微信公众号:DBA随笔
MongoDB的Change Stream有点类似关系型数据库中的触发器,但是原理不完全相同。
关系型数据库中的触发器动作和当前操作是在同一个事务里面完成的,而Change Stream是异步完成的,二者的区别如下:

Change Stream是基于Oplog实现的,它在Oplog上开启一个tailable的游标来追踪所有副本集上的变更操作,类似linux操作系统中最常用的tail -f file.txt命令,持续输出这个文件后面追加的内容,最终调用应用中定义的回调函数来完成后续逻辑。
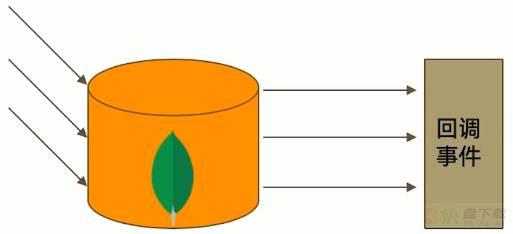
可以被追踪的变更事件主要包括:
insert、update、delete、drop、rename、dropDatabase
除此之外,还支持invalidate事件,当drop、rename、dropDatabase等命令执行完毕后,集合本身可能已经发生了变化,将导致invalidate事件被触发,change stream被关闭,这个其实也容易理解,类似文件被删除了,那么tail -f file.txt的命令也就不会输出了。
使用限制
Change Stream只推送在大多数节点上提交的变更操作,也就是'可重复读'的变更,这一特点是通过{readConcern:"majority"}来实现的,因此,使用起来有2个限制:
1、未开启majority readConcern的集群无法使用Change Stream;
2、当集群无法满足{w:"majority"}时候,不会触发Change Stream
3、其次,由于Change Stream依赖Oplog,因此中断时间不可以超过oplog的最大时间窗
4、执行更新的时候,Change Stream只显示更新字段;执行删除的时候,只包含数据记录的_id字段
应用场景
跨集群的变更复制:类似订阅处理,订阅Change Stream,一旦源集群发生变更,立马更新到目标集群中;
微服务联动:当一个服务变更数据库的时候,其他服务得到通知并做出相应变更。类似触发器。
其他系统联动场景。
这里,我们通过一个小的例子,来开启了解Change Stream。
如下,开启两个Mongo Shell来连接MongoDB:
Shell 1:
这个Shell中,我们使用Watch方法来监听这个aaa的集合的内容
test1:PRIMARY> db.aaa.watch([],{maxAwaitTimeMS:3000000}).pretty()
其中,中括号[ ]代表不对这个集合的操作类型做过滤,当然我们也可以过滤这个集合的某些类型的操作,例如可以写成下面这样过滤insert和update:
test1:PRIMARY> db.aaa.watch([
$match:{
operationType:{
$in : ['insert','update']
}
}
],
{
maxAwaitTimeMS:3000000
}).pretty()
maxAwaitTimeMS代表最长的等待时间
Shell 2:
Shell 2中我们插入相关数据记录
test1:PRIMARY> db.aaa.insert({"name":"杨过"});
WriteResult({ "nInserted" : 1 })
test1:PRIMARY> db.aaa.update({"name":"zhangsan"},{$set:{"name":'郭靖'}});
WriteResult({ "nMatched" : 0, "nUpserted" : 0, "nModified" : 0 })
test1:PRIMARY> db.aaa.update({"name":"杨过"},{$set:{"name":'郭靖'}});
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
先插入一个name=杨过的记录,
然后修改name=zhangsan的记录为郭靖(zhangsan这条记录并不存在);
修改name=杨过的记录为name=郭靖;
此时,我们发现Shell 1中输出下面的内容:
test1:PRIMARY> db.aaa.watch([],{maxAwaitTimeMS:3000000}).pretty()
{
"_id" : {
"_data" : "8261645BC0000000032B022C0100296E5A10047A8F06A25C2E477D994603CE3C12B3C346645F6964006461645BC40515DC253E3FE2120004"
},
"operationType" : "insert",
"clusterTime" : Timestamp(1633967040, 3),
"fullDocument" : {
"_id" : ObjectId("61645bc40515dc253e3fe212"),
"name" : "杨过"
},
"ns" : {
"db" : "yeyz",
"coll" : "aaa"
},
"documentKey" : {
"_id" : ObjectId("61645bc40515dc253e3fe212")
}
}
{ # 这里对应第3个语句
"_id" : {
"_data" : "8261645BDE000000032B022C0100296E5A10047A8F06A25C2E477D994603CE3C12B3C346645F6964006461645BC40515DC253E3FE2120004"
},
"operationType" : "update",
"clusterTime" : Timestamp(1633967070, 3),
"ns" : {
"db" : "yeyz",
"coll" : "aaa"
},
"documentKey" : {
"_id" : ObjectId("61645bc40515dc253e3fe212")
},
"updateDescription" : {
"updatedFields" : {
"name" : "郭靖"
},
"removedFields" : [ ]
}
}
从上面例子中可以看到,我们的shell 1监听的过程中,出现了2条记录:
第一条记录中的fullducument记录的是insert的文档内容,而第二条记录中的updateDescription中记录的是变更的字段。
Shell2中的db.aaa.update({"name":"zhangsan"},{$set:{"name":'郭靖'}})语句,由于记录不存在,所以没有出现在Change Stream的最终输出结果中。
故障恢复机制

假设我们在t0时刻我们的Change Stream所在的应用服务器宕机,已经接受了3条Change Stream的记录了,重启后,Change Stream支持断点重连。
具体的做法是,上述Change Stream输出结果中,有一个_id字段,内容类似{"_data" : "8261645BDE000000032B02xxxx"},这个_id可以作为Change Stream故障之后的断点重连位置,我们可以使用下面的语法来重新开启Change Stream,从而继续获取后续集合的变更。语法如下:
db.collection.watch([],{resumeAfter:<_id>}