[TOC]
Q: 什么是 EasyOCR ?
描述: EasyOCR 是一个用于从图像中提取文本的 python 模块, 它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。目前支持 80 多种语言和所有流行的书写脚本,包括:拉丁文、中文、阿拉伯文、梵文、西里尔文等。
Q: 使用 EasyOCR 可以干什么?
描述: EasyOCR 支持两种方式运行一种是常用的CPU,而另外一种是需要GPU支持并且需安装CUDA环境, 我们使用其可以进行图片中语言文字识别, 例如小程序里图片识别、车辆车牌识别(即车债管理系统)。

WeiyiGeek.Examples
Tips: 在其官网有demo演示,我们可以使用其进行简单图片ocr识别,地址为https://www.jaided.ai/easyocr/ 或者 https://huggingface.co/spaces/tomofi/EasyOCR
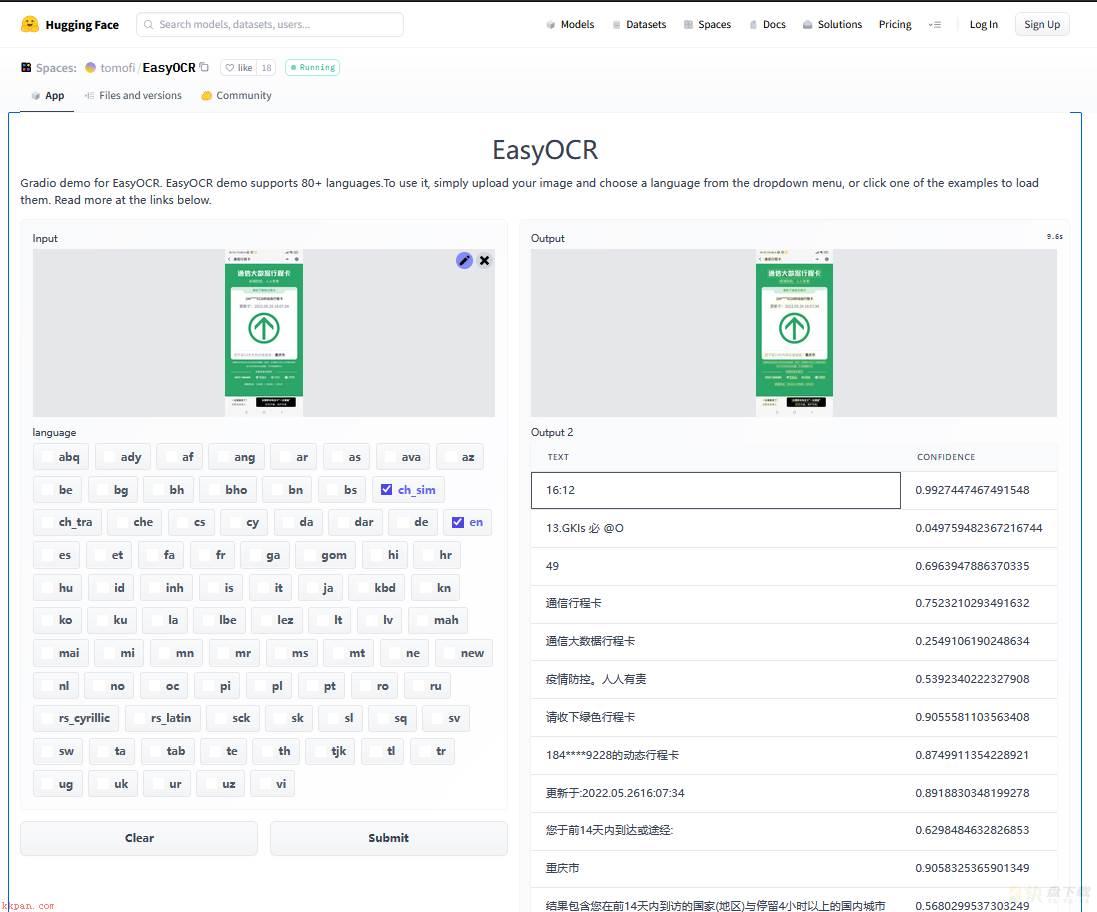
WeiyiGeek.官网Demo演示
EasyOCR Framework

WeiyiGeek.EasyOCR Framework
温馨提示: 图中 灰色插槽是可更换的浅蓝色模块的占位符,我们可以重构代码以支持可交换的检测和识别算法 api
官网地址: https://www.jaided.ai/easyocr/
项目地址: https://github.com/JaidedAI/EasyOCR
实践项目源码地址:https://github.com/WeiyiGeek/SecOpsDev/tree/master/Project/Python/EasyOCR/Travelcodeocr
文档原文地址: https://www.bilibili.com/read/cv16911816
实践视频地址: https://www.bilibili.com/video/BV1nY4y1x7JG
温馨提示: 该项目基于来自多篇论文和开源存储库的研究和代码,所有深度学习执行都基于 Pytorch ,识别模型是 CRNN 它由 3 个主要部分组成:特征提取(我们目前使用 Resnet )和 VGG、序列标记( LSTM )和解码( CTC )。 ❤️
环境依赖
Python 建议 3.8 x64 以上版本 (原本我的环境是 Python 3.7 安装时各种稀奇古怪的错误都出来,不得已abandon放弃)easyocr 包 -> 依赖 torch 、torchVision 第三方包注意事项:
Note 1.本章是基于 cpu 与 GPU 下使用 EasyOCR, 如果你需要使用 GPU 跑, 那么请你安装相应的CUDA环境。
$ NVIDIA-smi -l Fri May 27 14:57:57 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA Tesla V1... Off | 00000000:1B:00.0 Off | 0 | | N/A 41C P0 36W / 250W | 0MiB / 32510MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+
Note 2.最好在Python 3.8 x64 位系统上安装使用 easyocr , 非常注意其不支持32位的python。
Note 3.对于 Windows,请先按照 https://pytorch.org 的官方说明安装 torch 和 torchvision。 在 pytorch 网站上,请务必选择您拥有的正确 CUDA 版本。 如果您打算仅在 CPU 模式下运行,请选择 CUDA = None。
描述: 此处我们使用 pip 安装 easyocr 使用以及通过官方提供的dockerfile。
pip 方式 对于最新的稳定版本:
pip install easyocr -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
对于最新的开发版本:
pip install git+git://github.com/jaidedai/easyocr.git
Dockerfile 描述: 由于国内网络环境因素, 此处我将官方提供的Dockerfile稍作更改。
$ cd /opt/images/easyocr && git clone https://github.com/JaidedAI/EasyOCR.git --depth=1
$ ls
Dockerfile EasyOCR
$ cat Dockerfile
# pytorch OS is Ubuntu 18.04
FROM pytorch/pytorch
LABEL DESC="EasyOCR Enviroment Build with Containerd Images"
ARG service_home="/home/EasyOCR"
# Enviroment && Software
RUN sed -i -e "s#archive.ubuntu.com#mirrors.aliyun.com#g" -e "s#security.ubuntu.com#mirrors.aliyun.com#g" /etc/apt/sources.list &&
apt-get update -y &&
apt-get install -y
libglib2.0-0
libsm6
libxext6
libxrender-dev
libgl1-mesa-dev
git
vim
# cleanup
&& apt-get autoremove -y
&& apt-get clean -y
&& rm -rf /var/lib/apt/lists
# COPY EasyOCR is Github(https://github.com/JaidedAI/EasyOCR.git)
COPY ./EasyOCR "$service_home"
# Build
RUN cd "$service_home"
&& pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
&& python setup.py build_ext --inplace -j 4
&& python -m pip install -e . 环境验证
# Windows 环境
pip freeze | findstr "easyocr"
easyocr @ file:///E:/%E8%BF%85%E9%9B%B7%E4%B8%8B%E8%BD%BD/easyocr-1.4.2-py3-none-any.whl
# Linux & 容器环境
$ pip freeze | grep "EasyOCR"
-e git+https://github.com/JaidedAI/EasyOCR.git@7a685cb8c4ba14f2bc246f89c213f1a56bbc2107#egg=easyocr
# python 命令行中使用
>>> from pprint import pprint # 方便格式化输出
>>> import easyocr
>>> reader = easyocr.Reader(['ch_sim','en'])
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
>>> result = reader.readtext('00e336dbde464c809ef1f6ea568d4621.png')
>>> pprint(result)
[([[354, 46], [444, 46], [444, 76], [354, 76]], '中国移动', 0.981803297996521),
([[477, 55], [499, 55], [499, 75], [477, 75]], '46', 0.3972922105840435),
([[533, 55], [555, 55], [555, 75], [533, 75]], '5G', 0.5360637875500641),
([[354, 76], [474, 76], [474, 104], [354, 104]],
'中国移动四 ',
0.25950584649873865),
([[489, 57], [625, 57], [625, 95], [489, 95]],
'GMl s @',
0.011500043801327683),
([[693, 55], [801, 55], [801, 95], [693, 95]], 'Q92%', 0.022083675488829613),
([[864, 60], [950, 60], [950, 92], [864, 92]], '09:03', 0.9793587315696877),
([[884, 158], [938, 158], [938, 214], [884, 214]], '@', 0.29484160211053734),
([[123, 298], [592, 298], [592, 361], [123, 361]],
'通信行程卡提供服务>',
0.6739866899213806),
([[115, 429], [384, 429], [384, 497], [115, 497]],
'通信行程卡',
0.9159307714297187),
([[153, 596], [848, 596], [848, 704], [153, 704]],
'通信大数据行程卡',
0.2522292283860262),
([[303, 723], [699, 723], [699, 785], [303, 785]],
'疫情防控;人人有责',
0.7030201163942564),
([[347, 844], [653, 844], [653, 892], [347, 892]],
'请收下绿色行程卡',
0.9120484515458063),
([[248, 950], [754, 950], [754, 1004], [248, 1004]],
'157****2966的动态行程卡',
0.9868984946820241),
([[173, 1045], [345, 1045], [345, 1105], [173, 1105]],
'更新于:',
0.972654586401667),
([[360, 1049], [829, 1049], [829, 1100], [360, 1100]],
'2022.05.2509:03:56',
0.9411191664033213),
([[110, 1670], [633, 1670], [633, 1732], [110, 1732]],
'您于前14夭内到达或途经:',
0.8531442220608394),
([[648, 1674], [788, 1674], [788, 1730], [648, 1730]],
'重庆市',
0.9605511910615995),
([[104, 1778], [898, 1778], [898, 1810], [104, 1810]],
'结果包含您在前14天内到访的国家(地区) 与停留4小时以上的国内城市',
0.6574011574316847),
([[272, 1825], [729, 1825], [729, 1863], [272, 1863]],
'色卡仅对到访地作提醒。不关联健康状况',
0.8806245499955613),
([[383, 1891], [607, 1891], [607, 1933], [383, 1933]],
'本服务联合提供',
0.9781898210349773),
([[119, 1966], [337, 1966], [337, 2006], [119, 2006]],
'CAICT 中国信通院',
0.3636917908522541),
([[435, 1963], [533, 1963], [533, 1999], [435, 1999]],
'中国电信',
0.08182162046432495),
([[624, 1966], [702, 1966], [702, 1990], [624, 1990]],
'中国移动',
0.9323447942733765),
([[812, 1966], [892, 1966], [892, 1990], [812, 1990]],
'中国联通',
0.9082608819007874),
([[441, 1993], [531, 1993], [531, 2005], [441, 2005]],
'CINA TUUUC0',
0.028013896371299665),
([[629, 1987], [701, 1987], [701, 2003], [629, 2003]],
'ChnaMobile',
0.7021787396208221),
([[815, 1989], [893, 1989], [893, 2003], [815, 2003]],
'Chnoumco',
0.19655737186726854),
([[107, 2077], [281, 2077], [281, 2119], [107, 2119]],
'证通查来了!',
0.9745880948510078),
([[467, 2075], [825, 2075], [825, 2117], [467, 2117]],
'全国移动电话卡"一证通查',
0.9208412317655043),
([[79, 2131], [269, 2131], [269, 2173], [79, 2173]],
'立即点击进入',
0.6082888941606105),
([[510, 2128], [644, 2128], [644, 2172], [510, 2172]],
'防范诈骗',
0.952128529548645),
([[663, 2129], [793, 2129], [793, 2173], [663, 2173]],
'保护你我',
0.9819014668464661)]
# 设置 --detail=0 输出更简单
>>> result = reader.readtext('00e336dbde464c809ef1f6ea568d4621.png', detail = 0) 使用说明
Note 1.在使easyocr.Reader(['ch_sim','en'])于将模型加载到内存中(可能会耗费一些时间), 并且我们需要设定默认阅读的语言列表, 可以同时使用多种语言,但并非所有语言都可以一起使用, 而通常会采用英语与其他语言联合。下面列举出可用语言及其语言对应列表 (https://www.jaided.ai/easyocr/) :
# 对于我们来说常用语言如下: # Language Code Name Simplified Chinese ch_sim Traditional Chinese ch_tra English en
温馨提示: 所选语言的模型权重将自动下载,或者您可以从模型中心 并将它们放在~/.EasyOCR/model文件夹中
Note 2.如果--gpu=True设置为True, 而机器又没有GPU支持的化将默认采用 CPU ,所以通常你会看到如下提示:
# 如果您没有 GPU,或者您的 GPU 内存不足,您可以通过添加 gpu=False. CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
Note 3.在reader.readtext(‘参数值’)函数中的参数值,可以是图片路径、也可是图像文件字节或者 OpenCV 图像对象(numpy 数组)以及互联网上图像的URL 等几种方式.
# 图像路径
reader.readtext('chinese.jpg')
# 图像URL
reader.readtext('https://www.weiyigeek.top/wechat.jpg')
# 图形字节
with open("chinese_tra.jpg", "rb") as f:
img = f.read()
result = reader.readtext(img)
# 图像作为 numpy 数组(来自 opencv)传递
img = cv2.imread('chinese_tra.jpg')
result = reader.readtext(img) Note 3.从上面结果可以看出输出结果将采用列表格式,每个项目分别代表一个边界框(四个点)、检测到的文本和可信度。
([[347, 844], [653, 844], [653, 892], [347, 892]], # 边界 1 --> 2 -> 3 -> 4 '请收下绿色行程卡', # 文本 0.9120484515458063), # 可信度
Note 4.我们也可以在命令行中直接调用easyocr。
# 语法示例:
usage: easyocr [-h] -l LANG [LANG ...] [--gpu {True,False}] [--model_storage_directory MODEL_STORAGE_DIRECTORY]
[--user_network_directory USER_NETWORK_DIRECTORY] [--recog_network RECOG_NETWORK]
[--download_enabled {True,False}] [--detector {True,False}] [--recognizer {True,False}]
[--verbose {True,False}] [--quantize {True,False}] -f FILE
[--decoder {greedy,beamsearch,wordbeamsearch}] [--beamWidth BEAMWIDTH] [--batch_size BATCH_SIZE]
[--workers WORKERS] [--allowlist ALLOWLIST] [--blocklist BLOCKLIST] [--detail {0,1}]
[--rotation_info ROTATION_INFO] [--paragraph {True,False}] [--min_size MIN_SIZE]
[--contrast_ths CONTRAST_THS] [--adjust_contrast ADJUST_CONTRAST] [--text_threshold TEXT_THRESHOLD]
[--low_text LOW_TEXT] [--link_threshold LINK_THRESHOLD] [--canvas_size CANVAS_SIZE]
[--mag_ratio MAG_RATIO] [--slope_ths SLOPE_THS] [--ycenter_ths YCENTER_THS] [--height_ths HEIGHT_THS]
[--width_ths WIDTH_THS] [--y_ths Y_THS] [--x_ths X_THS] [--add_margin ADD_MARGIN]
# 案例:
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=False
$ easyocr -l ch_sim en -f .�a1e948e90964d42b435d63c9f0aa268.png --detail=0 --gpu=True
# CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
....
请收下绿色行程卡
191****8499的动态行程卡
更新于:2022.05.2510:49:21
您于前14夭内到达或途经: 重庆市
结果包含您在前14天内到访的国家(地区)与停留4小时以上的国内城市
..... 描述: 官方提供的包的模块方法以及参数说明, 参考地址 ( https://www.jaided.ai/easyocr/documentation/ )
1.EasyOCR 的基类
easyocr.Reader(['ch_sim','en'], gpu=False, model_storage_directory="~/.EasyOCR/.",download_enabled=True, user_network_directory="~/.EasyOCR/user_network",recog_network="recog_network",detector=True,recognizer=True) # download_enabled :如果 EasyOCR 无法找到模型文件,则启用下载 # model_storage_directory: 模型数据目录的路径 # user_network_directory: 用户定义识别网络的路径 # detector : 加载检测模型到内存中 # recognizer : 加载识别模型到内存中
2.Reader 对象的主要方法, 有 4 组参数:General、Contrast、Text Detection 和 Bounding Box Merging, 其返回值为列表形式。
reader.readtext( 'chinese.jpg',image,decoder='greedy',beamWidth=5,batch_size=1,workers=0,allowlist="ch_sim",blocklist="ch_tra",detail=1,paragraph=False,min_size=10,rotation_info=[90, 180 ,270], contrast_ths = 0.1, adjust_contrast = 0.5, text_threshold = 0.7, low_text = 0.4,link_threshold = 0.4, canvas_size = 2560, mag_ratio = 1, slope_ths = 0.1, ycenter_ths = 0.5, height_ths = 0.5, width_ths = 0.5, add_margin = 0.1, x_ths = 1.0, y_ths = 0.5 ) # Parameters 1: General --batch_size : 当其值大于 1 时将使 EasyOCR 更快,但使用更多内存。 --allowlist : 强制 EasyOCR 仅识别字符子集。 对特定问题有用(例如车牌等) --detail : 将此设置为 0 以进行简单输出. --paragraph :将结果合并到段落中 --min_size: 过滤小于像素最小值的文本框 --rotation_info:允许 EasyOCR 旋转每个文本框并返回具有最高置信度分数的文本框。例如,对所有可能的文本方向尝试 [90, 180 ,270]。 # Parameters 2: Contrast --contrast_ths : 对比度低于此值的文本框将被传入模型 2 次,首先是原始图像,其次是对比度调整为“adjust_contrast”值,结果将返回具有更高置信度的那个。 --adjust_contrast : 低对比度文本框的目标对比度级别 # Parameters 3: Text Detection (from CRAFT) --text_threshold: 文本置信度阈值 --link_threshold: 链接置信度阈值 --canvas_size: 最大图像尺寸,大于此值的图像将被缩小。 --mag_ratio: 图像放大率 # Parameters 4: Bounding Box Merging height_ths (float, default = 0.5) - 盒子高度的最大差异,不应合并文本大小差异很大的框。 width_ths (float, default = 0.5) - 合并框的最大水平距离。 x_ths (float, default = 1.0) - 当段落 = True 时合并文本框的最大水平距离。 y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
3.detect method, 检测文本框的方法。
Parameters image (string, numpy array, byte) - Input image min_size (int, default = 10) - Filter text box smaller than minimum value in pixel text_threshold (float, default = 0.7) - Text confidence threshold low_text (float, default = 0.4) - Text low-bound score link_threshold (float, default = 0.4) - Link confidence threshold canvas_size (int, default = 2560) - Maximum image size. Image bigger than this value will be resized down. mag_ratio (float, default = 1) - Image magnification ratio slope_ths (float, default = 0.1) - Maximum slope (delta y/delta x) to considered merging. Low value means tiled boxes will not be merged. ycenter_ths (float, default = 0.5) - Maximum shift in y direction. Boxes with different level should not be merged. height_ths (float, default = 0.5) - Maximum different in box height. Boxes with very different text size should not be merged. width_ths (float, default = 0.5) - Maximum horizontal distance to merge boxes. add_margin (float, default = 0.1) - Extend bounding boxes in all direction by certain value. This is important for language with complex script (E.g. Thai). optimal_num_chars (int, default = None) - If specified, bounding boxes with estimated number of characters near this value are returned first. Return horizontal_list, free_list - horizontal_list is a list of regtangular text boxes. The format is [x_min, x_max, y_min, y_max]. free_list is a list of free-form text boxes. The format is [[x1,y1],[x2,y2],[x3,y3],[x4,y4]].
4.recognize method, 从文本框中识别字符的方法,如果未给出 Horizontal_list 和 free_list,它将整个图像视为一个文本框。
Parameters image (string, numpy array, byte) - Input image horizontal_list (list, default=None) - see format from output of detect method free_list (list, default=None) - see format from output of detect method decoder (string, default = 'greedy') - options are 'greedy', 'beamsearch' and 'wordbeamsearch'. beamWidth (int, default = 5) - How many beam to keep when decoder = 'beamsearch' or 'wordbeamsearch' batch_size (int, default = 1) - batch_size>1 will make EasyOCR faster but use more memory workers (int, default = 0) - Number thread used in of DataLoader allowlist (string) - Force EasyOCR to recognize only subset of characters. Useful for specific problem (E.g. license plate, etc.) blocklist (string) - Block subset of character. This argument will be ignored if allowlist is given. detail (int, default = 1) - Set this to 0 for simple output paragraph (bool, default = False) - Combine result into paragraph contrast_ths (float, default = 0.1) - Text box with contrast lower than this value will be passed into model 2 times. First is with original image and second with contrast adjusted to 'adjust_contrast' value. The one with more confident level will be returned as a result. adjust_contrast (float, default = 0.5) - target contrast level for low contrast text box Return list of results
描述: 公司有业务需求做一个行程码识别, 当前是调用某云的文字识别接口来识别行程码, 而其按照调用次数进行计费, 所以为了节约成本就要Python参考了Github上大佬的们项目, 截取部分函数,并使用Flask Web 框架进行封装,从而实现通过网页进行请求调用,并返回JSON字符串。
项目源码Github地址:https://github.com/WeiyiGeek/SecOpsDev/tree/master/Project/Python/EasyOCR/Travelcodeocr
项目实践 步骤 01.安装flask及其依赖模块的。
pip install flask -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
步骤 02.项目路径以及图片路径 D:StudyProject
PS D:StudyProject> ls
目录: D:StudyProject
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2022/5/25 15:59 img
d----- 2022/5/26 21:17 templates
-a---- 2022/5/25 19:34 3966 setup.py 步骤 03.基于Flask web框架下进行调用EasyOCR执行图片文字识别的python代码(v1 版本).
# -*- coding: utf-8 -*-
# ####################################################################
# Author: WeiyiGeek
# Description: 基于easyocr实现大数据通信行程卡图片识别信息获取-Flask项目。
# Time: 2022年5月25日 17点31分
# Blog: https://www.weiyigeek.top
# Email: master@weiyigeek.top
# ====================================================================
# 环境依赖与模块安装, 建议 Python 3.8.x 的环境下进行
# pip install flask
# pip install easyocr
# ====================================================================
# 行程码有绿色、黄色、橙色、红色四种颜色。
# 1、红卡:行程中的中高风险地市将标记为红色字体作提示。
# 2、橙卡:新冠肺炎确诊或疑似患者的密切接触者。
# 3、黄卡:海外国家和地区。
# 4、绿卡:其他地区。行程卡结果包含在前14天内到访的国家(地区)与停留4小时以上的国内城市。色卡仅对到访地作提醒,不关联健康状况。
# #####################################################################
import os,sys
import cv2
import re
import glob
import json
import easyocr
from flask import Flask, jsonify, request,render_template
from datetime import datetime
from werkzeug.utils import secure_filename
import numpy as np
import collections
app = Flask(__name__)
# 项目运行路径与行程码图片路径定义
RUNDIR = None
IMGDIR = None
colorDict= {"red": "红色", "red1": "红色", "orange": "橙色", "yellow": "黄色", "green": "绿色"}
def getColorList():
"""
函数说明: 定义字典存放 HSV 颜色分量上下限 (HSV-RGB)
例如:{颜色: [min分量, max分量]}
{'red': [array([160, 43, 46]), array([179, 255, 255])]}
返回值: 专门的容器数据类型,提供Python通用内置容器、dict、list、set和tuple的替代品。
"""
dict = collections.defaultdict(list)
# 红色
lower_red = np.array([156, 43, 46])
upper_red = np.array([180, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict['red']=color_list
# 红色2
lower_red = np.array([0, 43, 46])
upper_red = np.array([10, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict['red2'] = color_list
# 橙色
lower_orange = np.array([11, 43, 46])
upper_orange = np.array([25, 255, 255])
color_list = []
color_list.append(lower_orange)
color_list.append(upper_orange)
dict['orange'] = color_list
# 黄色
lower_yellow = np.array([26, 43, 46])
upper_yellow = np.array([34, 255, 255])
color_list = []
color_list.append(lower_yellow)
color_list.append(upper_yellow)
dict['yellow'] = color_list
# 绿色
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
color_list = []
color_list.append(lower_green)
color_list.append(upper_green)
dict['green'] = color_list
return dict
def getTravelcodeColor(img_np):
"""
函数说明: 利用阈值返回行程码主页颜色
参数值: cv2.imread() 读取的图像对象(np数组)
返回值: 行程卡颜色{红、橙、绿}
"""
hsv = cv2.cvtColor(img_np, cv2.COLOR_BGR2HSV)
maxsum = -100
color = None
color_dict = getColorList()
for d in color_dict:
mask = cv2.inRange(hsv,color_dict[d][0],color_dict[d][1])
# cv2.imwrite(os.path.join(os.path.abspath(os.curdir),"img",d+'.jpg') ,mask)
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
binary = cv2.dilate(binary,None,iterations=2)
cnts, hiera = cv2.findContours(binary.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
sum = 0
for c in cnts:
sum+=cv2.contourArea(c)
if sum > maxsum :
maxsum = sum
color = d
return colorDict[color]
def information_filter(file_path,img_np,text_str):
"""
函数说明: 提出ocr识别的行程码
参数值:字符串,文件名称
返回值:有效信息组成的字典
"""
# 健康码字段
try:
re_healthcode = re.compile('请收下(.{,2})行程卡')
healthcode = re_healthcode.findall(text_str)[0]
except Exception as _:
healthcode = getTravelcodeColor(img_np) # 文字无法识别时采用图片颜色识别
print("[*] Get Photo Color = ",healthcode)
# 电话字段
re_phone = re.compile('[0-9]{3}*{4}[0-9]{4}')
phone_str = re_phone.findall(text_str)[0]
# 日期字段
re_data = re.compile('2022.[0-1][0-9].[0-3][0-9]')
data_str = re_data.findall(text_str)[0]
# 时间字段
re_time = re.compile('[0-9][0-9]:[0-9][0-9]:[0-9][0-9]')
time_str = re_time.findall(text_str)[0]
# 地区城市字段
citys_re = re.compile('到达或途经:(.+)结果包含')
citys_str = citys_re.findall(text_str)[0].strip().split('(')[0]
result_dic = {"status": "succ", "file": file_path ,"类型": healthcode, "电话": phone_str, "日期": data_str, "时间": time_str, "行程": citys_str}
print("�33[032m",result_dic,"�33[0m")
return result_dic
def getTravelcodeInfo(filename, img_np):
"""
函数说明: 返回以JSON字符串格式过滤后结果
参数值:文件名称,图像作为 numpy 数组(来 opencv传递
返回值:JSON字符串格式
"""
# 灰度处理
img_gray = cv2.cvtColor(img_np, cv2.COLOR_BGR2GRAY)
# 阈值二进制 - > 127 设置为255(白),否则0(黑) -> 淡白得更白,淡黑更黑
_,img_thresh = cv2.threshold(img_gray,180,255,cv2.THRESH_BINARY)
# 图像 OCR 识别
text = reader.readtext(img_thresh, detail=0, batch_size=10)
result_dic = information_filter(filename, img_np, "".join(text))
return result_dic
# Flask 路由 - 首页
@app.route('/')
@app.route('/index')
def Index():
return "<h4 style='text-algin:center'>https://www.weiyigeek.top</h4><script>window.location.href='https://www.weiyigeek.top'</script>"
# Flask 路由 - /tools/ocr
@app.route('/tools/ocr',methods=["GET"])
def Travelcodeocr():
"""
请求路径: /tools/ocr
请求参数: (/tools/ocr?file=20220520/test.png, /tools/ocr?dir=20220520)
"""
filename = request.args.get("file")
dirname = request.args.get("dir")
if (filename):
img_path = os.path.join(IMGDIR, filename)
if (os.path.exists(img_path)):
print(img_path) # 打印路径
img_np = cv2.imread(img_path)
try:
result_dic_succ = getTravelcodeInfo(filename,img_np)
except Exception as err:
print("�33[31m"+ img_path + " -->> " + str(err) + "�33[0m")
return json.dumps({"status":"err", "img": filename}).encode('utf-8'), 200, {"Content-Type":"application/json"}
return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
return jsonify({"status": "err","msg": "文件"+img_path+"路径不存在."})
elif (dirname and os.path.join(IMGDIR, dirname)):
result_dic_all = []
result_dic_err = []
img_path_all = glob.iglob(os.path.join(os.path.join(IMGDIR,dirname)+"/*.[p|j]*g")) # 正则匹配 png|jpg|jpeg 后缀的后缀,返回的是迭代器。
for img_path in img_path_all:
print(img_path) # 打印路径
img_np = cv2.imread(img_path)
try:
result_dic_succ = getTravelcodeInfo(os.path.join(dirname,os.path.basename(img_path)),img_np)
except Exception as err:
print("�33[31m"+ img_path + " -->> " + str(err) + "�33[0m") # 输出识别错误的图像
result_dic_err.append(img_path)
continue
# 成功则加入到List列表中
result_dic_all.append(result_dic_succ)
res_succ_json=json.dumps(result_dic_all, ensure_ascii=False)
res_err_json=json.dumps(result_dic_err, ensure_ascii=False)
with open(os.path.join(IMGDIR, dirname, dirname + "-succ.json"),'w') as succ:
succ.write(res_succ_json)
with open(os.path.join(IMGDIR, dirname, dirname + "-err.json"),'w') as error:
error.write(res_err_json)
return res_succ_json.encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
return jsonify({"status": "err","msg": "请求参数有误!"})
# Flask 路由 - /tools/upload/ocr
@app.route('/tools/upload/ocr',methods=["GET","POST"])
def TravelcodeUploadocr():
if request.method == 'POST':
unix = datetime.now().strftime('%Y%m%d-%H%M%S%f')
f = request.files['file']
if (f.mimetype == 'image/jpeg' or f.mimetype == 'image/png'):
filedate = unix.split("-")[0]
filesuffix = f.mimetype.split("/")[-1]
uploadDir = os.path.join('img',filedate)
# 判断上传文件目录是否存在
if (not os.path.exists(uploadDir)):
os.makedirs(uploadDir)
img_path = os.path.join(uploadDir,secure_filename(unix+"."+filesuffix)) # 图片路径拼接
print(img_path) # 打印路径
f.save(img_path) # 写入图片
# 判断上传文件是否存在
if (os.path.exists(img_path)):
img_np = cv2.imread(img_path)
try:
result_dic_succ = getTravelcodeInfo(os.path.join(filedate,os.path.basename(img_path)),img_np)
except Exception as err:
print("�33[31m"+ err + "�33[0m")
return json.dumps({"status":"err", "img": img_path}).encode('utf-8'), 200, {"Content-Type":"application/json"}
return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
return jsonify({"status": "err","msg": "文件"+img_path+"路径不存在!"})
else:
return jsonify({"status": "err","msg": "不能上传除 jpg 与 png 格式以外的图片"})
else:
return render_template('index.html')
# 程序入口
if __name__ == '__main__':
try:
RUNDIR = sys.argv[1]
IMGDIR = sys.argv[2]
except Exception as e:
print("[*] Uage:"+ sys.argv[0] + " RUNDIR IMGDIR")
print("[*] Default:"+ sys.argv[0] + " ./ ./img" + "
" )
RUNDIR = os.path.abspath(os.curdir)
IMGDIR = os.path.join(RUNDIR,"img")
# finally:
# if os.path.exists(RUNDIR):
# RUNDIR = os.path.abspath(os.curdir)
# if os.path.exists(IMGDIR):
# IMGDIR = os.path.join(RUNDIR,"img")
# 使用easyocr模块中的Reader方法, 设置识别中英文两种语言
reader = easyocr.Reader(['ch_sim', 'en'], gpu=False)
# 使用Flask模块运行web
app.run(host='0.0.0.0', port=8000, debug=True) 步骤 03.运行该脚本并使用浏览进行指定行程码图片路径以及识别提取。
python .setup.py # Using CPU. Note: This module is much faster with a GPU. # * Serving Flask app 'index' (lazy loading) # * Environment: production # WARNING: This is a development server. Do not use it in a production deployment. # Use a production WSGI server instead. # * Debug mode: on # * Running on all addresses (0.0.0.0) # WARNING: This is a development server. Do not use it in a production deployment. # * Running on http://127.0.0.1:8000 # * Running on http://10.20.172.106:8000 (Press CTRL+C to quit) # * Restarting with stat # Using CPU. Note: This module is much faster with a GPU. # * Debugger is active! # * Debugger PIN: 115-313-307
温馨提示: 从上面的Python脚本中可以看出我们可使用file参数指定图片路径或者使用dir参数指定行程码图片存放目录(默认在img目录下的子目录)。
例如,获取单个行程码图片信息,我本地浏览器访问http://127.0.0.1:8000/tools/ocr?file=20220530/00e336dbde464c809ef1f6ea568d4621.png地址,将会返回如下JSON字符串。
D:StudyProjectimg20220530�0e336dbde464c809ef1f6ea568d4621.png
127.0.0.1 - - [01/Jun/2022 16:58:58] "GET /tools/upload/ocr HTTP/1.1" 200 -
{'status': 'succ', 'file': '20220530�0e336dbde464c809ef1f6ea568d4621.png', '类型': '绿色', '电话': '157****2966', '日期': '2022.05.25', '时间': '09:03:56', '行程': '重庆市'} 例如,获取多个行程码图片识别信息,我本地浏览器访问http://127.0.0.1:8000/tools/ocr?dir=20220530地址,将会返回如下图所示结果。

WeiyiGeek.批量获取行程码图片信息
例如, 我们可以上传并识别行程码图片信息,本地浏览器访问http://127.0.0.1:8000/tools/upload/ocr地址,将会返回如下图所示结果。

WeiyiGeek.上传并识别行程码图片信息
温馨提示: 如下环境依赖与模块安装, 建议 Python 3.8.x 的环境下进行.
# pip install flask # pip install easyocr # pip install gevent # pip3 install gevent-websocket
mylogger.py
import os
import logging
from logging.handlers import TimedRotatingFileHandler
LOG_PATH = "log"
LOG_INFO = '_info.log'
LOG_ERROR = '_error.log'
class logger:
def __init__(self, prefix_name = "flask"):
if (not os.path.exists(LOG_PATH)):
os.makedirs(LOG_PATH)
self.prefix = prefix_name
# 创建logger日志对象
self.info_logger = logging.getLogger("info")
self.error_logger = logging.getLogger("error")
# 日志的最低输出级别
self.info_logger.setLevel(logging.DEBUG)
self.error_logger.setLevel(logging.ERROR)
# 日志格式化
self.format = logging.Formatter('[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s] : %(message)s')
# 按照时间切割文件 Handler 配置
TimeFileHandlerINFO = TimedRotatingFileHandler("%s/%s%s" % (LOG_PATH, prefix_name, LOG_INFO), when='MIDNIGHT', encoding="utf-8", backupCount=8760, delay=True)
TimeFileHandlerINFO.suffix = "%Y-%m-%d.log"
TimeFileHandlerERROR = TimedRotatingFileHandler("%s/%s%s" % (LOG_PATH, prefix_name, LOG_ERROR), when='MIDNIGHT', encoding="utf-8", backupCount=8760, delay=True)
TimeFileHandlerERROR.suffix = "%Y-%m-%d.log"
LoggerStream = logging.StreamHandler()
# 设置日志格式化
TimeFileHandlerINFO.setFormatter(self.format)
TimeFileHandlerERROR.setFormatter(self.format)
LoggerStream.setFormatter(self.format)
# 添加设置的句柄
self.info_logger.addHandler(TimeFileHandlerINFO)
# self.info_logger.addHandler(LoggerStream)
self.error_logger.addHandler(TimeFileHandlerERROR)
# self.error_logger.addHandler(LoggerStream)
def debug(self, msg, *args, **kwargs):
self.info_logger.debug(msg, *args, **kwargs)
def info(self, msg, *args, **kwargs):
self.info_logger.info(msg, *args, **kwargs)
def warn(self, msg, *args, **kwargs):
self.info_logger.warning(msg, *args, **kwargs)
def error(self, msg, *args, **kwargs):
self.error_logger.error(msg, *args, **kwargs)
def fatal(self, msg, *args, **kwargs):
self.error_logger.fatal(msg, *args, **kwargs)
def critical(self, msg, *args, **kwargs):
self.error_logger.critical(msg, *args, **kwargs) setup.py
# -*- coding: utf-8 -*-
# ####################################################################
# Author: WeiyiGeek
# Description: 基于easyocr实现大数据通信行程卡图片识别信息获取-Flask项目。
# Time: 2022年5月25日 17点31分
# Blog: https://www.weiyigeek.top
# Email: master@weiyigeek.top
# Modity: 2022年8月10日 14点53分
# ====================================================================
# 环境依赖与模块安装, 建议 Python 3.8.x 的环境下进行
# pip install flask
# pip install easyocr
# pip install gevent
# pip3 install gevent-websocket
# ====================================================================
# 行程码有绿色、黄色、橙色、红色四种颜色。
# 1、红卡:行程中的中高风险地市将标记为红色字体作提示。
# 2、橙卡:新冠肺炎确诊或疑似患者的密切接触者。
# 3、黄卡:海外国家和地区。
# 4、绿卡:其他地区。行程卡结果包含在前14天内到访的国家(地区)与停留4小时以上的国内城市。色卡仅对到访地作提醒,不关联健康状况。
# #####################################################################
import os
import cv2
import re
import glob
import json
import easyocr
import logging
import collections
import argparse
from flask import Flask, jsonify, request,render_template
from datetime import datetime
from werkzeug.utils import secure_filename
import numpy as np
from gevent import pywsgi
from mylogger import logger
from logging.handlers import RotatingFileHandler
from geventwebsocket.handler import WebSocketHandler
app = Flask(__name__)
# 运行参数
parser = argparse.ArgumentParser(description="本程序利用easyocr进行图像文字识别,实现行程码与健康码的识别",prog='Easyocr')
parser.add_argument('--rundir',dest="rundir", type=str, help="指定程序运行目录", required=False, default="./")
parser.add_argument('--imgdir',dest="imgdir", type=str, help="指定图像存放目录", required=False, default="./img")
parser.add_argument('--gpu',dest="gpu", type=bool, help="指定是否使用GPU执行计算(缺省: Flase)", required=False, default=False)
parser.add_argument('--ip',dest="ip", type=str, help="指定服务监听网卡(缺省: 0.0.0.0)", required=False, default="0.0.0.0")
parser.add_argument('--port',dest="port", type=int, help="指定服务的端口(缺省: 8000)", required=False, default=8000)
args = parser.parse_args()
# 常量定义
RUNDIR = args.rundir
IMGDIR = args.imgdir
codeDict = {"green": "绿码", "yellow": "黄码", "red": "红码", "other": "暂时无法确认"}
colorDict = {"red": "红色", "red1": "红色", "orange": "橙色", "yellow": "黄色", "green": "绿色"}
def getColorList():
"""
函数说明: 定义字典存放 HSV 颜色分量上下限 (HSV-RGB)
例如:{颜色: [min分量, max分量]}
{'red': [array([160, 43, 46]), array([179, 255, 255])]}
返回值: 专门的容器数据类型,提供Python通用内置容器、dict、list、set和tuple的替代品。
"""
dict = collections.defaultdict(list)
# 红色
lower_red = np.array([156, 43, 46])
upper_red = np.array([180, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict['red']=color_list
# 红色2
lower_red = np.array([0, 43, 46])
upper_red = np.array([10, 255, 255])
color_list = []
color_list.append(lower_red)
color_list.append(upper_red)
dict['red2'] = color_list
# 橙色
lower_orange = np.array([11, 43, 46])
upper_orange = np.array([25, 255, 255])
color_list = []
color_list.append(lower_orange)
color_list.append(upper_orange)
dict['orange'] = color_list
# 黄色
lower_yellow = np.array([26, 43, 46])
upper_yellow = np.array([34, 255, 255])
color_list = []
color_list.append(lower_yellow)
color_list.append(upper_yellow)
dict['yellow'] = color_list
# 绿色
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
color_list = []
color_list.append(lower_green)
color_list.append(upper_green)
dict['green'] = color_list
return dict
def getTravelcodeColor(img_np):
"""
函数说明: 利用阈值返回行程码主页颜色
参数值: cv2.imread() 读取的图像对象(np数组)
返回值: 行程卡颜色{红、橙、绿}
"""
hsv = cv2.cvtColor(img_np, cv2.COLOR_BGR2HSV)
maxsum = -100
color = None
color_dict = getColorList()
for d in color_dict:
mask = cv2.inRange(hsv,color_dict[d][0],color_dict[d][1])
# cv2.imwrite(os.path.join(os.path.abspath(os.curdir),"img",d+'.jpg') ,mask)
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
binary = cv2.dilate(binary,None,iterations=2)
cnts, hiera = cv2.findContours(binary.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
sum = 0
for c in cnts:
sum+=cv2.contourArea(c)
if sum > maxsum :
maxsum = sum
color = d
return colorDict[color]
def health_filter(file_path, img_np ,text_str):
"""
函数说明: ocr识别的健康码
参数值:字符串,文件名称
返回值:有效信息组成的字典
"""
# 健康码字段
try:
result_dic = None
for i in codeDict:
if (text_str.find(codeDict[i]) > 0) :
result_dic = {"code": 200,"msg" : "成功获取健康码图片数据为有健康码状态.", "data" :{"file": file_path ,"type": codeDict[i]}}
if ( i == "other" ):
result_dic = {"code": 200,"msg" : "成功获取健康码图片数据为无码.", "data" :{"file": file_path ,"type": "无码"}}
break
else:
result_dic = {"code": 0,"msg" : "识别健康码图片数据未在字典范围内.", "data" :{"file": file_path ,"type": "未知"}}
return result_dic
except Exception as _:
# healthcode = getTravelcodeColor(img_np) # 文字无法识别时采用图片颜色识别
# print("[*] Get Photo Color = ",healthcode)
result_dic = {"code": 0,"msg" : "识别健康码图片数据失败.", "data" :{"file": file_path ,"type": "未知"}}
return result_dic
def getHealthCodeInfo(filename, img_np):
"""
函数说明: 获取健康码信息
参数值:文件名称, 图像作为 numpy 数组进行opencv传递
返回值:返回以JSON字符串格式过滤后结果
"""
# 灰度处理
# img_gray = cv2.cvtColor(img_np, cv2.COLOR_BGR2GRAY)
# 阈值二进制 - > 127 设置为255(白),否则0(黑) -> 淡白得更白,淡黑更黑
# _,img_thresh = cv2.threshold(img_gray,176,255,cv2.THRESH_BINARY)
# 图像 OCR 识别
text = reader.readtext(img_np, detail=0, batch_size=64)
result_dic = health_filter(filename, img_np, "".join(text))
return result_dic
def travel_filter(file_path,img_np,text_str):
"""
函数说明: ocr识别的行程码
参数值:字符串,文件名称
返回值:有效信息组成的字典
"""
# 健康码字段
try:
re_healthcode = re.compile('请收下(.{,2})行程卡')
healthcode = re_healthcode.findall(text_str)[0]
except Exception as _:
healthcode = getTravelcodeColor(img_np) # 文字无法识别时采用图片颜色识别
print("[*] Get Photo Color = ",healthcode)
# 电话字段
re_phone = re.compile('[0-9]{3}*{4}[0-9]{4}')
phone_str = re_phone.findall(text_str)[0]
# 日期字段
re_data = re.compile('2022.[0-1][0-9].[0-3][0-9]')
data_str = re_data.findall(text_str)[0]
# 时间字段
re_time = re.compile('[0-9][0-9]:[0-9][0-9]:[0-9][0-9]')
time_str = re_time.findall(text_str)[0]
# 地区城市字段
citys_re = re.compile('到达或途经:(.+)结果包含')
citys_str = citys_re.findall(text_str)[0].strip().split('(')[0]
result_dic = {"code": 200,"msg" : "成功获取行程码数据.", "data" :{"file": file_path ,"type": healthcode, "phone": phone_str, "date": data_str, "time": time_str, "travel": citys_str}}
return result_dic
def getTravelCodeInfo(filename, img_np):
"""
函数说明: 返回以JSON字符串格式过滤后结果
参数值:文件名称,图像作为numpy数组进行opencv传递
返回值:JSON字符串格式
"""
# 灰度处理
img_gray = cv2.cvtColor(img_np, cv2.COLOR_BGR2GRAY)
# 阈值二进制 - > 127 设置为255(白),否则0(黑) -> 淡白得更白,淡黑更黑
_,img_thresh = cv2.threshold(img_gray,176,255,cv2.THRESH_BINARY)
# 图像 OCR 识别
text = reader.readtext(img_thresh, detail=0, batch_size=64)
result_dic = travel_filter(filename, img_np, "".join(text))
return result_dic
# Flask 路由 - 首页
@app.route('/')
@app.route('/index')
def Index():
return "<h4 style='text-algin:center'>https://www.weiyigeek.top/wechat.html?key=%E6%AC%A2%E8%BF%8E%E5%85%B3%E6%B3%A8</h4><br/><b style='text-algin:center'>/api/v1/ocr/health?action=jkm&file=20220520/test.png <br> /api/v1/ocr/health?action=xcm&file=20220520/test.png </b>"
# Flask 路由
@app.route('/api/v1/ocr/health',methods=["GET"])
def Travelcodeocr():
"""
请求路径: /api/v1/ocr/health
请求参数: (/api/v1/ocr/health?action=['jkm','xcm']&file=20220520/test.png, /tools/ocr?dir=20220520)
"""
action = request.args.get("action")
filename = request.args.get("file")
dirname = request.args.get("dir")
if (action and filename):
img_path = os.path.join(IMGDIR, filename)
if (os.path.exists(img_path)):
# 打印路径
log.info("图像路径: "+ img_path)
img_np = cv2.imread(img_path)
try:
if (action == "jkm"):
result_dic_succ = getHealthCodeInfo(filename,img_np)
else:
result_dic_succ = getTravelCodeInfo(filename,img_np)
except Exception as err:
result_dic_err = {"code": 0,"msg" : "图像数据获取异常, 请调用第三方接口识别.","data" :{"action": action,"file": filename ,"type": "未知"}}
log.error(str(err) + "-" + str(result_dic_err))
return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
log.info(result_dic_succ)
return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
result_dic_err={"code": 0,"msg": "图像数据获取异常, 文件"+filename+"或者路径不对, 请检查."}
log.error(str(result_dic_err))
return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
elif (action and dirname and os.path.join(IMGDIR, dirname)):
result_dic_all = []
result_dic_err = []
img_path_all = glob.iglob(os.path.join(os.path.join(IMGDIR,dirname)+"/*.[p|j]*g")) # 正则匹配 png|jpg|jpeg 后缀的后缀,返回的是迭代器。
for img_path in img_path_all:
img_np = cv2.imread(img_path)
try:
result_dic_succ = getTravelCodeInfo(os.path.join(dirname,os.path.basename(img_path)),img_np)
except Exception as err:
print("�33[31m"+ img_path + " -->> " + str(err) + "�33[0m") # 输出识别错误的图像
result_dic_err.append(img_path)
continue
# 成功则加入到List列表中
result_dic_all.append(result_dic_succ)
res_succ_json=json.dumps(result_dic_all, ensure_ascii=False)
res_err_json=json.dumps(result_dic_err, ensure_ascii=False)
with open(os.path.join(IMGDIR, dirname, dirname + "-succ.json"),'w') as succ:
succ.write(res_succ_json)
with open(os.path.join(IMGDIR, dirname, dirname + "-err.json"),'w') as error:
error.write(res_err_json)
return res_succ_json.encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
return jsonify({"code": "0","msg": "请求参数有误!"})
# Flask 路由 - /tools/upload/ocr
@app.route('/tools/upload/ocr',methods=["GET","POST"])
def TravelcodeUploadocr():
if request.method == 'POST':
unix = datetime.now().strftime('%Y%m%d-%H%M%S%f')
f = request.files['file']
if (f.mimetype == 'image/jpeg' or f.mimetype == 'image/png'):
filedate = unix.split("-")[0]
filesuffix = f.mimetype.split("/")[-1]
uploadDir = os.path.join('img',filedate)
# 判断上传文件目录是否存在
if (not os.path.exists(uploadDir)):
os.makedirs(uploadDir)
# 图片路径拼接与写入图片
img_path = os.path.join(uploadDir,secure_filename(unix+"."+filesuffix))
f.save(img_path)
# log.info("上传路径:" + img_path)
# 判断上传文件是否存在
if (os.path.exists(img_path)):
img_np = cv2.imread(img_path)
try:
result_dic_succ = getTravelCodeInfo(os.path.join(filedate,os.path.basename(img_path)),img_np)
except Exception as err:
result_dic_err = {"code": 0,"msg" : "图像数据获取异常, 请调用第三方接口识别.","data" :{"action": "upload","img_path": img_path ,"type": "未知"}}
log.error(str(err) + "-" + str(result_dic_err))
return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
log.info(str(result_dic_succ))
return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
result_dic_err={"code": 0,"msg": "图像数据获取异常, 文件"+img_path+"或者路径不对, 请检查."}
log.error(str(result_dic_err))
return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8'), 200, {"Content-Type":"application/json"}
else:
return jsonify({"status": "err","msg": "不能上传除 jpg 与 png 格式以外的图片"})
else:
return render_template('index.html')
# 程序入口
if __name__ == '__main__':
log = logger("app")
# 全局设置日志的记录等级,调试INFO级
logging.basicConfig(level=logging.INFO)
# 创建日志记录器,指明日志保存的路径、每个日志文件的最大大小、保存的日志文件个数上限 (100 兆)
file_log_handler = RotatingFileHandler("log/console.log", maxBytes=1024 * 1024 * 100, backupCount=10, encoding="utf-8")
# 创建日志记录的格式 日志等级 输入日志信息的文件名 行数 日志信息
formatter = logging.Formatter('%(levelname)s - %(message)s')
# 为刚创建的日志记录器设置日志记录格式
file_log_handler.setFormatter(formatter)
# 为全局的日志工具对象(flask app使用的)添加日志记录器
logging.getLogger().addHandler(file_log_handler)
# try:
# RUNDIR = sys.argv[1]
# IMGDIR = sys.argv[2]
# except Exception as e:
# print("[*] Uage:"+ sys.argv[0] + " RUNDIR IMGDIR")
# print("[*] Default:"+ sys.argv[0] + " ./ ./img" + "
" )
# RUNDIR = os.path.abspath(os.curdir)
# IMGDIR = os.path.join(RUNDIR,"img")
# finally:
# if os.path.exists(RUNDIR):
# RUNDIR = os.path.abspath(os.curdir)
# if os.path.exists(IMGDIR):
# IMGDIR = os.path.join(RUNDIR,"img")
# 使用easyocr模块中的Reader方法, 设置识别中英文两种语言
reader = easyocr.Reader(['ch_sim', 'en'], gpu=args.gpu, detector=True, recognizer=True)
# 使用原生app运行web(单线程)
# app.run(host='0.0.0.0', port=8000, debug=False)
# 使用WSGIServer多线程(实际上是异步)
server = pywsgi.WSGIServer((args.ip, args.port), app, handler_class=WebSocketHandler)
server.serve_forever() 代码执行:
问题1.通过pip install 安装easyocr离线的whl包是报ERROR: No matching distribution found for torch
错误信息:
pip install ./easyocr-1.4.2-py3-none-any.whl -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com ERROR: Could not find a version that satisfies the requirement torch (from easyocr) (from versions: none) ERROR: No matching distribution found for torch
解决办法: python.exe -m pip install --upgrade pip
问题2.在Python3.7的环境中安装easyocr依赖的torch模块的whl安装包报not a supported wheel on this platform.错误
错误信息:
$ pip install torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/ WARNING: Requirement 'torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl' looks like a filename, but the file does not exist Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple/ ERROR: torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl is
错误原因: 平台与下载的whl不符合, 此处我遇到的问题明显不是这个导致的,百度后我想是由于pip版本与python版本、以及系统平台联合导致。
解决办法:
# 解决1.假如,你是linux你可以通过 https://download.pytorch.org/whl/torch_stable.html 找到所需版本。 文件名解释:cpu或显卡/文件名-版本号-python版本-应该是编译格式-平台-cpu类型(intel也选amd64) # torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl # 解决2.将 torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl 更名为 torch-1.8.0+cpu-cp37-cp37m-win32.whl
问题3.在执行调用torch模块的py脚本时报`Error loading “D:**libsite-packages orchlibasmjit.dll” or one of its dependencies.`错误**
错误信息:
Microsoft Visual C++ redistributable is not installed, this may lead to the DLL load failure. It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe Traceback (most recent call last): ..... OSError: [WinError 193] <no description> Error loading "D:Program Files (x86)Python37-32libsite-packages orchlibasmjit.dll" or one of its dependencies.
解决办法: 在你的电脑上下载安装 https://aka.ms/vs/16/release/vc_redist.x64.exe 缺少的C++运行库,重启电脑。
问题4.在安装opencv_python_headless进行依赖模块安装时报ERROR: No matching distribution found for torchvision>=0.5错误
错误信息:
Using cached https://mirrors.aliyun.com/pypi/packages/a4/0a/39b102047bcf3b1a58ee1cc83a9269b2a2c4c1ab3062a65f5292d8df6594/opencv_python_headless-4.5.4.60-cp37-cp37m-win32.whl (25.8 MB) ERROR: Could not find a version that satisfies the requirement torchvision>=0.5 (from easyocr) (from versions: 0.1.6, 0.1.7, 0.1.8, 0.1.9, 0.2.0, 0.2.1, 0.2.2, 0.2.2.post2, 0.2.2.post3) ERROR: No matching distribution found for torchvision>=0.5
解决办法: 如果你的 python 版本为3.7.x,那么你只能安装 torch 1.5 和 torchvision0.6。
问题5.在执行easyocr文字识别时出现Downloading detection model, please wait. This may take several minutes depending upon your network connection.提示
问题描述: 在首次使用时会自动下载EasyOCR模块所需的模型, 而由于国内网络环境,通常会报出超时错误,此时我们提前从官网下载其所需的数据模型,并安装在指定目录中。
模型下载: https://www.jaided.ai/easyocr/modelhub/
# 主要下载以下模型(如有其它需要请自行选择下载) english_g2 : https://github.com/JaidedAI/EasyOCR/releases/download/v1.3/english_g2.zip zh_sim_g2 : https://github.com/JaidedAI/EasyOCR/releases/download/v1.3/zh_sim_g2.zip CRAFT : https://github.com/JaidedAI/EasyOCR/releases/download/pre-v1.1.6/craft_mlt_25k.zip # 模型安装位置 # windows C:UsersWeiyiGeek.EasyOCRmodel # Linux /home/weiyigeek/.EasyOCRmodel