") u=2763237160,4292423252&fm=26&gp=0.jpg
今天就介绍beautiful soup哦,下次再更新PyQuery的用法
Request、Beautiful Soup、PyQuery的用法
u=2763237160,4292423252&fm=26&gp=0.jpg
今天就介绍beautiful soup哦,下次再更新PyQuery的用法
Request、Beautiful Soup、PyQuery的用法
在前面的教程中我们已经讲解了正则表达式的使用,但是相对于我们来说还是有些麻烦,一不小心就会出错;在python中我们可以使用一个更加强大的工具,使用它我们可以快速从HTML和XML标签中提取我们想要的内容。
一、Beautiful Soup的简介与安装Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的功能.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
二、Beautiful Soup 安装Beautiful Soup 3目前已经停止开发,推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 import bs4。所以这里我们用的版本是Beautiful Soup 4.4.0(简称BS4),另外据说BS4对Python3的支持不够好,不过我用的是Python2.7.7,如果有小伙伴用的是Python3版本,可以考虑下载BS3版本。
我们可以使用pip或easy_install来安装Beautiful Soup库:
easy_install beautifulsoup4
pip install beautifulsoup4 # 在Python3中安装 pi3 install beautifulsoup4
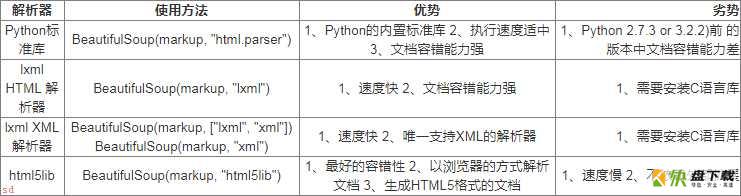
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是lxml.根据操作系统不同,可以选择下列方法来安装lxml:
apt-get install Python-lxml easy_install lxml pip install lxml # python3版本 pip3 install lxml
另一个可供选择的解析器是纯Python实现的html5lib, html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
apt-get install Python-html5lib easy_install html5lib pip install html5lib pip3 install html5lib
 在这里插入图片描述
在这里插入图片描述
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定。
三、开始使用Beautiful Soup由于Beautiful Soup文档的内容比较多,我们只整理一些常用的用法,更多可以参考Beautiful Soup官方文档
1、创建Beautiful Soup对象使用BeautifulSoup前需要引入bs4库,我们仅需要将一段文档传入BeautifulSoup的构造器,就能得到一个文档的对象,;同时我们也可以传入一段字符串或者一个文件。
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html>data</html>")
首先,文档被转换成Unicode,并且HTML的实例都被转换成Unicode编码
soup = BeautifulSoup("spider test")
print(soup)
# <html><body><p>spider test</p></body></html>
然后,Beautiful Soup会选择最合适的解析器来解析这段文档,如果手动指定解析器那么Beautiful Soup会选择指定的解析器来解析文档。
2、四大对象种类Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag
NavigableString
BeautifulSoup
Comment
下面我们进行一一介绍
(1)、Tag
Tag对象与XML或HTML原生文档中的tag相同,我们可以理解为Html中的标签:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>
从上面的Demo可以看到其实b就是一个Tag,我们可以快速使用BeautifulSoup来获取tag:
# 快速提取a标签 a = soup.a # 快速提取p标签 p = soup.p # 快速提取img标签 img = soup.img # 快速提取title标签 title = soup.title # 快速提取head标签 head = soup.head # 快速提取div标签 div = soup.div
Tag有很多方法和属性,其中最重要的属性: name和attributes
(2)、name
每个tag都有自己的名字,通过.name来获取:
print soup.name print soup.head.name
(3)、attrs
一个tag可能有很多个属性,你可以使用如下两种方法获取。
tag['class'] tag.attrs
如果你想获取一个标签的多值属性,你可以使用如下方法获取所有的p的class
print soup.p['class'] # ["body", "strikeout"]
除了上面的方法,你还可以使用get方法获取
print soup.p.get('class')
# ["body", "strikeout"]
修改tag的名称和属性
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
tag.name = "blockquote"
tag['class'] = 'verybold'
tag['id'] = 1
tag
# <blockquote class="verybold" id="1">Extremely bold</blockquote>
del tag['class']
del tag['id']
tag
# <blockquote>Extremely bold</blockquote>
2019Python自学教程全新升级为《Python+数据分析+机器学习》,九大阶段能力逐级提升,打造技能更全面的全栈工程师。python学习资料获取方式
1.右上角点击关注2.评论区任意评论或者转发一下
3.做完1、2步,然后私信我回复“资料”哦
 在这里插入图片描述
在这里插入图片描述 
【Python实现网络爬虫】Scrapy爬取网易新闻(仅供学习交流使用!)