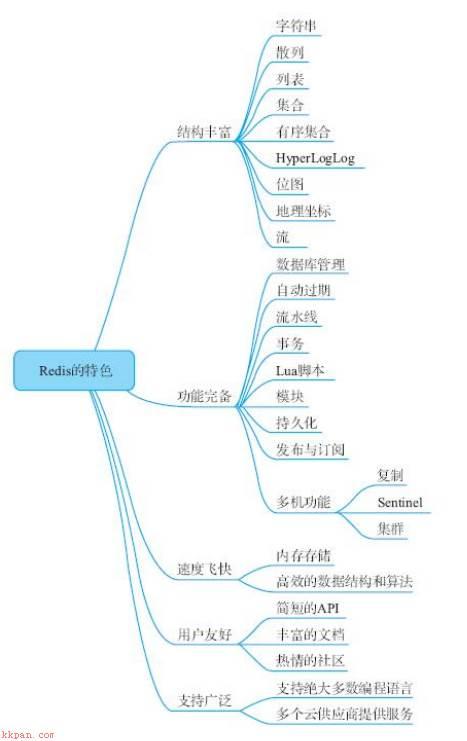
在Redis中,经常会遇到各种原因的阻塞,最终导致Redis超时。可以毫不夸张的说,阻塞,是使用Redis的噩梦,每个人都会遇到。
这里,我根据自己平时排查问题的经验,再结合一些理论知识,给出一个大体的排查思路,希望对大家有所帮助。
01
原理分析
从原理层面,我们可以将Redis阻塞的问题分为内因和外因,这里我们分别来看。
Redis自身问题---内因
1、持久化带来的阻塞问题(AOF重写和生成RDB)
Redis在做AOF重写或者生成RDB的时候,需要fork操作创建子进程,fork的过程,虽然不会直接拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表。
从经验上来讲,如果你的Redis有10GB的数据,那么会需要复制大概20MB的内存页表,正常情况下,fork耗时是每个GB消耗20ms的时间。如果在一个QPS是5w的Redis中,fork消耗1s,则拖慢大概5w的请求。这是非常严重的问题。
2、CPU使用饱和
如果把一个Redis的CPU跑到将近100%,这是非常危险的,判断CPU是否占用过高,我们可以简单使用下面2个方法:
a、top命令查看,这个最直接;
b、redis-cli --stat 命令,查看当前Redis每秒钟处理的命令个数,如果接近8~10w,说明当前Redis的压力特别大(这个判断不一定准确,如果你使用了高算法复杂度的命令,可能很小的QPS Redis就扛不住了)。
3、慢查询 或者 大key
Redis API或者数据结构使用不合理,经常会导致慢查询或者大key。
慢查询
如果我们对整个Redis执行了keys * 或者对一个大的hash结构执行了hgetall等命令,那么这个命令必然执行很慢。因为它的复杂度是O(n)
当我们执行Redis命令的时候,如果超过我们设定的慢查询阈值,就会被记录在Redis的慢查询里面,Redis的慢查询可以使用slowlog get n来查找,这里有一点需要注意:Redis的慢查询记录的是命令执行时间,而不包括数据网络传输时间和命令排队时间。常见的一个误区就是客户端阻塞之后,业务同学总觉得Redis慢,但是很有可能是在等待其他命令执行。
大key
大key的读取和写入需要更大的内存空间,因此很容易造成阻塞,通常情况下,我们可以使用redis自带的redis-cli --bigkeys命令来找到每个数据类型的大key,并进行处理。
外在问题---外因
1、CPU竞争或者 多CPU NUMA架构的跨内存访问
如果Redis所在的服务器有多个核心,部署了多个Redis实例,实例之间往往存在CPU竞争以及CPU的上下文切换,而这种竞争和上下文切换会降低Redis的性能。
这个时候,我们往往会通过绑定CPU核心的方法来减少CPU之间的竞争问题,这个处理方式正常情况下没有问题。但是当我们将Redis的持久化开启,Redis做bgsave或者AOF重写的时候,父子进程将产生CPU竞争,影响Redis稳定性。因此,在开启了持久化的Redis上,不建议绑定核心,而是应该去调整Redis的部署架构。
再说NUMA访问,如果在CPU多核场景下,Redis实例被频繁调度到不同CPU核上运行的话,那么就会出现内存的远端访问,远端访问的过程中,对Redis实例的请求处理时间影响就更大了。每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求。
2、使用了SWAP内存交换
如果操作系统的内存不够,将一部分内存数据换出到磁盘,那么Redis的访问无疑会受到影响,因为内存和磁盘的访问速度,差了好几个数量级。因此,使用Redis的机器上,尽量关闭swap,并设置Redis的maxmemory,避免Redis内存的无限制上涨。
3、网络问题
这个就非常常见了,网络抖动,网络闪断,网络延迟,网卡软中断等。这里给出查看网络延时的办法,通常情况下,可以使用redis-cli --latency命令来查看Redis的延迟情况。
02
个人排查习惯
先查外因:
1、网络层面是否有抖动;
物理层面是否有网络丢包:ifconfig查看Drop
网卡层面,查看是否被打满,网卡打满会导致严重的超时
2、服务器负载:查看CPU和Load是否有异常
3、Redis是不是使用了Swap空间。
再看内因:
4、Redis-Server 的慢查询,特别是简单命令中的大key情况(注意慢查询不包括排队等待的时间);
5、超时的时刻是否由AOF重写或者Bgsave操作;Redis 在持续高写入的时候,开了AOF功能会导致响应时间明显变慢。
6、Redis本身使用的CPU情况。
7、以上是原理层面分析超时问题;如果排查不出来问题,就需要进行抓包分析;
时间原因,先这么多吧。