直观一点的cwnd变化可以参考这张图:

关于tcp拥塞控制的详细解释可参考RFC5681。
云上客户反馈业务在同样以4.14内核作为server时,比用3.10内核上作client的延时要比4.14内核明显高出25%左右。
3.10内核 client测试,平均延迟57ms。
4.14内核 client测试,平均延迟44ms。
Server端:
内核在收包时,有一种把分片重组放到网卡里的机制叫做GRO(Generic Receive Offload),会将小包合成大包再传递给协议栈处理。
(本篇将会重点解析client行为,关于server端的详细分析,请期待下回分解)
Client端:
3.10版内核和4.14版内核在收ack时默认的拥塞控制算法cubic上,对cwnd的更新策略上有差别: 3.10是常规理解的ack收到的频率低,则窗口更新就更不积极,因此如果server开了gro,server端由于合包,ack回包频率就会变小,于是client窗口就增长的比较慢,导致表现为发包延迟;
而4.14的cubic算法修改了这个策略,让发包频率和收包频率来共同主导发送窗口的调整,尤其是针对对端有GRO开启等场景做了专门的优化,从而修复了这个问题。
方法上来讲,可以分别从Server端和Client端的调整解决此问题。
Server端:
关闭gro虽然小包可以提升传输速率,但是大包可能会造成更多的协议栈处理负载。
如果业务大部分场景都是小包小带宽的数据传输,可以先考虑关闭gro。作为临时快速的解决方案。而长线方案是慢慢灰度升高版本内核。
命令ethtool -K eth1 gro off。
Client端:
在TencentOS(腾讯自研内核)上,/proc/sys/net/ipv4/tcp_init_cwnd这个参数可以控制初始cwnd的大小,这个参数默认设置是10,是作为慢启动防止拥塞导致的网络性能下降,而如果是内网环境,大多是没有拥塞的,cwnd调大一些一般风险不大。
因此在本case中,可以调整到100,这样无论4.14还是3.10都有优化效果。且从流量来看,不会对内网造成较大影响。
命令echo 100 > /proc/sys/net/ipv4/tcp_init_cwnd (然后写到/etc/sysctl.conf)。
在业务测试后,最终使用client端修改cwnd的方案。
首先我们要了解的是问题现象,复现条件与一些已知的线索。
根据经验,首先尝试了server端关闭gro,再对比测试,结果发现关闭后3.10 client的延时确实有比较明显的下降,4.14 client无影响。
但是我们需要进一步搞清楚这里头的原因和逻辑,来确认最后是否能真的要靠关闭gro解决(gro本身是个优化,而且正如前面所说,所以直接关闭gro听起来也并不是一个最优解。而且gro理论上影响最终收包的大小、收包数量,进而影响回包的数量等等,我们现在也不知道具体是哪个因子导致的问题,关了gro会不会按了葫芦起了瓢?),是否会有更合理、更可控、影响范围更小的的解决方案。
网络问题,一开始分析肯定是要抓包,而针对云上机器,我们也要同时进行虚拟机和宿主机两个层面的抓包。因为宿主机抓包可以确认问题出在哪个层面(是网络链路慢,还是虚拟机收包慢,还是虚拟机收到包后处理慢)。
因此我们先针对server端(gro on/off的情况下)、3.10 client端进行抓包,来一步步聚焦问题:
这里通过wireshark分析analyze tcp的一些相关数据(此处省略截图),得到结论:
对比下来,不管开还是不开GRO, 宿主机发给虚拟机的包,最大大小都一致,两种情况下抓到的包的上限速度(见Average Throughput)是一致的。
同时这里从宿主句抓到的实际包上看到了子机是否打开GRO,包量都是一样的,说明发给虚拟机的包都是宿主机分好的。因此判断宿主机上server侧收包路径行为是一致的。那么到此基本可以判断问题出在虚拟机里。
从子机层面的tcp行为来看,两种情况下抓到的包的传输通量也是一致的。
但是在这个过程中有发现,gro on的情况下有的stream rtt有个突然增大10ms左右的过程,然后进一步测试了10+次,发现抖动不是那么稳定,也就是这只是延迟的一个表现,即使在rtt没有抖动的情况下,延迟也是依然存在的。从而也不是这里的原因。
为了方便定位,在沟通后,客户业务侧研发搞了单请求的测试程序,这样便于观察一次连接的差异,修改后看到gro on的情况下有时延时甚至能飙到100ms,而gro off的情况下,还是稳定的40ms。
后续再一起抓包分析,发现在gro on的情况下server虚拟机回包是要少很多的,而且一来一回的情况比较多。而母机没有这个情况,且通量和rtt仍然是几乎表现一致(和第一次抓包分析的结果一样)。
但是发现,client端在gro on的情况下,可以看到发送窗口大小在达到顶峰后是有掉回的:
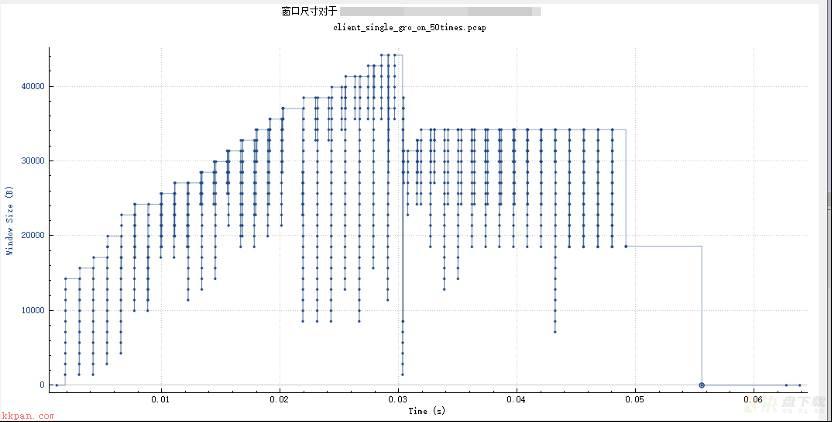
而在gro off的情况下则是一路增长到顶峰:

因此经过这次单连接的分析来看,对比差异最明显的一次连接,数据很清晰。gro on发送窗口最大40k左右(之后有受限再掉回来),完整传输完毕62ms(server端大概接收到11个包,延迟1ms才回一次ack,拥塞窗口增长较慢)。而gro off发送窗口可以达到80k以上,完整传输完毕44ms。
而又由于,4.14的client没有问题,而3.10的client有问题,我们推测,可能是client端的拥塞控制算法的差异导致3.10在gro on时,server会 delayed ack包的情况下,有延时或者回复的ack包量太少而导致client的发送窗口上不去。
为了验证我们的推测,我们先用iperf做了一下测试,但是结果是却是在gro on/off没有任何差异,但是这并不能直接否认我们的推测,因为能影响网络表现的因素实在是太多了,比如可能是因为压测包大小本身比较大?有可能是压测情况下ack回包频率高到一定程度后对cwnd就没有影响了?有可能是gro在压测情况下的对小包重组对整个的通量影响微乎其微?所以iperf测试表现也并不能说就推翻我们对拥塞控制算法上的怀疑,因此我们还是要进一步深挖细节,找出这一系列现象的前因后果。
在静态的代码分析上,正如在开头的结论中提到的,我们最终的目标是解决问题,找到合适的优化策略,并且我们需要能有正确的理论依据支持我们的优化策略,而不是瞎猫碰到死耗子(这样给出的方案也没有说服力),因此我们也是两条腿走路:
在server端,由于gro的行为导致延迟(合包导致包量少),需要分析代码找到gro的延迟和合包逻辑是什么,进一步分析有什么办法优化;在client端,server的延迟(回包少)影响了client的cwnd增长,为什么有延迟(回包少)会对cwnd有影响,需要了解拥塞控制算法上面可能存在的差异,进而分析有什么办法优化。
在本篇中,将讲述我们在client端针对拥塞控制方法所进行的一系列分析,而server端的分析将会留到下回分解,下面正片中的正片即将开始。
在分析代码前,需要先了解,内核对于每一个socket buffer,都是由一个sk_buff结构体来表示的,而对于各个协议栈,则会有相应的数据结构直接对sk_buff进行转化。
对于TCP协议,对应的sk_buff就是tcp_sock,而收ack包的入口是tcp_ack函数,这里我们也不详细分析ack收包流程,而是聚焦于可能修改cwnd的地方。


分析内核代码知道,cwnd在内核数据结构里的表示是体现在tcp_sock->snd_cwnd(注释Sending congestion window写的明明白白):

内核分析,如果只靠走读代码,好比大海捞针,不仅容易抓不到点,不知道自己看到哪了,更无法知道自己看到的东西和自己的理解是否正确。因为client这里比较明确的推测大概率是cwnd的问题,我们先用动态的方法来验证我们的推测是否正确,然后再进一步走读代码。
我们先通过stap脚本,抓取3.10内核 client端在收ack时的cwnd变化,来验证之前观察到的server回ack少时,是不是导致client的窗口大小上不去。由于这里是直接抓取内核skb结构体的内存,粒度也是比wireshark分析来的要细也更直接。
附上stap脚本:

gro on时抓取结果:

gro off时抓取结果:

可以看到,在几乎同样的timestamp时,gro on时cwnd确实是要小的,这也是符合正常逻辑处理的,回包慢(频率小)导致对端认为通量不够,进而增大窗口不积极、上限低。
到这里,其实从解决方案上来讲,已经能给出开篇时的结论,调大cwnd来测试,观察是否可行。
但是原理上我们还没弄清楚,还没有足够的理论支撑来支持我们的解决方案,所以还需要继续深挖,现在问题的疑点就在,为什么4.14在这种情况下,依然能保持窗口的正常增长,而3.10不行。
因此我们来聚焦分析两个不同内核版本tcp_ack的细节差异,分析为什么4.14拥塞控制算法在开gro导致收ack少时也能调整cwnd到一个比较大的水平。
由于我们需要重点关注拥塞控制部分,先简单介绍一下内核里tcp拥塞控制算法是如何调用的。
机器支持的拥塞控制算法和当前使用的拥塞控制算法,可以通过这些内核参数查看:

一般来讲,默认使用的算法都是cubic算法。
而这个cubic算法,是在内核代码的net/ipv4/tcp_cubic.c里实现的,通过内核模块的方式插入到内核中, 并通过内核协议栈提供的注册拥塞控制算法的方式将自己注册:

可以看到,注册的就是一组cubic调用接口,这样在tcp协议栈需要调用时就通过指针的方式调用( )。

而我们需要关注的主要就是cong_avoid方法,对应的是bictcp_cong_avoid(关于这个函数的部分相关细节,后面也会分别分析)。
清楚了以上知识,我们先看下3.10,重点关注拥塞控制的部分:

而对于4.14,这里整个代码的逻辑都不一样了:

注意到,4.14这里的代码逻辑和3.10完全不同,甚至tcp_cong_avoid都被封装到了tcp_cong_control里。




回到正轨,继续看tcp_cong_control这个函数, 从名字就能看出,慢启动在需要增大cwnd时,会进入tcp_cong_avoid,进而调用对应拥塞控制算法的cong_avoid方法(这里就是cubic)。
3.10的bictcp_cong_avoid:

4.14的bictcp_cong_avoid:

可以看到,最显著的差距,就是引入了这个acked参数,接下来来分析看看这个acked是干什么的,先看下tcp_slow_start:

注意到注释里写的“handle stretch ACKs properly”以及可以防御ack攻击,3.10里头是没有这个功能的,而ack攻击和stretch ack正是和ack的频率有关,好像又抓到线索了?
从这里的代码来看,在慢启动的大部分情况(没到ssthresh之前),这个acked进来什么值出去什么值,而snd_cwnd是会被调大。
然后是bictcp_update,这个函数是用来进一步计算cwnd的,具体的算法比较复杂,有兴趣的可以参考cubic的论文:
https://www.cs.princeton.edu/courses/archive/fall16/cos561/papers/Cubic08.pdf
我们只关注到里面对于这个acked参数,最大的调整是:

这样无疑会对cwnd的算法造成一些改动。
继续来看tcp_cong_avoid_ai:

可以看到acked影响snd_cwnd_cnt(进入下面那个if的情况就是指数增长)。
那么分析了这么半天,传进来的这个acked是什么? 再回到tcp_ack中:

再看这个delivered代表什么:

delivered代表着送达的包,包括重传的。但是这里是计算差值,在慢启动的情况下,绝大多数情况应该都为1或以上,对cwnd的计算是有积极影响,且不会受ack频率影响。
而3.10的对应参数,则是计算了还有多少个发送中未收到的包:


但是这个in_flight,在进入cubic后并不会影响cong_avoid和tcp_slow_start(之前的差异里已经分析过):

因此无论如何,可以确认新内核引入的这个改动,对我们当前的场景是有优化作用的。
根据以上的改动,按图索骥从主线里找到了对应的commit。


看注释,已经很明确的说明了,这个提交就是为了修复GRO等带来的delayed ack会导致对每个包ack一来一回,而导致的性能下降的问题。
贴一下里面bictcp_update的改动(就不全贴了),正是我们刚才分析过的,加入了acked参数:

基本到这里,已经八九不离十的确定,就是这块改动修复的这个问题。
最后一步,就是再针对这块代码,做动态的实践验证,来确认我们的结论是正确的。
这个实验目的是为了证明3.10和4.14的差异确实在我们刚才分析到的地方。
首先我们配置三台机器,一台server内核是4.14,两台client内核是3.10。
然后我们编写了server端和client端的测试程序,就是socket连接收发包,client端发送本地文件,通过定制本地文件来模拟不同的发包情况,而server端则做本次连接的总计耗时、每次read收包平均耗时统计(不直接用iperf的原因想必可以通过前文的分析找到答案)。
附上测试程序,该程序原版出自zorro大佬之手:
server.c:
#include <sys/types.h>
#include <sys/socket.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <arpa/inet.h>
#define BUFSIZE 4096
int main(void)
{
int sfd, afd, clilen, size;
struct sockaddr_in addr, cliaddr;
char buf[BUFSIZE];
char addrstr[INET_ADDRSTRLEN];
struct timeval start, end, st, ed;
long delta, count, total;
sfd = socket(AF_INET, SOCK_STREAM, 0);
if (sfd < 0) {
perror("socket()");
exit(1);
}
static int val = 1;
if (setsockopt(sfd, SOL_SOCKET, SO_REUSEADDR, &val, sizeof(val)) < 0) {
perror("setsockopt()");
exit(1);
}
bzero(&addr, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(8888);
if (inet_pton(AF_INET, "0.0.0.0", &addr.sin_addr) <= 0) {
perror("inet_pton()");
exit(1);
}
if (bind(sfd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
perror("bind()");
exit(1);
}
if (listen(sfd, 10) < 0) {
perror("listen()");
exit(1);
}
clilen = sizeof(cliaddr);
while (1) {
count = 0;
total = 0;
afd = accept(sfd, (struct sockaddr *)&cliaddr, &clilen);
if (afd < 0) {
perror("accept()");
exit(1);
}
gettimeofday(&st, NULL);
bzero(buf, BUFSIZE);
if (inet_ntop(AF_INET, &cliaddr.sin_addr, addrstr, INET_ADDRSTRLEN) == NULL) {
perror("inet_ntop()");
exit(1);
}
while (1) {
gettimeofday(&start, NULL);
size = read(afd, buf, BUFSIZE);
if (size <= 0) {
break;
}
gettimeofday(&end, NULL);
delta = (end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec);
//printf("%ld
", delta);
count ++;
total += delta;
/*
if (write(1, buf, size) < 0) {
perror("write()");
exit(1);
}
*/
//printf("delta:%ld, size:%d
", delta, size);
}
gettimeofday(&ed, NULL);
delta = (ed.tv_sec - st.tv_sec) * 1000000 + (ed.tv_usec - st.tv_usec);
printf("avg:%ld us, count: %ld, total: %ld us
", total/count, count, delta);
/*
sprintf(buf, "IPaddr: %s, Port: %d, clilen: %d
", addrstr, ntohs(cliaddr.sin_port), clilen);
if (write(afd, buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
*/
close(afd);
}
close(sfd);
exit(0);
}client.c:
#include <sys/types.h>
#include <sys/socket.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <netinet/in.h>
#include <netinet/ip.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define PATH "./file"
#define BUFSIZE 4096
int main(void)
{
int sfd, afd, clilen, ret, fd, size, count;
struct sockaddr_in addr, cliaddr;
char buf[BUFSIZE];
char addrstr[INET_ADDRSTRLEN];
fd = open(PATH, O_RDONLY);
if (fd < 0) {
perror("open()");
exit(1);
}
sfd = socket(AF_INET, SOCK_STREAM, 0);
if (sfd < 0) {
perror("socket()");
exit(1);
}
bzero(&addr, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(8888);
if (inet_pton(AF_INET, "42.193.204.131", &addr.sin_addr) <= 0) {
perror("inet_pton()");
exit(1);
}
if (connect(sfd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
perror("connect()");
exit(1);
}
while ((size = read(fd, buf, BUFSIZE)) > 0) {
ret = write(sfd, buf, size);
if (ret < 0) {
perror("write()");
exit(1);
}
}
/*
ret = read(sfd, buf, BUFSIZ);
if (ret < 0) {
perror("read()");
exit(1);
}
ret = write(1, buf, ret);
if (ret < 0) {
perror("write()");
exit(1);
}
*/
close(sfd);
close(fd);
exit(0);
}我们分别以128和32大小的包,发送4096次(因为业务场景也是小包多发,因此我们选了这种可能比较典型的场景),对应server端gro on/off的情况。
先看3.10作为client时:


可以看到,虽然没有业务表现的那么明显,但就我们自己的测试程序测出来来看,on确实也是比off耗时平均要稍多一丢丢。
而换做4.14 作为client:


可以看到gro on的耗时明显比off要低很多了。
下面开始最关键的表演,想必前面的伎俩通过stap抓取内核函数参数各位客官也看腻了(虽然根据之前的分析,抓取acked和in_flight的值也可以印证我们之前的分析,但还是没办法做到直接的数据对比来实锤),想看点新花样,因此我们现在来点更直接的操作,通过修改4.14的内核代码,把之前分析过的acked参数去掉,重新编译内核,来看看问题表现会不会跟3.10一样或者接近(因为两个版本的tcp协议栈差异确实也比较大,很难说是就完全回归3.10的表现,我们只是要确认,这个修复确实针对此情此景是有优化作用即可)。
根据commit修改代码,为了保险起见如果改动太大也无法验证问题,我们只修改upstream的这两个commit(前面也贴图了):
9cd981dcf174d26805a032aefa791436da709bee
e73ebb0881ea5534ce606c1d71b4ac44db5c6930
改动(commit里的图,我们的修改+-是相反的):
delayed ack相关:


acked变为原来的+1;


slow_start改回原来的模样;

acked改为原来的+1

注意这里我们并没有像3.10一样把delivered改成in_flight,因为正如前面分析的in_flight即便传进来也对后面这几个函数没有影响,我们要把改动的影响面降到最小,仅仅确定acked这个参数的引入对算法的影响即可。
然后编译、安装内核。
现在万事具备,就来最后一把测试:
包大小为128时:

果不其然,这里出现了gro off更快的现象。而且关键点是,对比修改之前,on是要慢了很多(之前是11左右),这也可以直接说明了该修改确实针对gro on的情况是有显著优化效果的,而不完全算是一个通用的优化。
这里在插一个抓包看到的窗口对比,更直观些:
修改后gro on慢下来的抓包窗口:


至于off也比之前快了一些,这个原因尚不明确,可能是我们的改动影响了其他什么机制,但他毕竟还是没有改之前的on快(不然这随手一改就实现了一个tcp的优化岂不是太离谱儿了),所以也同时说明了这个commit的优化对整体tcp的性能是有改善的(毕竟我们默认都是gro on,gro本身就是一个优化机制,通过gro off才能优化这种现象本来也说不过去)。
再看下包大小为32时:

可以看到,虽然两者差异并不明显,但也没有之前gro on明显要快的现象了。
综合上述实验结果,我们的理论也得到了完美的支撑。到这里,client侧的分析,也终于是理论结合实践全方面分析到位了。
原创声明,本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。