pg14 相关 《PostgreSQL源码(61)查询执行——最外层Portal模块》 《Postgresql源码(62)查询执行——子模块ProcessUtility》 《Postgresql源码(63)查询执行——子模块Executor(1)》 《Postgresql源码(64)查询执行——子模块Executor(2)执行前的数据结构和执行过程》 《Postgresql查询执行模块README笔记》
The executor processes a tree of “plan nodes”. The plan tree is essentially a demand-pull pipeline of tuple Processing operations. Each node, when called, will produce the next tuple in its output sequence, or NULL if no more tuples are available. If the node is not a primitive relation-scanning node, it will have child node(s) that it calls in turn to obtain input tuples.
执行器用于处理Plan nodes。
计划树本质上是tuple处理操作的需求拉动pipeline。
每个节点在被调用时将在其输出序列中生成下一个元组,如果没有更多的元组可用,则为 NULL。
如果节点不是原始节点,则会有子节点帮助父节点获取元组。
Choice of scan direction (forwards or backwards). Caution: this is not currently well-supported. It works for primitive scan nodes, but not very well for joins, aggregates, etc.Rescan command to reset a node and make it generate its output sequence over again.Parameters that can alter a node’s results. After adjusting a parameter, the rescan command must be applied to that node and all nodes above it. There is a moderately intelligent scheme to avoid rescanning nodes unnecessarily (for example, Sort does not rescan its input if no parameters of the input have changed, since it can just reread its stored sorted data).Refinements on this basic model include:
此基本模型的改进包括:
选择扫描方向(向前或向后) 重新扫描命令重置节点并使其重新生成其输出序列。 可以改变节点结果的参数。调整参数后,必须将重新扫描命令应用于该节点及其上方的所有节点。有一种适度智能的方案可以避免不必要地重新扫描节点(例如,如果输入的参数没有更改,Sort 不会重新扫描其输入,因为它可以重新读取其存储的排序数据)。对于 SELECT,只需将顶级结果元组传递给客户端。 对于 INSERT/UPDATE/DELETE,实际的表修改操作发生在顶级 ModifyTable 计划节点中。 处理 INSERT 非常简单:从 ModifyTable 下方的计划树返回的元组被插入到正确的结果关系中。对于 UPDATE,计划树返回更新列的新值,以及标识要更新的表行的“垃圾”(隐藏)列。ModifyTable 节点必须获取该行以提取未更改列的值,将这些值组合到一个新行中,然后应用更新。 (对于堆表,行标识垃圾列是 CTID,但其他表类型可以使用其他东西。)对于 DELETE,计划树只需要传递垃圾行标识列和 ModifyTable 节点访问这些行中的每一行并将行标记为已删除。 如果查询包含 RETURNING 子句,则 ModifyTable 节点将计算的 RETURNING 行作为输出提供,否则不返回任何内容。For a SELECT, it is only necessary to deliver the top-level result tuples to the client. For INSERT/UPDATE/DELETE, the actual table modification operations happen in a top-level ModifyTable plan node. If the query includes a RETURNING clause, the ModifyTable node delivers the computed RETURNING rows as output, otherwise it returns nothing. Handling INSERT is pretty straightforward: the tuples returned from the plan tree below ModifyTable are inserted into the correct result relation. For UPDATE, the plan tree returns the new values of the updated columns, plus “junk” (hidden) column(s) identifying which table row is to be updated. The ModifyTable node must fetch that row to extract values for the unchanged columns, combine the values into a new row, and apply the update. (For a heap table, the row-identity junk column is a CTID, but other things may be used for other table types.) For DELETE, the plan tree need only deliver junk row-identity column(s), and the ModifyTable node visits each of those rows and marks the row deleted.XXX a great deal more documentation needs to be written here…
The plan tree delivered by the planner contains a tree of Plan nodes (struct types derived from struct Plan). During executor startup we build a parallel tree of identical structure containing executor state nodes — generally, every plan node type has a corresponding executor state node type. Each node in the state tree has a pointer to its corresponding node in the plan tree, plus executor state data as needed to implement that node type. This arrangement allows the plan tree to be completely read-only so far as the executor is concerned: all data that is modified during execution is in the state tree. Read-only plan trees make life much simpler for plan caching and reuse.
planner提供的计划树包含计划节点树(从结构计划派生的结构类型)。
在执行器启动过程中,我们构建了一个包含执行器状态节点的相同结构的并行树 每个plan node type都有对应的executor state node type。 状态树中的每个节点都有一个指向计划树中其对应节点的指针,以及实现该节点类型所需的执行器状态数据。这种安排允许计划树就执行器而言是完全只读的:在执行期间修改的所有数据都在状态树中。 只读计划树使计划缓存和重用变得更加简单。 和之前总结的一致,执行时真正使用的是state node:《Postgresql源码(64)查询执行——子模块Executor(2)执行前的数据结构和执行过程》 Plan生成PlanState
A corresponding executor state node may not be created during executor startup if the executor determines that an entire subplan is not required due to execution time partition pruning determining that no matching records will be found there. This currently only occurs for Append and MergeAppend nodes. In this case the non-required subplans are ignored and the executor state’s subnode array will become out of sequence to the plan’s subplan list.
如果执行器由于执行时间分区剪枝确定在那里找不到匹配的记录,因此执行器确定不需要整个子计划,则可能不会在执行器启动期间创建相应的执行器状态节点。目前这只发生在 Append 和 MergeAppend 节点上。在这种情况下,不需要的子计划将被忽略,并且执行程序状态的子节点数组将变得与计划的子计划列表的顺序不一致。
Each Plan node may have expression trees associated with it, to represent its target list, qualification conditions, etc. These trees are also read-only to the executor, but the executor state for expression evaluation does not mirror the Plan expression’s tree shape, as explained below. Rather, there’s just one ExprState node per expression tree, although this may have sub-nodes for some complex expression node types.
每个 Plan 节点可能有与其关联的表达式树,以表示其目标列表、限定条件等。这些树对于执行器也是只读的,但表达式评估的执行器状态不反映 Plan 表达式的树形,因为下面解释。相反,每个表达式树只有一个 ExprState 节点,尽管这可能有一些复杂表达式节点类型的子节点。
Altogether there are four classes of nodes used in these trees: Plan nodes, their corresponding PlanState nodes, Expr nodes, and ExprState nodes. (Actually, there are also List nodes, which are used as “glue” in all three tree-based representations.)
在这些树中总共使用了四类节点:Plan 节点、它们对应的 PlanState 节点、Expr 节点和 ExprState 节点。 (实际上,还有 List 节点,它们在所有三种基于树的表示中都用作“粘合剂”。)
Expression trees, in contrast to Plan trees, are not mirrored into a corresponding tree of state nodes. Instead each separately executable expression tree (e.g. a Plan’s qual or targetlist) is represented by one ExprState node. The ExprState node contains the information needed to evaluate the expression in a compact, linear form. That compact form is stored as a flat array in ExprState->steps[] (an array of ExprEvalStep, not ExprEvalStep *).
与计划树相比,表达式树不会镜像到相应的状态树中。
相反,每个单独的可执行表达式树(例如计划的 qual 或 targetlist)由一个 ExprState 节点表示。
ExprState 节点包含以紧凑的线性形式计算表达式所需的信息。该紧凑形式存储为ExprState->steps[]中的数组(ExprEvalStep 数组,而不是 ExprEvalStep *)。
在这里:
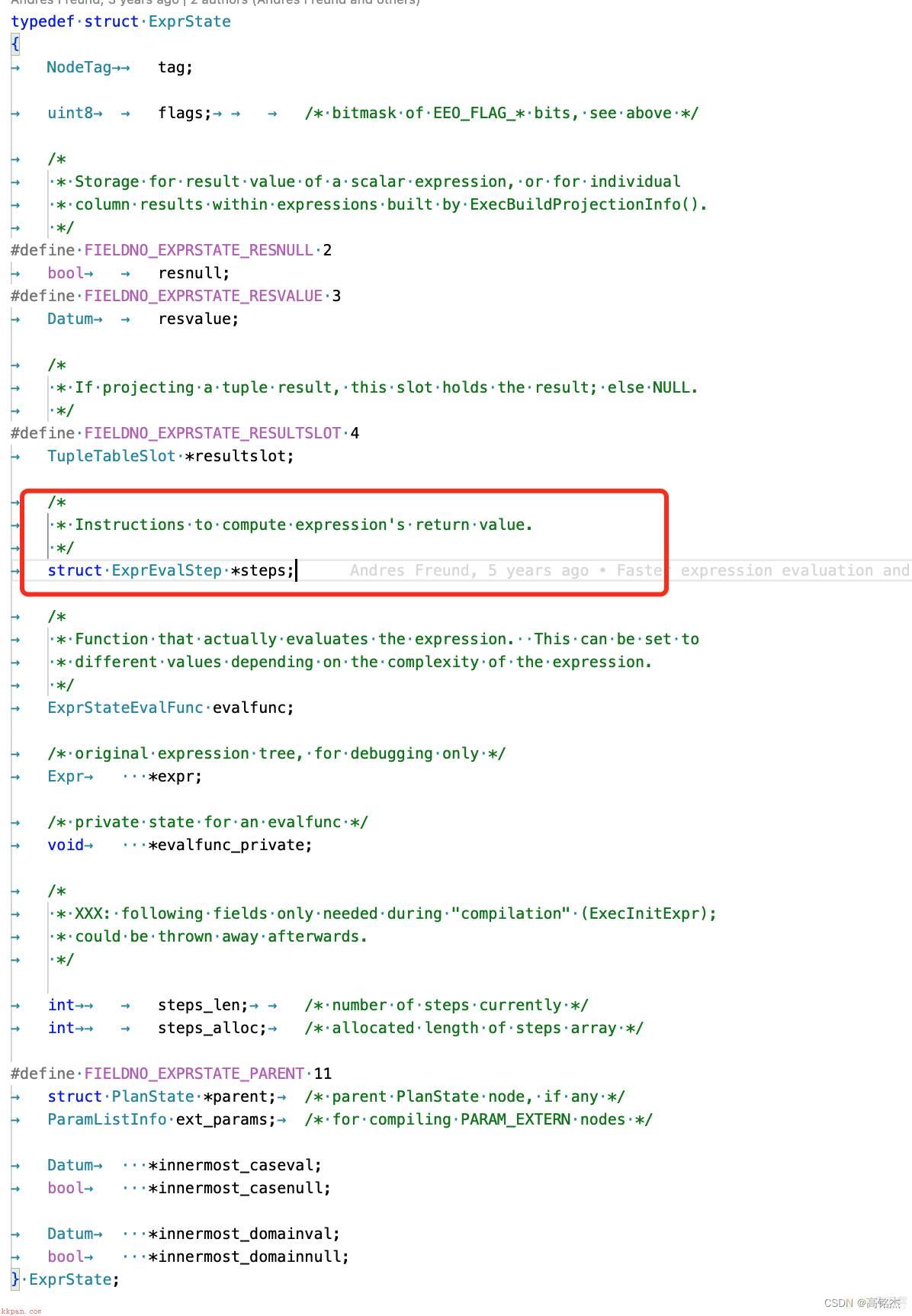
在PlanState中记录

commonly the amount of work needed to evaluate one Expr-type node is small enough that the overhead of having to perform a tree-walk during evaluation is significant.the flat representation can be evaluated non-recursively within a single function, reducing stack depth and function call overhead.such a representation is usable both for fast interpreted execution, and for compiling into native code.The reasons for choosing such a representation include:
使用这样的数据结构原因包括:
通常评估一个 Expr 类型节点所需的工作量足够小,以至于在评估期间必须执行 tree-walk 的开销很大。可以在单个函数内以非递归方式评估平面表示,从而减少堆栈深度和函数调用开销。这种表示既可用于快速解释执行,也可用于编译为本机代码。The Plan-tree representation of an expression is compiled into an ExprState node by ExecInitExpr(). As much complexity as possible should be handled by ExecInitExpr() (and helpers), instead of execution time where both interpreted and compiled versions would need to deal with the complexity. Besides duplicating effort between execution approaches, runtime initialization checks also have a small but noticeable cost every time the expression is evaluated. Therefore, we allow ExecInitExpr() to precompute information that we do not expect to vary across execution of a single query, for example the set of CHECK constraint expressions to be applied to a domain type. This could not be done at plan time without greatly increasing the number of events that require plan invalidation. (Previously, some information of this kind was rechecked on each expression evaluation, but that seems like unnecessary overhead.)
表达式的计划树表示由 ExecInitExpr() 编译到 ExprState 节点中。
PlanState->ExprState的数据使用ExecInitExpr构造。ExecInitExpr() 应该处理尽可能多的复杂性,而不是解释和编译版本都需要处理复杂性的执行时间。除了在执行方法之间进行重复工作之外,运行时初始化检查在每次评估表达式时也会产生少量但值得注意的成本。因此,我们允许ExecInitExpr()预先计算我们不希望在执行单个查询时发生变化的信息,例如应用于域类型的 CHECK 约束表达式集。如果不大大增加需要计划失效的事件数量,就无法在计划时间内完成此操作。 (以前,在每次表达式评估时都会重新检查一些此类信息,但这似乎是不必要的开销。)例如执行:
postgres=# select 2/1;
?column?
----------
2
(1 row) 在下面堆栈中构造ExprState
(gdb) bt
#0 ExecInitExpr (node=0x28ddf28, parent=0x0) at execExpr.c:126
#1 0x0000000000871a3c in evaluate_expr (expr=0x28ddf28, result_type=23, result_typmod=-1, result_collation=0) at clauses.c:4765
#2 0x0000000000870d59 in evaluate_function (funcid=154, result_type=23, result_typmod=-1, result_collid=0, input_collid=0, args=0x28dde78,
funcvariadic=false, func_tuple=0x7f02d08db558, context=0x7ffffd638ef0) at clauses.c:4277
#3 0x0000000000870056 in simplify_function (funcid=154, result_type=23, result_typmod=-1, result_collid=0, input_collid=0, args_p=0x7ffffd637c18,
funcvariadic=false, process_args=true, allow_non_const=true, context=0x7ffffd638ef0) at clauses.c:3860
#4 0x000000000086d6ff in eval_const_expressions_mutator (node=0x28dd5f8, context=0x7ffffd638ef0) at clauses.c:2427
#5 0x00000000007de3d5 in expression_tree_mutator (node=0x28dd650, mutator=0x86d079 <eval_const_expressions_mutator>, context=0x7ffffd638ef0)
at nodeFuncs.c:3047
#6 0x000000000086fa26 in eval_const_expressions_mutator (node=0x28dd650, context=0x7ffffd638ef0) at clauses.c:3479
#7 0x00000000007de66d in expression_tree_mutator (node=0x28dd6a8, mutator=0x86d079 <eval_const_expressions_mutator>, context=0x7ffffd638ef0)
at nodeFuncs.c:3111
#8 0x000000000086fa26 in eval_const_expressions_mutator (node=0x28dd6a8, context=0x7ffffd638ef0) at clauses.c:3479
#9 0x000000000086cef7 in eval_const_expressions (root=0x28dd880, node=0x28dd6a8) at clauses.c:2107
#10 0x0000000000846942 in preprocess_expression (root=0x28dd880, expr=0x28dd6a8, kind=1) at planner.c:1099
#11 0x0000000000845ebf in subquery_planner (glob=0x28dd7e8, parse=0x28dd3d8, parent_root=0x0, hasRecursion=false, tuple_fraction=0) at planner.c:781
#12 0x000000000084509c in standard_planner (parse=0x28dd3d8, query_string=0x28dc4d0 "select 2/1;", cursorOptions=2048, boundParams=0x0) at planner.c:400
#13 0x0000000000844e4f in planner (parse=0x28dd3d8, query_string=0x28dc4d0 "select 2/1;", cursorOptions=2048, boundParams=0x0) at planner.c:271
#14 0x00000000009760b0 in pg_plan_query (querytree=0x28dd3d8, query_string=0x28dc4d0 "select 2/1;", cursorOptions=2048, boundParams=0x0) at postgres.c:846
#15 0x00000000009761f6 in pg_plan_queries (querytrees=0x28dd790, query_string=0x28dc4d0 "select 2/1;", cursorOptions=2048, boundParams=0x0) at postgres.c:938
#16 0x000000000097655a in exec_simple_query (query_string=0x28dc4d0 "select 2/1;") at postgres.c:1132
#17 0x000000000097abf1 in PostgresMain (argc=1, argv=0x7ffffd639540, dbname=0x2905c78 "postgres", username=0x28d80f8 "mingjiegao") at postgres.c:4494
#18 0x00000000008b6de6 in BackendRun (port=0x28feb10) at postmaster.c:4530
#19 0x00000000008b6765 in BackendStartup (port=0x28feb10) at postmaster.c:4252
#20 0x00000000008b2bdd in ServerLoop () at postmaster.c:1745
#21 0x00000000008b24af in PostmasterMain (argc=1, argv=0x28d60c0) at postmaster.c:1417
#22 0x00000000007b4d2b in main (argc=1, argv=0x28d60c0) at main.c:209 During ExecInitExpr() and similar routines, Expr trees are converted into the flat representation. Each Expr node might be represented by zero, one, or more ExprEvalSteps.
在 ExecInitExpr() 和类似的例程中,Expr 树被转换为平面表示。 每个 Expr 节点可能由零个、一个或多个 ExprEvalSteps 表示。
Each ExprEvalStep’s work is determined by its opcode (of enum ExprEvalOp) and it stores the result of its work into the Datum variable and boolean null flag variable pointed to by ExprEvalStep->resvalue/resnull. Complex expressions are performed by chaining together several steps. For example, “a + b” (one OpExpr, with two Var expressions) would be represented as two steps to fetch the Var values, and one step for the evaluation of the function underlying the + operator. The steps for the Vars would have their resvalue/resnull pointing directly to the appropriate args[].value .isnull elements in the FunctionCallInfoBaseData struct that is used by the function evaluation step, thus avoiding extra work to copy the result values around.
每个 ExprEvalStep 的工作由其操作码(枚举 ExprEvalOp)确定,并将其工作结果存储到 ExprEvalStep->resvalue/resnull 指向的 Datum 变量和布尔空标志变量中。 通过将几个步骤链接在一起来执行复杂的表达式。
例如,“a + b”(一个 OpExpr,带有两个 Var 表达式)将表示为两个步骤来获取 Var 值,以及一个步骤来评估 + 运算符底层的函数。 Vars 的步骤将使其 resvalue/resnull 直接指向函数评估步骤使用的 FunctionCallInfoBaseData 结构中的适当 args[].value .isnull 元素,从而避免复制结果值的额外工作。
The last entry in a completed ExprState->steps array is always an EEOP_DONE step; this removes the need to test for end-of-array while iterating. Also, if the expression contains any variable references (to user columns of the ExprContext’s INNER, OUTER, or SCAN tuples), the steps array begins with EEOP_*_FETCHSOME steps that ensure that the relevant tuples have been deconstructed to make the required columns directly available (cf. slot_getsomeattrs()). This allows individual Var-fetching steps to be little more than an array lookup.
已完成的 ExprState->steps 数组中的最后一个条目始终是 EEOP_DONE 步骤; 这消除了在迭代时测试数组结尾的需要。 此外,如果表达式包含任何变量引用(对 ExprContext 的 INNER、OUTER 或 SCAN 元组的用户列),则步骤数组以 EEOP_*_FETCHSOME 步骤开始,以确保已解构相关元组以使所需列直接可用 (参见 slot_getsomeattrs())。 这允许单独的 Var-fetching 步骤只是一个数组查找。
Most of ExecInitExpr()'s work is done by the recursive function ExecInitExprRec() and its subroutines. ExecInitExprRec() maps one Expr node into the steps required for execution, recursing as needed for sub-expressions.
ExecInitExpr() 的大部分工作是由递归函数 ExecInitExprRec() 及其子例程完成的。 ExecInitExprRec() 将一个 Expr 节点映射到执行所需的步骤,根据子表达式的需要递归。
Each ExecInitExprRec() call has to specify where that subexpression’s results are to be stored (via the resv/resnull parameters). This allows the above scenario of evaluating a (sub-)expression directly into fcinfo->args[].value/isnull, but also requires some care: target Datum/isnull variables may not be shared with another ExecInitExprRec() unless the results are only needed by steps executing before further usages of those target Datum/isnull variables. Due to the non-recursiveness of the ExprEvalStep representation that’s usually easy to guarantee.
每个 ExecInitExprRec() 调用都必须指定子表达式结果的存储位置(通过 resv/resnull 参数)。 这允许将(子)表达式直接评估为 fcinfo->args[].value/isnull 的上述场景,但也需要注意:目标 Datum/isnull 变量可能不会与另一个 ExecInitExprRec() 共享,除非结果是 只有在进一步使用这些目标 Datum/isnull 变量之前执行的步骤才需要。 由于 ExprEvalStep 表示的非递归性通常很容易保证。
ExecInitExprRec() pushes new operations into the ExprState->steps array using ExprEvalPushStep(). To keep the steps as a consecutively laid out array, ExprEvalPushStep() has to repalloc the entire array when there’s not enough space. Because of that it is allowed to point directly into any of the steps during expression initialization. Therefore, the resv/resnull for a subexpression usually point to some storage that is palloc’d separately from the steps array. For instance, the FunctionCallInfoBaseData for a function call step is separately allocated rather than being part of the ExprEvalStep array. The overall result of a complete expression is typically returned into the resvalue/resnull fields of the ExprState node itself.
ExecInitExprRec() 使用 ExprEvalPushStep() 将新操作推送到 ExprState->steps 数组中。 为了将步骤保持为连续布局的数组,当空间不足时,ExprEvalPushStep() 必须重新分配整个数组。 因此, 在表达式初始化期间直接指向任何步骤。 因此,子表达式的 resv/resnull 通常指向与 steps 数组分开分配的一些存储。 例如,函数调用步骤的 FunctionCallInfoBaseData 是单独分配的,而不是 ExprEvalStep 数组的一部分。 完整表达式的总体结果通常返回到 ExprState 节点本身的 resvalue/resnull 字段中。
Some steps, e.g. boolean expressions, allow skipping evaluation of certain subexpressions. In the flat representation this amounts to jumping to some later step rather than just continuing consecutively with the next step. The target for such a jump is represented by the integer index in the ExprState->steps array of the step to execute next. (Compare the EEO_NEXT and EEO_JUMP macros in execExprInterp.c.)
一些步骤,例如 布尔表达式,允许跳过某些子表达式的评估。 在flat表示中,这相当于跳到后面的某个步骤,而不仅仅是连续地继续下一步。 这种跳转的目标由下一步要执行的步骤的 ExprState->steps 数组中的整数索引表示。 (比较 execExprInterp.c 中的 EEO_NEXT 和 EEO_JUMP 宏。)
Typically, ExecInitExprRec() has to push a jumping step into the steps array, then recursively generate steps for the subexpression that might get skipped over, then go back and fix up the jump target index using the now-known length of the subexpression’s steps. This is handled by adjust_jumps lists in execExpr.c.
通常,ExecInitExprRec() 必须将跳转步骤推入 steps 数组,然后递归地为可能被跳过的子表达式生成步骤,然后返回并使用现在已知的子表达式步骤长度修复跳转目标索引。 这由 execExpr.c 中的 adjust_jumps 列表处理。
The last step in constructing an ExprState is to apply ExecReadyExpr(), which readies it for execution using whichever execution method has been selected.
构造 ExprState 的最后一步是应用 ExecReadyExpr(),它准备使用已选择的任何执行方法执行它。
To allow for different methods of expression evaluation, and for better branch/jump target prediction, expressions are evaluated by calling ExprState->evalfunc (via ExecEvalExpr() and friends).
为了允许不同的表达式求值方法,以及更好的分支/跳转目标预测,表达式是通过调用 ExprState->evalfunc(通过 ExecEvalExpr() 和朋友)来求值的。
ExecReadyExpr() can choose the method of interpretation by setting evalfunc to an appropriate function. The default execution function, ExecInterpExpr, is implemented in execExprInterp.c; see its header comment for details. Special-case evalfuncs are used for certain especially-simple expressions.
ExecReadyExpr() 可以通过将 evalfunc 设置为适当的函数来选择解释方法。默认执行函数 ExecInterpExpr 在 execExprInterp.c 中实现;有关详细信息,请参阅其标题注释。特殊情况 evalfunc 用于某些特别简单的表达式。
Note that a lot of the more complex expression evaluation steps, which are less performance-critical than the simpler ones, are implemented as separate functions outside the fast-path of expression execution, allowing their implementation to be shared between interpreted and compiled expression evaluation. This means that these helper functions are not allowed to perform expression step dispatch themselves, as the method of dispatch will vary based on the caller. The helpers therefore cannot call for the execution of subexpressions; all subexpression results they need must be computed by earlier steps. And dispatch to the following expression step must be performed after returning from the helper.
请注意,许多更复杂的表达式求值步骤(它们对性能的要求不如简单的那些)在表达式执行的快速路径之外作为单独的函数实现,从而允许在解释和编译表达式求值之间共享它们的实现。这意味着这些辅助函数不允许自己执行表达式步骤分派,因为分派方法会因调用者而异。因此,助手不能调用子表达式的执行;他们需要的所有子表达式结果都必须通过前面的步骤计算出来。并且必须在从助手返回后执行对以下表达式步骤的分派。
ExecBuildProjectionInfo builds an ExprState that has the effect of evaluating a targetlist into ExprState->resultslot. A generic targetlist expression is executed by evaluating it as discussed above (storing the result into the ExprState’s resvalue/resnull fields) and then using an EEOP_ASSIGN_TMP step to move the result into the appropriate tts_values[] and tts_isnull[] array elements of the result slot. There are special fast-path step types (EEOP_ASSIGN_*_VAR) to handle targetlist entries that are simple Vars using only one step instead of two.
ExecBuildProjectionInfo 构建一个 ExprState,它具有评估目标列表到ExprState->resultslot的效果。 通用 targetlist 表达式的执行方式是如上所述评估它(将结果存储到 ExprState 的 resvalue/resnull 字段中),然后使用 EEOP_ASSIGN_TMP 步骤将结果移动到结果槽的适当 tts_values[] 和 tts_isnull[] 数组元素中 . 有特殊的快速路径步骤类型 (EEOP_ASSIGN_*_VAR) 来处理目标列表条目,这些条目是简单的 Var,只使用一个步骤而不是两个步骤。
A “per query” memory context is created during CreateExecutorState(); all storage allocated during an executor invocation is allocated in that context or a child context. This allows easy reclamation of storage during executor shutdown — rather than messing with retail pfree’s and probable storage leaks, we just destroy the memory context.
在 CreateExecutorState() 期间创建“每个查询”内存上下文; 在执行程序调用期间分配的所有存储都在该上下文或子上下文中分配。 这允许在执行程序关闭期间轻松回收存储 — 而不是弄乱零售 pfree 和可能的存储泄漏,我们只是破坏内存上下文。
In particular, the plan state trees and expression state trees described in the previous section are allocated in the per-query memory context.
特别是,上一节中描述的计划状态树和表达式状态树是在每个查询的内存上下文中分配的。
To avoid intra-query memory leaks, most processing while a query runs is done in “per tuple” memory contexts, which are so-called because they are typically reset to empty once per tuple. Per-tuple contexts are usually associated with ExprContexts, and commonly each PlanState node has its own ExprContext to evaluate its qual and targetlist expressions in.
为了避免查询内内存泄漏,查询运行时的大多数处理都是在“每个元组”内存上下文中完成的,之所以这么称呼是因为它们通常会在每个元组中重置为空一次。 每元组上下文通常与 ExprContexts 相关联,通常每个 PlanState 节点都有自己的 ExprContext 来评估其 qual 和 targetlist 表达式。
CreateQueryDesc ExecutorStart CreateExecutorState creates per-query context switch to per-query context to run ExecInitNode AfterTriggerBeginQuery ExecInitNode --- recursively scans plan tree ExecInitNode recurse into subsidiary nodes CreateExprContext creates per-tuple context ExecInitExpr ExecutorRun ExecProcNode --- recursively called in per-query context ExecEvalExpr --- called in per-tuple context ResetExprContext --- to free memory ExecutorFinish ExecPostprocessPlan --- run any unfinished ModifyTable nodes AfterTriggerEndQuery ExecutorEnd ExecEndNode --- recursively releases resources FreeExecutorState frees per-query context and child contexts FreeQueryDesc
Per above comments, it’s not really critical for ExecEndNode to free any memory; it’ll all go away in FreeExecutorState anyway. However, we do need to be careful to close relations, drop buffer pins, etc, so we do need to scan the plan state tree to find these sorts of resources.
根据上述评论, ExecEndNode 释放任何内存并不重要; 无论如何,它都会在 FreeExecutorState 中消失。 但是,我们确实需要小心关闭关系、丢弃缓冲区pins,因此我们确实需要扫描计划状态树以找到这些资源。
The executor can also be used to evaluate simple expressions without any Plan tree (“simple” meaning “no aggregates and no sub-selects”, though such might be hidden inside function calls). This case has a flow of control like
执行器也可用于评估没有任何计划树的简单表达式(“简单”表示“没有聚合和子选择”,尽管这可能隐藏在函数调用中)。 这个案例有一个控制流程,比如
CreateExecutorState creates per-query context CreateExprContext -- or use GetPerTupleExprContext(estate) creates per-tuple context ExecPrepareExpr temporarily switch to per-query context run the expression through expression_planner ExecInitExpr Repeatedly do: ExecEvalExprSwitchContext ExecEvalExpr --- called in per-tuple context ResetExprContext --- to free memory FreeExecutorState frees per-query context, as well as ExprContext (a separate FreeExprContext call is not necessary)
For simple SELECTs, the executor need only pay attention to tuples that are valid according to the snapshot seen by the current transaction (ie, they were inserted by a previously committed transaction, and not deleted by any previously committed transaction). However, for UPDATE and DELETE it is not cool to modify or delete a tuple that’s been modified by an open or concurrently-committed transaction. If we are running in SERIALIZABLE isolation level then we just raise an error when this condition is seen to occur. In READ COMMITTED isolation level, we must work a lot harder.
对于简单的 SELECT,执行器只需要注意根据当前事务看到的快照有效的元组(即,它们是由先前提交的事务插入的,并且没有被任何先前提交的事务删除)。
但是,对于 UPDATE 和 DELETE,修改或删除已被打开或并发提交的事务修改的元组并不酷。
如果我们在 SERIALIZABLE 隔离级别下运行,那么我们只会在看到这种情况发生时引发错误。 在 READ COMMITTED 隔离级别,我们必须更加努力。
The basic idea in READ COMMITTED mode is to take the modified tuple committed by the concurrent transaction (after waiting for it to commit, if need be) and re-evaluate the query qualifications to see if it would still meet the quals. If so, we regenerate the updated tuple (if we are doing an UPDATE) from the modified tuple, and finally update/delete the modified tuple. SELECT FOR UPDATE/SHARE behaves similarly, except that its action is just to lock the modified tuple and return results based on that version of the tuple.
READ COMMITTED 模式的基本思想是获取并发事务提交的修改元组(如果需要,在等待它提交之后)并重新评估查询条件,看看它是否仍然符合条件。
如果是这样,我们从修改后的元组重新生成更新后的元组(如果我们正在执行更新),最后更新/删除修改后的元组。
SELECT FOR UPDATE/SHARE 的行为类似,只是它的作用只是锁定修改后的元组并根据该元组的版本返回结果。
To implement this checking, we actually re-run the query from scratch for each modified tuple (or set of tuples, for SELECT FOR UPDATE), with the relation scan nodes tweaked to return only the current tuples — either the original ones, or the updated (and now locked) versions of the modified tuple(s). If this query returns a tuple, then the modified tuple(s) pass the quals (and the query output is the suitably modified update tuple, if we’re doing UPDATE). If no tuple is returned, then the modified tuple(s) fail the quals, so we ignore the current result tuple and continue the original query.
为了实现这个检查,我们实际上从头开始为每个修改的元组(或一组元组,对于 SELECT FOR UPDATE)重新运行查询,调整关系扫描节点以仅返回当前元组——要么是原始元组,要么 或修改后的元组的更新(现在锁定)版本。
如果此查询返回一个元组,则修改后的元组通过 quals(如果我们正在执行 UPDATE,则查询输出是经过适当修改的更新元组)。
如果没有返回元组,则修改后的元组将失败,因此我们忽略当前结果元组并继续原始查询。
In UPDATE/DELETE, only the target relation needs to be handled this way. In SELECT FOR UPDATE, there may be multiple relations flagged FOR UPDATE, so we obtain lock on the current tuple version in each such relation before executing the recheck.
在 UPDATE/DELETE 中,只有目标关系需要以这种方式处理。 在 SELECT FOR UPDATE 中,可能有多个标记为 FOR UPDATE 的关系,因此我们在执行重新检查之前在每个此类关系中获取当前元组版本的锁定。
It is also possible that there are relations in the query that are not to be locked (they are neither the UPDATE/DELETE target nor specified to be locked in SELECT FOR UPDATE/SHARE). When re-running the test query we want to use the same rows from these relations that were joined to the locked rows. For ordinary relations this can be implemented relatively cheaply by including the row TID in the join outputs and re-fetching that TID. (The re-fetch is expensive, but we’re trying to optimize the normal case where no re-test is needed.) We have also to consider non-table relations, such as a ValuesScan or FunctionScan. For these, since there is no equivalent of TID, the only practical solution seems to be to include the entire row value in the join output row.
查询中也有可能存在未被锁定的关系(它们既不是 UPDATE/DELETE 目标,也不是在 SELECT FOR UPDATE/SHARE 中指定要锁定的)。 重新运行测试查询时,我们希望使用这些关系中与锁定行连接的相同行。 对于普通关系,这可以通过在连接输出中包含行 TID 并重新获取该 TID 来相对便宜地实现。 (重新获取成本很高,但我们正在尝试优化不需要重新测试的正常情况。)我们还必须考虑非表关系,例如 ValuesScan 或 FunctionScan。 对于这些,由于没有等效的 TID,唯一实际的解决方案似乎是将整个行值包含在连接输出行中。
We disallow set-returning functions in the targetlist of SELECT FOR UPDATE, so as to ensure that at most one tuple can be returned for any particular set of scan tuples. Otherwise we’d get duplicates due to the original query returning the same set of scan tuples multiple times. Likewise, SRFs are disallowed in an UPDATE’s targetlist. There, they would have the effect of the same row being updated multiple times, which is not very useful — and updates after the first would have no effect anyway.
我们不允许在 SELECT FOR UPDATE 的目标列表中返回集合返回函数,以确保对于任何特定的扫描元组集合最多可以返回一个元组。 否则,由于原始查询多次返回同一组扫描元组,我们会得到重复。 同样,在 UPDATE 的目标列表中也不允许使用 SRF。 在那里,它们会产生多次更新同一行的效果,这不是很有用 — 第一次之后的更新无论如何都没有效果。
https://postgr.es/m/CA%2BTgmoaXQEt4tZ03FtQhnzeDEMzBck%2BLrni0UWHVVgOTnA6C1w%40mail.gmail.com
In cases where a node is waiting on an event external to the database system, such as a ForeignScan awaiting network I/O, it’s desirable for the node to indicate that it cannot return any tuple immediately but may be able to do so at a later time. A process which discovers this type of situation can always handle it simply by blocking, but this may waste time that could be spent executing some other part of the plan tree where progress could be made immediately. This is particularly likely to occur when the plan tree contains an Append node. Asynchronous execution runs multiple parts of an Append node concurrently rather than serially to improve performance.
如果节点正在等待数据库系统外部的事件,例如等待网络 I/O 的 ForeignScan,则希望节点指示它不能立即返回任何元组,但可以稍后返回 时间。 发现这种情况的进程总是可以简单地通过阻塞来处理它,但这可能会浪费时间,这些时间可能会花在执行计划树的其他部分上,而这些部分可以立即取得进展。 当计划树包含 Append 节点时,这种情况尤其可能发生。 异步执行同时而不是串行运行 Append 节点的多个部分以提高性能。
For asynchronous execution, an Append node must first request a tuple from an async-capable child node using ExecAsyncRequest. Next, it must execute the asynchronous event loop using ExecAppendAsyncEventWait. Eventually, when a child node to which an asynchronous request has been made produces a tuple, the Append node will receive it from the event loop via ExecAsyncResponse. In the current implementation of asynchronous execution, the only node type that requests tuples from an async-capable child node is an Append, while the only node type that might be async-capable is a ForeignScan.
对于异步执行,Append 节点必须首先使用 ExecAsyncRequest 从支持异步的子节点请求元组。 接下来,它必须使用 ExecAppendAsyncEventWait 执行异步事件循环。 最终,当一个异步请求发送到的子节点产生一个元组时,Append 节点将通过 ExecAsyncResponse 从事件循环中接收它。 在异步执行的当前实现中,唯一从支持异步的子节点请求元组的节点类型是 Append,而唯一可能支持异步的节点类型是 ForeignScan。
Typically, the ExecAsyncResponse callback is the only one required for nodes that wish to request tuples asynchronously. On the other hand, async-capable nodes generally need to implement three methods:
通常,ExecAsyncResponse 回调是希望异步请求元组的节点唯一需要的回调。 另一方面,支持异步的节点一般需要实现三种方法:
When an asynchronous request is made, the node’s ExecAsyncRequest callback will be invoked; it should use ExecAsyncRequestPending to indicate that the request is pending for a callback described below. Alternatively, it can instead use ExecAsyncRequestDone if a result is available immediately.When the event loop wishes to wait or poll for file descriptor events, the node’s ExecAsyncConfigureWait callback will be invoked to configure the file descriptor event for which the node wishes to wait.When the file descriptor becomes ready, the node’s ExecAsyncNotify callback will be invoked; like #1, it should use ExecAsyncRequestPending for another callback or ExecAsyncRequestDone to return a result immediately.异步请求时,会调用节点的ExecAsyncRequest回调; 它应该使用 ExecAsyncRequestPending 来指示请求正在等待下面描述的回调。 或者,如果结果立即可用,它可以改为使用 ExecAsyncRequestDone。当事件循环希望等待或轮询文件描述符事件时,将调用节点的 ExecAsyncConfigureWait 回调来配置节点希望等待的文件描述符事件。当文件描述符就绪时,将调用节点的 ExecAsyncNotify 回调; 像 #1 一样,它应该使用 ExecAsyncRequestPending 进行另一个回调或 ExecAsyncRequestDone 立即返回结果。