假如redis容量不够;redis如何进行扩容?
redis主从和哨兵可以解决高可用;高并发读的问题;但是高并发写的问题如何解决?
使用分片集群可以解决上述问题。
分片集群特征;
·集群中有多个master;每个master保存不同的数据;
·每个master都可以有多个slave节点;
·master之间通过ping监测彼此健康状态;
·客户端请求可以访问集群任意节点;最终都会转发到正确节点。

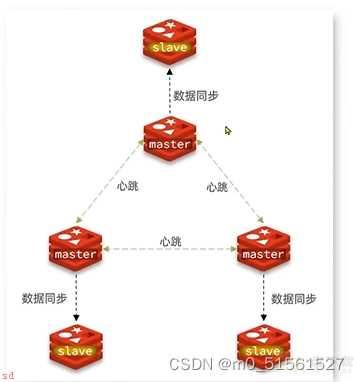
分片集群需要的节点数量较多;这里搭建一个最小的分片集群;包含3个master节点;每个master节点包含一个slave节点;结构如下;
1;制作6个实例;6379,6380,6381,6389,6390,6391
修改redis6379.conf配置文件如下;

2;再把内容复制到其他五个配置文件中去;

3;在各自的配置文件中修改各自的端口号;rdb文件名等等;就是把里面的所有的6379改为6380;;其他配置文件操作一样;

4;之后启动6个redis实例;

5;查看启动情况;

成功之后会生成结点文件;

结点文件的生成位置与自己设置的默认目录有关。
6;进入rb环境
先进入redis最开始安装的src中;

在进入redis-6.2.6中;

redis-6.2.6里面有一个src目录;进入这个目录;

在这个目录下执行命令;

注意如果redis没有设置密码和设置了密码;命令会有所不同;这里是设置了密码的情况。
执行命令后会出现;

执行命令后redis会自动合成集群;我们填入yes后;

到这一步集群已经完成。
之前的连接;redis-cli -p 端口号

集群连接;redis-cli -c -p 端口号
-c;采用集群策略连接;设置数据会自动切换到相应的写主机。

cluster nodes;查看集群中结点的信息

可以看到master与slave的主从信息。
1;redis cluster如何分配这六个结点?
一个集群中至少有三个主节点;
选项–cluster-replicas 1 表示希望为集群中的每个主节点创建一个从节点;
分配原则;尽量保证每个主数据库运行在不同的ip地址;每个从库和主库不在一个ip地址上。
2;散列插槽slots
Redis会把每一个master节点映射到0~16383共16384个插槽;hash slot;上;查看集群信息就能看到;

数据key不是与节点绑定而是与插槽绑定。redis会根据key的有效部分计算插槽;分两种情况;
· key中包含“{}”。且“{}”中至少包含一个字符;“{}”中的部分是有效部分;
· key中不包含“{}”;整个key都是有效部分
例如;key是num;那么久根据num计算;如果是{a}num;则根据a计算。计算方式是利用CRC16算法得到一个hash值;然后对16384取余;得到的结果就是slot值。
3;测试;

可以看到name计算出来的slot值是5798;而5798插槽在端口号为6780的主机上;所以进行了重定向。
总结;

1、添加一个结点到集群

案例;

1;先创建一个redis6382.conf配置文件;把redis6379.conf的内容复制到里面;在里面把所有6379改为6382。;

2;启动端口号为6382的redis实例;

3;把6382实例加入到集群中;

查看集群中的节点信息;

可以看到已经成功加入;但是6382并没有任何插槽。
3;要把num存储到6382实例中;可以先查看num的插槽值;再把那插槽分配给6382实例;

可以看到num在端口号为6379的实例中并且slot是2765;只要把2765插槽分配到6382实例中;例如移动3000个;就可以把num存储到6382实例中;
使用reshard重新分片;

还需要告知数据接收和数据来源;如上图把6382的id复制到数据接收处;6379的id复制到数据来源处;最后完成done。

确定yes。

可以看到插槽0到2999已经移到6382端口的redis实例中了。

num已经在6382端口的redis实例中了;再把num的值set为10 完成。

2、删除集群中的一个结点
案例;删除6382这个实例
按照上述分片步骤先把6382上的插槽转移到其他结点上;

可以看到6382上面已经没有插槽了;在执行以下步骤;

forget 后面加上6382这个实例的id;再查看结点信息;

可以看到6382已经删除了。
当集群中有一个master宕机会发生什么?

1、首先通过watch监控集群的状态;


2、再令某台主机宕机;例如令6380宕机;

查看集群状态;

可以看到6380的状态已经fail了;而6389成为了新的主机。;这里本来计划是6390成为新的主机的;是之前系统安排了6389作为6380的从机;所以6389成为了新的主机;
3、使6380再启动起来;


可以看到6380作为6389的slave加入到集群中了。
可以看到并不需要哨兵集群也能自动进行故障切换。
有时候需要手动进行故障转移
1、为什么?
比如集群中某台主机老化或者需要维护了;这时候可以启用一个新的节点;这个新节点性能比较好;让它作为这台主机的slave;手动让新节点去替换老化的主机;手动进行故障转移进行机器升级。
2、怎么做?
数据迁移;

案例;在6380这个slave节点执行手动故障转移;重新夺回master地位。


6380已经重新成为master了;而6389重新成为slave。




