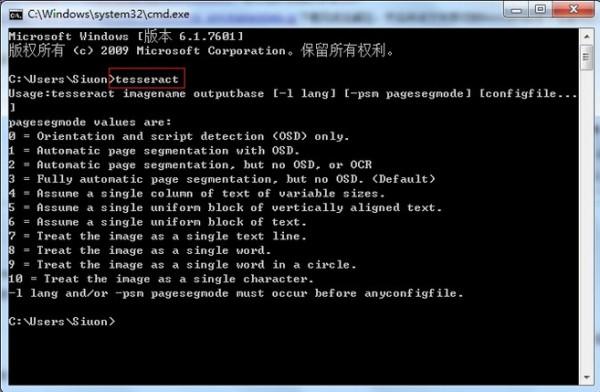
如果出现如上输出,表示安装正常。
我准备了一张验证码

放在D盘根目录下,上图:
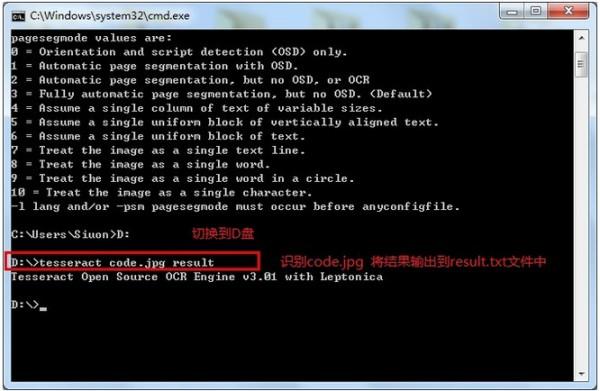
结果为:
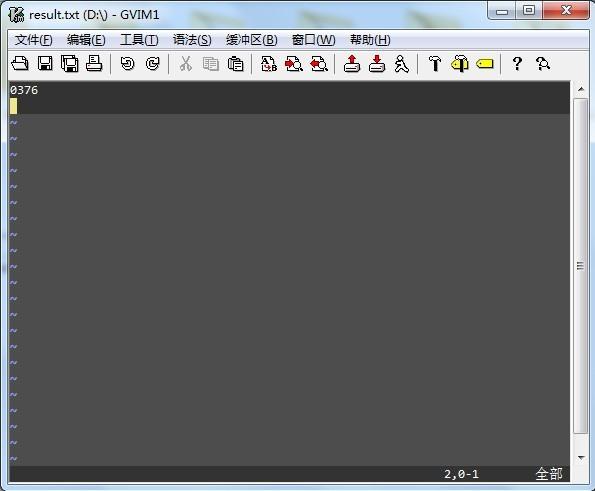
安装说明
1,下载的tesseract-OCR(注意3.0版本之后才支持中文的识别)
的tesseract-ocr- setup-3.00.exe
chi_sim.traineddata.gz
2,安装tesseract-ocr
解压缩,双击tesseract-ocr-setup-3.00.exe即可根据提示一步步安装,本人安装的目录是:D:/ Program
Files / Tesseract -OCR
在此目录下可看到tesseract.exe文件,这就是我们后面的程序中会调用到的运行进程
3,自定义安装语言包
D:/ Program Files / Tesseract-OCR目录下找到/ tessdata目录,其中包括:
chai_sim.traineddata.gz解压缩之后的chi_sim.traineddata文件复制到该目录下即可
4,编写测试代码
在编写代码之前下载两个jar包:jai_imageio-1.1- alpha.jar,swingx-1.0.jar,可在www.findjar.com












 西门子触摸屏编程软件
西门子触摸屏编程软件 Airtest1.2.6 官方版
Airtest1.2.6 官方版 Beautiful Soup下载
Beautiful Soup下载 understand 破解版下载
understand 破解版下载 gcc编译器windows安装
gcc编译器windows安装 JSON Viewer下载
JSON Viewer下载 Structured Storage Viewer下载
Structured Storage Viewer下载 markdownpad2破解版
markdownpad2破解版 Kate下载
Kate下载 IDEA中文版
IDEA中文版