大家好,又见面了,我是你们的朋友全栈君。
呃…又来水一篇
供上廖雪峰的python教程中关于string和encoding的讲解
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件;浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器;所以你看到很多网页的源码上会有类似<meta charset="UTF-8"/>的信息,表示该网页正是用的UTF-8编码。
为了避免乱码问题,我们统一用utf-8编码。由于Python源代码也是一个文本文件,所以当你的源代码包含中文的时候,在保存源代码的时候就务必指定保存为UTF-8编码。为了让Python解释器读取源代码的时候,能够按utf-8编码读取,我们会在文件开头加上这两行
#!/user/bin/env python3 # -*- coding: utf-8 -*-
在Pycharm中可以创建一个模版,每次新建python文件时Pycharm会默认在前两行生成utf-8,操作如下:
在setting中的Editor中找到File and Code Templates,在Python Script中添加代码

接着,在File Encoding中修改下编码
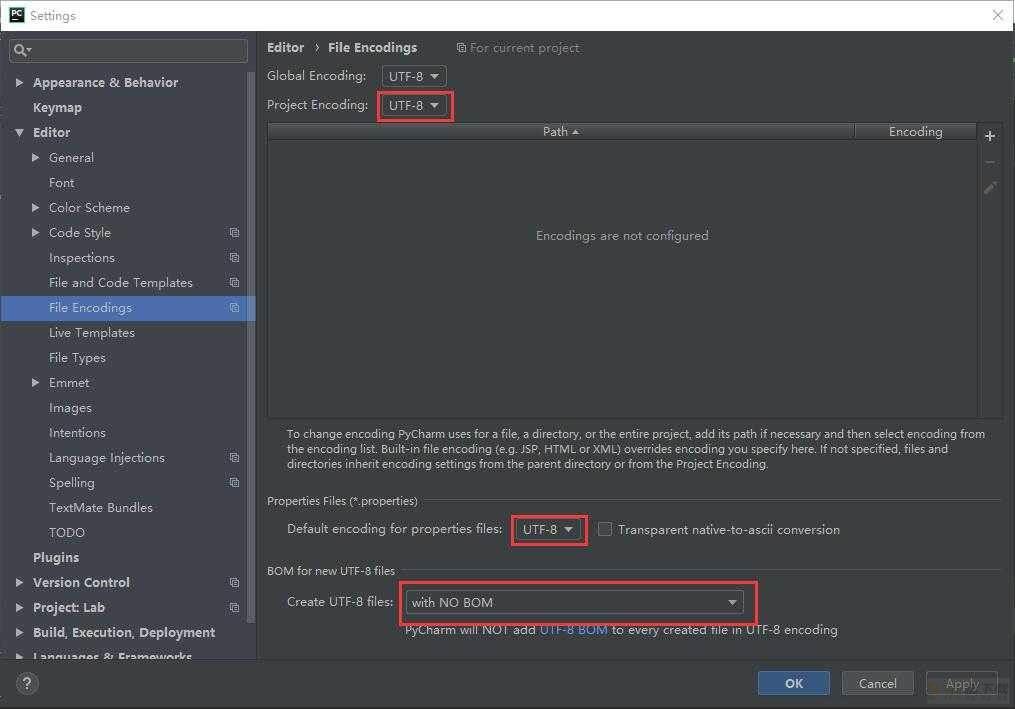
在文件中输入代码测试
print(u'测试中文')
完结
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/174568.html原文链接:https://javaforall.cn