业务应用层是整个系统流量枢纽,核心业务存在单点或者自愈能力弱,都会造成严重影响业务稳定性。例如,核心业务模块和非核心业务模块高度耦合,从资源成本上来考虑,实际上并不是所有业务均需要做容灾建设,需要加入人力成本对业务进行改造;如果对于延时敏感业务,无法接受跨区延时,需要投入更多人力来进行架构和业务上改造。综上所述,本文从云平台视角出发阐述应用层业务容灾建设,主要分为方案设计考虑纬度、复杂度以及云上客户案例三个方面。
应用层调用链是否能接受跨区延时,如果业务无法接受跨区,该业务做容灾只能set化部署,这里需要强大中间件团队开发数据同步系统。
应用层调用链能接受跨区延时,一般以试点业务先观察,小步迭代方式逐步构建容灾能力。从经验来讲,业务方提供能容忍精确延时较为困难,业务形态只有数据入库时候可能存在跨区情况,这里有两点建议:
1)应用内部调用链式流量是烟囱式的,在同一个可用区内完成。
2)应用层数据读写,最多能接受跨区写,就近读的模式。
应用在不同可用区部署规模?应用层能接受跨区延时,但是接受程度,云上客户业务各有差别。
1)业务完全能接受跨区延时,不同的可用区应用部署规模(1:1),各承载50%的业务流量;
2)业务并不能完全接受跨区延时,为了容灾做业务做了部分妥协,两个可用区业务部署的规模(5:1),主要业务承载在主可用区,保证大部分流量没有跨区访问,少部分流量只是做热备,故障时候,进行临时扩容来恢复业务。特别注意这类业务对业务快速扩容和资源储备有要求。
错综复杂业务应用从哪里入手?将所有业务通盘来梳理不仅仅耗费大量人力,同时可能还会有遗漏;建议这里有几个原则:从已知到未知,从简单到复杂,从灰度到全量的迭代有效梳理业务。
应用调度分为南北和东西向流量调度。这里主要考虑如果业务异常,如何快速的调度来恢复业务。
南北向流量。1)接入层流量,来自于CLB/nignix/ingress等。接入层负载均衡或者nignix流量通过443/80端口将流量引入到应用层。
2)中间层流量,redis/ckafka/es等。通常情况,应用层将生成数据通过DNS/注册中心寻找到相应的中间件,将数据写入或者读取。
3)数据侧流量,数据库mysql/tdsql等。通常情况,应用层将生成数据通过dns/注册中心寻找到相应的中间件,将数据写入或者读取。
东西向流量。主要是应用之间调用链。通常应用层之间调用通过api网关/内网dns/注册中心来进行相互调用。
系统稳定性。主要是调度系统和配置系统稳定性。容灾切换强依赖于调度系统以及配置系统稳定性。这里稳定性主要包括系统容灾能力和性能;遇到大规模故障,大量信息配置变更请求调度系统和配置系统要能扛住洪峰,是保障这个容灾方案的根基。
计算应用层容灾,主要考虑以下两个方面:
哪些节点执行任务。这里要区分清楚哪些节点执行核心业务,这里会引入不同的复杂度。例如:
第一类场景:应用层业务承载在单台机器上,如果机器异常,直接会影响业务,业务恢复强依赖于机器恢复能力。
第二类场景:应用层业务承载在多台机器上,来减少对机器强依赖;因此增加负载均衡集群,通过健康检查来实时感知机器情况。但是增加负载均衡稳定性复杂度,业务恢复强依赖负载均衡稳定性。
第三类场景:为了提升应用层业务水平扩容能力,同时减少对负载均衡集群依赖,应用层采用双可用区部署来进一步提升业务稳定性。
——业务应用层容灾建设")
通常情况有两种:应用层任务执行异常,重新发起请求;如果有任务管理器,将失败队列任务重新发起。
不同处理方式会影响业务异常恢复方案。如果是重新发起,并不需要特殊处理,如果任务管理器,需要通过重新发任务来恢复。
应用层调用链应该在同一个可用区完成,尽量避免跨可用区调用情况,对于数据库进行单写,就近读。
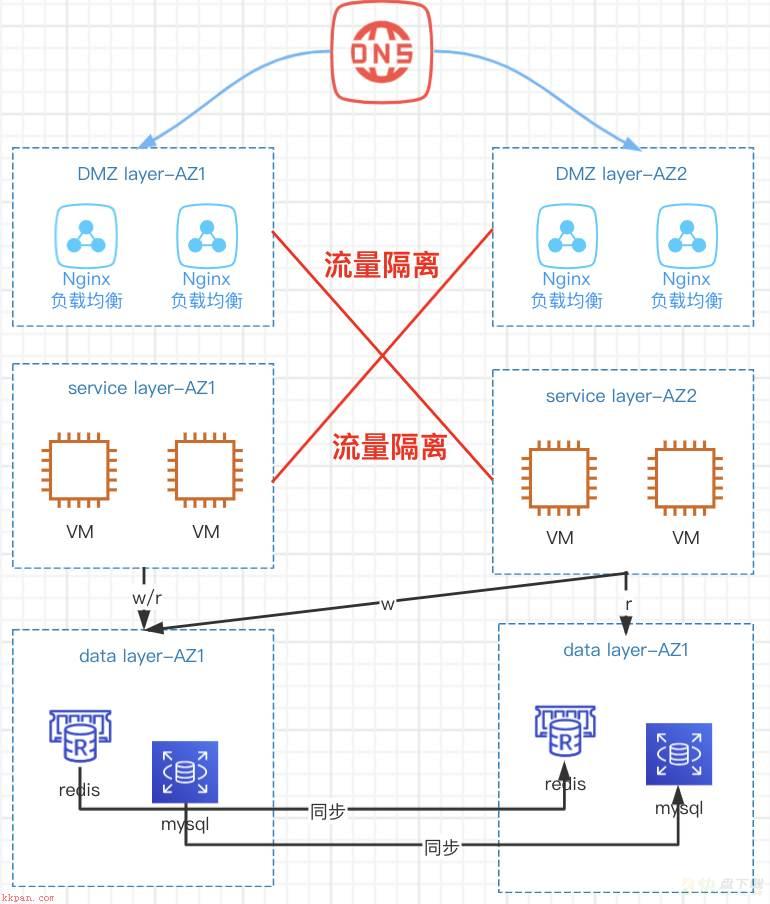
应用层调用链应该在同一个可用区完成;不同地域之间流量仅仅做来同步数据。如下面场景:
1)资源部署:多个游戏服务在广州/上海两地各建一套,不同游戏服务通过dns解析到不同地域。
2)业务流量:通常,单个游戏服务流量在单个地域承载,另外一个地域为冷备。
3)数据读写:数据库redis/cdb读写均在单个区,地域间数据库进行双向同步。当前腾讯云dts已经支持mysql双向同步功能,详情见https://cloud.tencent.com/document/product/571/59386。
ps:腾讯云redis双向同步功能预计11月上线,请大家再等等。

阿里云服务器(Windows)磁盘空间不足时如何释放磁盘空间?