处理非字典类型数据csv文件的读写,首先需要python导入csv库。利用delimiter完成该需求。
delimiter 用于分隔字段的单字符,默认为 ','
import csv
datas = [[1, 2, 3], ['纪', '宇'], ['xxx', 'yyy', 'zzz'], '字符串']
# 写
with open('test.csv', 'w+', newline='') as fr:
writer = csv.writer(fr, delimiter='|')
for data in datas:
writer.writerow(data)
# 读
with open('test.csv', 'r') as fw:
reader = csv.reader(fw)
for row in reader:
print(row)

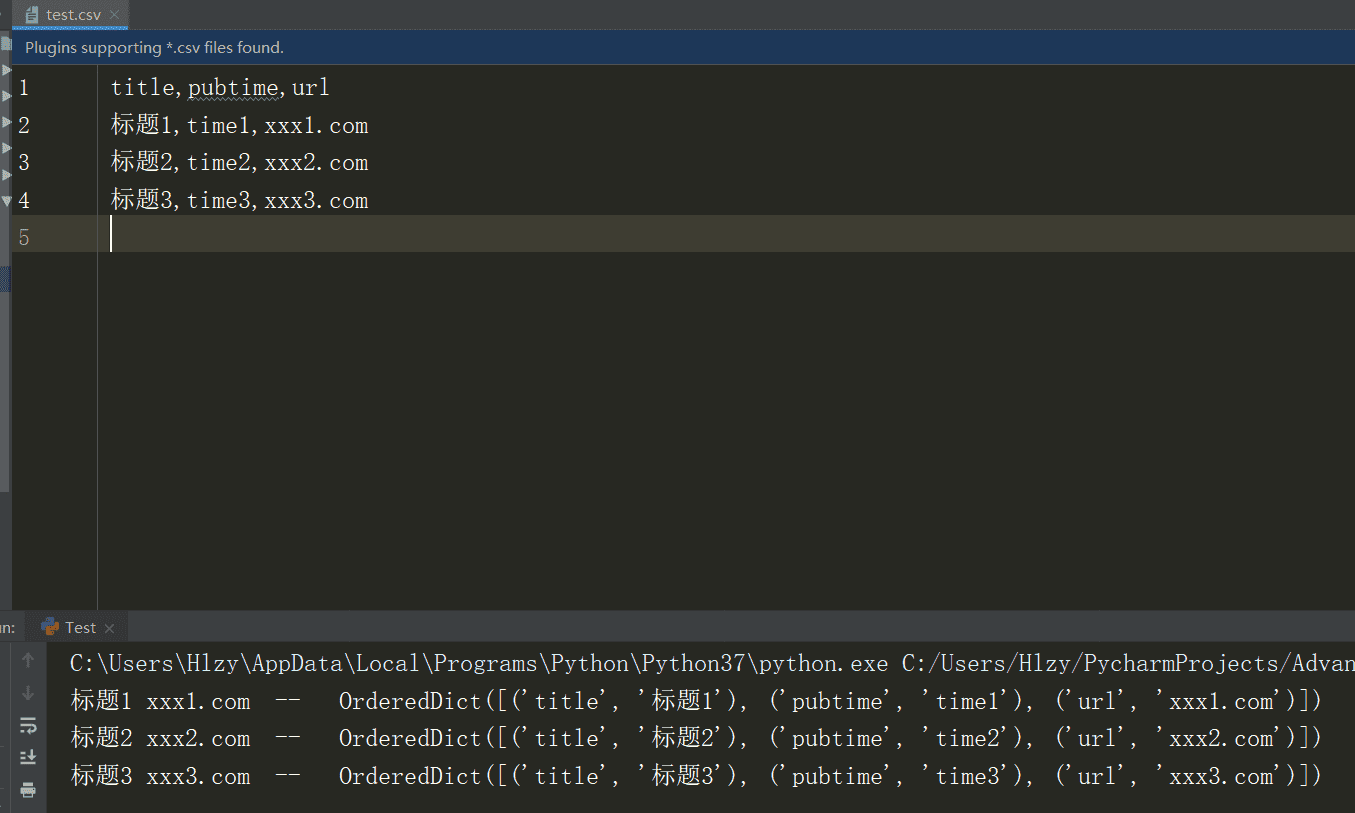
fieldnames 参数 指定字典中值的顺序,csv文件中,第一行数据为键 extrasaction 参数 如果传递给 writerow() 方法的字典的某些键在 fieldnames 中找不到 其设置默认值 'raise',会引发 ValueError 如果将其设置为 'ignore',则字典中的其他键值将被忽略 writeheader() 写入一行字段名称,fieldnames 参数的值 不写入键,则会以第一行的数据作为默认字段
import csv
datas = [
{'title': '标题1', 'url': 'xxx1.com', 'pubtime': 'time1', 'author': '作者1'},
{'title': '标题2', 'url': 'xxx2.com', 'pubtime': 'time2', 'author': '作者2'},
{'title': '标题3', 'url': 'xxx3.com', 'pubtime': 'time3', 'author': '作者3'},
]
# 写
with open('test.csv', 'w+', newline='', encoding='utf-8') as fr:
# 设置字段
fieldnames = ['title', 'pubtime', 'url']
writer = csv.DictWriter(fr, fieldnames=fieldnames, extrasaction='ignore')
# 写入第一行的字段
writer.writeheader()
for data in datas:
writer.writerow(data)
# 读
with open('test.csv', 'r', encoding='utf-8') as fw:
reader = csv.DictReader(fw)
for row in reader:
# 返回的行是dict类型
print(row['title'], row['url'], ' -- ', row)