Hadoop生态圈中HDFS一直用来保存底层数据。Hbase作为一款Nosql也是Hadoop生态圈的核心组件;它海量的存储能力;优秀的随机读写能力;能够处理一些HDFS不足的地方。
Clickhouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。能够使用SQL查询实时生成分析数据报告。它同样拥有优秀的数据存储能力。
Apache Kudu是Cloudera Manager公司16年发布的新型分布式存储系统;结合CDH和Impala使用可以同时解决随机读写和sql化数据分析的问题。分别弥补HDFS静态存储和Hbase Nosql的不足。
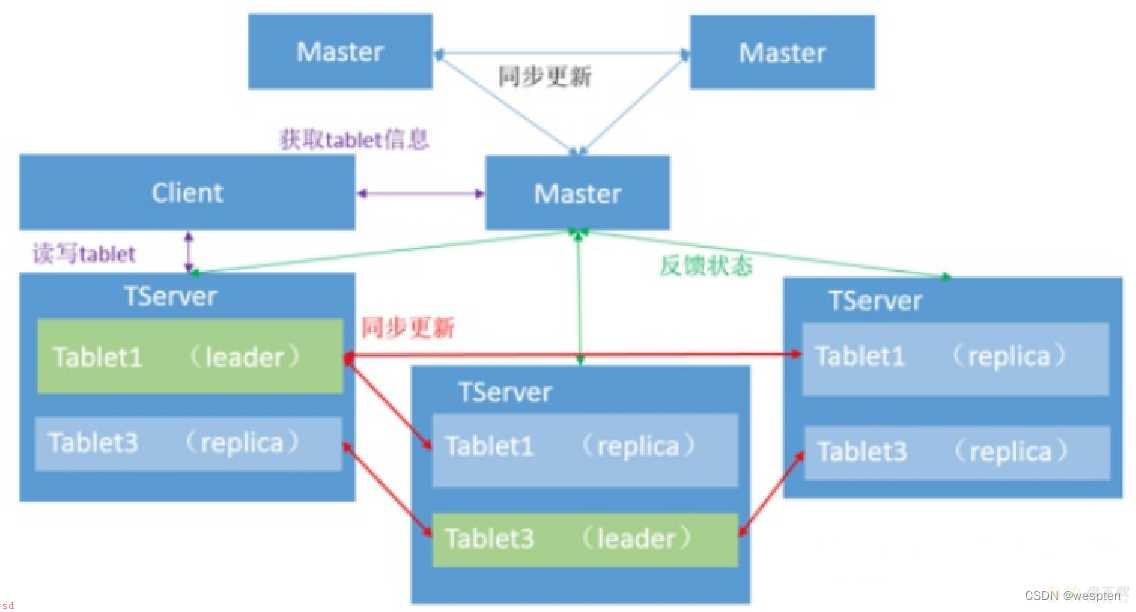
接着说一下Hbase与Kudu;可以说是Kudu师承Hbase;架构是类似的master-slave结构。
Hbase的物理模型是master和regionserver;regionserver存储的是region;region里边很有很多store;一个store对应一个列簇;一个store中有一个memstore和多个storefile;store的底层是hfile;hfile是hadoop的二进制文件;其中HFile和HLog是Hbase两大文件存储格式;HFile用于存储数据;HLog保证可以写入到HFile中。
Kudu的物理模型是master和tserver;其中table根据hash和range分区;分为多个tablet存储到tserver中;tablet分为leader和follower;leader负责写请求;follower负责读请求;总结来说;一个ts可以服务多个tablet;一个tablet可以被多个ts服务;基于tablet的分区;最低为2个分区;。
Clickhouse的特点在于它较快的查询性能;虽然也能存储数据;但并不是他的强项;而且Clickhouse还不能update/delete数据。
安装部署方式对比;
具体的安装步骤不过多赘述;这里只简要比较安装过程中需要依赖的外部组件。
1;Habse 安装
依赖HDFS作为底层存储插件 依赖Zookeeper作为元数据存储插件。
2;Kudu 安装
依赖Impala作为辅助分析插件 依赖CDH集群作为管理插件;但是不是必选的;也可以单独安装
3;ClickHouse 安装
依赖Zookeeper作为元数据存储插件和Log Service以及表的 catalog service
组成架构对比;
1;Hbase架构

2;Kudu架构
3;Clickhouse架构


综上所示;Hbase和Kudu都是类似于Master-slave的架构而Clickhouse不存在Master结构;Clickhouse的每台Server的地位都是等价的;是multi-master模式。不过Hbase和Clickhouse额外增加了一个Zookeeper作为辅助的元数据存储或者是log server等;而Kudu的元数据是Master管理的;为了避免server频繁从Master读取元数据;server会从Master获取一份元数据到本地;但是会有元数据丢失的风险。
几个维度的对比;

1. 在 kudu 之前;大数据主要以两种方式存储;
第一种是静态数据;以 HDFS 引擎作为存储引擎;适用于高吞吐量的离线大数据分析场景。
这类存储的局限性是数据无法进行随机的读写和批量的更新操作。
第二种是动态数据;以 HBase作为存储引擎;适用于大数据随机读写场景。这类存储的局限性是批量读取吞吐量远不如 HDFS、不适用于批量数据分析的场景。
2. 从上面分析可知;这两种数据在存储方式上完全不同;进而导致使用场景完全不同;但在真实的场景中;边界可能没有那么清晰;面对既需要随机读写;又需要批量分析的大数据场景;该如何选择呢?
3. 这个场景中;单种存储引擎无法满足业务需求;我们需要通过多种大数据组件组合来满足这一需求;一个常见的方案是;
数据实时写入 HBase;实时的数据更新也在 HBase 完成;为了应对 OLAP 需求;我们定时;通常是 T;1 或者 T;H;将 HBase的 数据写成静态的文件;Parquet;。
导入到 OLAP 引擎;HDFS;。这一架构能满足既需要随机读写;又可以支持 OLAP 分析的场景。
但他有如下缺点;
第一;架构复杂。从架构上看;数据在 HBase、消息队列Kafka、HDFS 间流转;涉及环节太多;运维成本很高。并且每个环节需要保证高可用、维护多个副本、存储空间浪费。最后数据在多个系统上;对数据安全策略、监控等都提出了挑战。
第二;时效性低。数据从 HBase 导出成静态文件是周期性的;一般这个周期是一天;或一小时;;在时效性上不是很高。
第三;难以应对后续的更新。真实场景中;总会有数据是延迟到达的。如果这些数据之前已经从 HBase 导出到 HDFS;新到的变更数据就难以处理了;一个方案是把新变更的数据和原有数据进行对比;把不同的数据重新进行更新操作;这时候代价就很大了。
假如说;我们想要sql实时对大量数据进行分析该怎么办?或者是我想让数据存储能够支持Upsert;更新插入操作;;又该怎么办?所以这就是kudu的优势。
kudu 的定位是 Fast Analytics on Fast Data;是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
4. KUDU在 HDFS 和 HBase 这两个中平衡了随机读写和批量分析的性能;既支持了SQL实时查询;也支持了数据更新插入操作。
完美的和impala集成;统一了hdfs数据源和kudu数据源;从而使得开发人员能够高效的进行数据分析。
5. hdfs不支持批量更新操作;kudu支持
hdfs适用于离线sql分析;kudu适用于实时sql分析 hbase不支持sql操作;kudu支持;hbase-hive表可支持sql操作;但是效率极低;hbase不支持结构化数据存储;kudu支持hbase开发语言使用的java;内存的释放通过gc来完成;在内存比较紧张时可能引发full gc进而导致服务不稳定;kudu核心模块用的c;;来实现;没有full gc的风险hbase的timestamp是暴露的;kudu没有暴露hbase的插入和更新操作都是当作一条数据进行处理的;而kudu是分隔开的6. 适合于在线实时分析的应用
适合大数据量更新操作的应用适合将mysql的数据同步到kudu;减轻备库mysql查询的压力适合存储ADS数据;包含用户标签、各类指标数据等适合于存储结构化数据适合于和Impala继承;SQL分析数据适合于和HDFS一起使用;聚合数据源实时预测模型的应用;支持根据所有历史数据周期地更新模型7. kudu完美的和impala集成;统一了hdfs数据源和kudu数据源;从而使得开发人员能够高效的进行数据分析
impala-kudu 主要用于实时的分析海量数据;即海量的结构化数据不断更新到kudu中;底层是以列式结构分布式存储;查询是获取结构化数据;然后进行 OLAP 分析、数据挖掘、机器学习等分析型操作;这些分析型操作所涉及的数据延迟性很小。
但是kudu对硬件资源要求很高;特别是IO这块;之前公司遇到的集群瓶颈是多台机器;写30m/s;IO使用率达到100%从而使用rpc连接超时;导致数据丢失。
impala-kudu 的应用适用于多个行业;凡是结构化数据分析的情景都可使用;从实时性方面来讲;使用sql实时的查询结构化数据;使得分析操作快速和高效。
从离线方面来讲;可以查询hdfs的数据;从而保证了数据的统一化和多元化;并且有利于构建数据仓库模型。
应用场景;
Hbase更适合非结构化的数据存储;对大数据进行实时读写及更新的场景;Kudu;Impala也可以很好的胜任;当然再结合CDH就更好了;瓶颈并不在Kudu;而在Impala的Apache部署;比较复杂。
ClickHouse 适合低并发;灵活即席查询场景;也支持例如;报表分析;留存分析;用户标签画像分析;用户行为漏斗分析;归因分析等。
备注;
CDH是Cloudera的100;开源平台发行版;包括Apache Hadoop;专为满足企业需求而构建。CDH提供开箱即用的企业使用所需的一切。通过将Hadoop与十几个其他关键的开源项目集成;Cloudera创建了一个功能先进的系统;可帮助您执行端到端的大数据工作流程。
CDH 是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具;软件;;使得集群的安装可以从几天的时间缩短为几个小时;运维人数也会从数十人降低到几个人;极大的提高了集群管理的效率。
Hadoop生态系统发展到现在;存储层主要由HDFS和HBase两个系统把持着;一直没有太大突破。在追求高吞吐的批处理场景下;我们选用HDFS;在追求低延迟;有随机读写需求的场景下;我们选用HBase;那么是否存在一种系统;能结合两个系统优点;同时支持高吞吐率和低延迟呢?
有人尝试修改HBase内核构造这样的系统;即保留HBase的数据模型;而将其底层存储部分改为纯列式存储;目前HBase只能算是列簇式存储引擎;;但这种修改难度较大。Kudu的出现;有望解决目前Hadoop生态系统难以解决的一大类问题;比如;流式实时计算结果的更新。
Kudu是Cloudera开源的新型列式存储系统;是Apache Hadoop生态圈的成员之一;专门为了对快速变化的数据进行快速的分析;填补了以往Hadoop存储层的空缺。
Kudu提供了更接近于RDBMS的功能和数据模型;提供类似于关系型数据库的存储结构来存储数据;允许用户以和关系型数据库相同的方式插入、更新、删除数据。
Kudu仅仅是一个存储层;它并不存储数据;而是依赖外部的Hadoop处理引擎;MapReduce;Spark;Impala;。Kudu把数据按照自己的列存储格式存储在底层Linux文件系统中。
Kudu中的核心是基于表的存储引擎。Kudu存储自己的元数据;有关表的;信息和用户的数据;保存在Tablet中。
Kudu有Upsert来更新数据;类似于Oracle的Merge。
总之;Kudu就是一个存储引擎;类似于RDBMS;能够增删改查;让大数据分析更加便捷;它的存储不是基于Hadoop;而是自己有一套独立的系统在Linux。
官方文档;Apache Kudu - Introducing Apache Kudu
API文档; Generated Documentation (Untitled)
时间序列相关应用;具体要求有;
查询海量历史数据;查询个体数据;并要求快速返回;预测模型中;周期性更新模型;并根据历史数据快速做出决策;使用场景;
实时数据更新;时间序列相关的应用(例如APM),海量历史数据查询(数据顺序扫描),必须非常快地返回关于单个实体的细粒度查询(随机读);实时预测模型的应用(机器学习),支持根据所有历史数据周期地更新模型;具体情境;
在没有使用Kudu之前;为了满足业务需求;用户行为日志数据处理处理如下所示;

引入 Kudu 以后;大家看;数据的导入和查询都是在线实时的;

Kudu存储数据以后;可以快速查询分析;即席查询;与Impala集成;和报表分析;SparkSQL;。
Kudu诞生之初;设计目标;就是为取代HDFS文件系统和HBase数据库;既能够实现随机读写;又能够批量加载分析;所以Kudu属于HBase和HDFS折中产品。
Streaming Input with Near Real Time Availability;具有近实时可用性的流输入;
数据分析中的一个共同挑战就是新数据快速而不断地到达;同样的数据需要靠近实时的读取;扫描和更新。Kudu 通过高效的列式扫描提供了快速插入和更新的强大组合;从而在单个存储层上实现了实时分析用例。
Time-series application with widely varying access patterns;具有广泛变化的访问模式的时间序列应用;
time-series;时间序列;模式是根据其发生时间组织和键入数据点的模式。这可以用于随着时间的推移调查指标的性能;或者根据过去的数据尝试预测未来的行为。例如;时间序列的客户数据可以用于存储购买点击流历史并预测未来的购买;或由客户支持代表使用。虽然这些不同类型的分析正在发生;插入和更换也可能单独和批量地发生;并且立即可用于读取工作负载。Kudu 可以用 scalable ;可扩展;和 efficient ;高效的;方式同时处理所有这些访问模式。由于一些原因;Kudu 非常适合时间序列的工作负载。随着 Kudu 对基于 hash 的分区的支持;结合其对复合 row keys;行键;的本地支持;将许多服务器上的表设置成很简单;而不会在使用范围分区时通常观察到“hoTSPotting;热点;”的风险。Kudu 的列式存储引擎在这种情况下也是有益的;因为许多时间序列工作负载只读取了几列;而不是整行。 过去;您可能需要使用多个数据存储来处理不同的数据访问模式。这种做法增加了应用程序和操作的复杂性;并重复了数据;使所需存储量增加了一倍;或更糟;。Kudu 可以本地和高效地处理所有这些访问模式;而无需将工作卸载到其他数据存储。
Predictive Modeling;预测建模;
数据科学家经常从大量数据中开发预测学习模型。模型和数据可能需要在学习发生时或随着建模情况的变化而经常更新或修改。此外;科学家可能想改变模型中的一个或多个因素;看看随着时间的推移会发生什么。在 HDFS 中更新存储在文件中的大量数据是资源密集型的;因为每个文件需要被完全重写。在 Kudu;更新发生在近乎实时。科学家可以调整值;重新运行查询;并以秒或分钟而不是几小时或几天刷新图形。此外;批处理或增量算法可以随时在数据上运行;具有接近实时的结果。
Combining Data In Kudu With Legacy Systems;结合 Kudu 与遗留系统的数据;
公司从多个来源生成数据并将其存储在各种系统和格式中。例如;您的一些数据可能存储在 Kudu;一些在传统的 RDBMS 中;一些在 HDFS 中的文件中。您可以使用 Impala 访问和查询所有这些源和格式;而无需更改旧版系统。
Kudu是典型的主从架构。一个Kudu集群由主节点即Master和若干个从节点即Tablet Server组成。Master负责管理集群的元数据;类似于HBase Master;;Tablet Server负责数据存储;类似HBase的RegionServer;。在生产环境;一般部署多个Master实现高可用;奇数个、典型的是3个;;Tablet Server一般也是奇数个。
下图显示了一个具有三个 master 和多个 tablet server 的 Kudu 集群;每个服务器都支持多个 tablet。它说明了如何使用 Raft 共识来允许 master 和 tablet server 的 leader 和 follow。此外;tablet server 可以成为某些 tablet 的 leader;也可以是其他 tablet 的 follower。leader 以金色显示;而 follower 则显示为蓝色。

与HDFS和HBase相似;Kudu使用单个的Master节点;用来管理集群的元数据;并且使用任意数量的Tablet Server;可对比理解HBase中的RegionServer角色;节点用来存储实际数据。
可以部署多个Master节点来提高容错性。一个Table表的数据;被分割成1个或多个Tablet;Tablet被部署在Tablet Server来提供数据读写服务。

架构组成;
1;Data Compression;数据压缩;
由于给定的列只包含一种类型的数据;基于模式的压缩比压缩混合数据类型;在基于行的解决案中使用;时更有效几个数量级。结合从列读取数据的效率;压缩允许您在从磁盘读取更少的块时完成查询
2;Table;表;
一张table是数据存储在 Kudu 的位置。表具有schema和全局有序的primary key;主键;。table被分成很多段;也就是称为tablets。
3;Tablet;段;
一个tablet是一张table连续的segment;与其它数据存储引擎或关系型数据库的partition;分区;相似。给定的tablet冗余到多个tablet服务器上;并且在任何给定的时间点;其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务;并且写入时需要在为tablet服务的一组tablet server之间达成一致性。
一张表分成多个tablet;分布在不同的tablet server中;最大并行化操作Tablet在Kudu中被切分为更小的单元;叫做RowSets;RowSets分为两种MemRowSets和DiskRowSet;MemRowSets每生成32M;就溢写到磁盘中;也就是DiskRowSet
4;Tablet Server
一个tablet server存储tablet和为tablet向client提供服务。对于给定的tablet;一个tablet server充当 leader;其他tablet server充当该 tablet 的follower副本。只有leader服务写请求;然而leader或followers为每个服务提供读请求。leader使用Raft Consensus Algorithm来进行选举 。一个tablet server可以服务多个tablets;并且一个 tablet 可以被多个tablet servers服务着。
Tablet server 的任务非常繁重, 其负责和数据相关的所有操作, 包括存储, 访问, 压缩, 其还负责将数据复制到其它机器。 因为 Tablet server;特殊的结构, 其任务过于繁重;所以有如下限制;
Kudu 最多支持 300个服务器;建议 Tablet server最多不超过 100 个建议每个 Tablet server 至多包含 2000个 tablet;包含 Follower;建议每个表在每个 Tablet server中至多包含 60个 tablet;包含 Follower;每个 Tablet server至多管理 8TB数据理想环境下;一个 tablet leader应该对应一个 CPU核心;以保证最优的扫描性能5;Master
该master保持跟踪所有的tablets;tablet servers;Catalog Table 和其它与集群相关的metadata。在给定的时间点;只能有一个起作用的master;也就是 leader;。如果当前的 leader 消失;则选举出一个新的master;使用 Raft Consensus Algorithm来进行选举。
master还协调客户端的metadata operations;元数据操作;。例如;当创建新表时;客户端内部将请求发送给master。master将新表的元数据写入catalog table;并协调在tablet server上创建 tablet 的过程。
所有master的数据都存储在一个 tablet 中;可以复制到所有其他候选的 master。tablet server以设定的间隔向master发出心跳;默认值为每秒一次;。master是以文件的形式存储在磁盘中;所以说;第一次初始化集群。需要设定好。
6;Raft Consensus Algorithm
Kudu 使用 Raft consensus algorithm 作为确保常规 tablet 和 master 数据的容错性和一致性的手段。通过 Raft;tablet 的多个副本选举出 leader;它负责接受以及复制到 follower 副本的写入。一旦写入的数据在大多数副本中持久化后;就会向客户确认。给定的一组 N 副本;通常为 3 或 5 个;能够接受最多(N - 1)/2 错误的副本的写入。
7;Catalog Table;目录表;
catalog table是Kudu 的 metadata;元数据中;的中心位置。它存储有关tables和tablets的信息。该catalog table;目录表;可能不会被直接读取或写入。相反;它只能通过客户端 API中公开的元数据操作访问。catalog table 存储两类元数据。
8;Tables
table schemas, locations, and states;表结构;位置和状态;。
9;Tablets
现有tablet 的列表;每个 tablet 的副本所在哪些tablet server;tablet的当前状态以及开始和结束的keys;键;。

4、kudu 特性
Kudu是Cloudera开源的列式存储引擎;具有以下几个特点;
C;;语言开发;Kudu 的 API 可以使用 Java 和 C;;;Columnar Data Store;列式数据存储;高效处理类OLAP负载Read Efficiency;高效读取;与MapReduce;Spark以及Hadoop生态系统中其他组件进行友好集成;可与Cloudera Impala集成;替代目前Impala常用的HDFS;Parquet组合;灵活的一致性模型;顺序写和随机写并存的场景下;仍能达到良好的性能;高可用;使用Raft协议保证数据高可靠存储;结构化数据模型;对于分析查询;允许读取单个列或该列的一部分同时忽略其他列
1;重要性
大数据分析的复杂性往往是存储系统的局限性带来的;Kudu 的局限性小很多;一定程度使大数据分析变得简单。新的应用场景需要 Kudu;例如越来越多的应用集中在机器生成的数据和实时分析领域。适配新的硬件环境;从而带来更高的性能和应用灵活性。2;易用性
提供了更接近于 RDBMS 的功能和数据模型;提供类似 RDBMS 的库表存储结构;允许用户以和 RDBMS 相同的方式插入、更新和删除数据;3;优势
Kudu 同时具备了逐行插入、低延迟随机访问、更新和快速分析扫描的能力;使得它在 OLAP 和 OLTP 中都能提供较好的支持;这些原本需要多个存储系统同时支持的复杂架构被替换成只有一个存储系统;所有的数据被存放在这个存储系统里;极大地简化了大数据的架构。
4;与传统关系型数据库比较
跟关系型数据库一样;Kudu 表有一个唯一的主键。关系型数据库中常见的特性;比如事务、外键和非主键索引;目前在Kudu中是不支持的。Kudu拥有一些OLAP和OLTP特性;但是缺少对跨行的原子性、一致性、隔离性、持久性事务的支持。Kudu可被归为混合食物/分析处理;Hybrid Transaction/Analytic Processing;HTAP;类型数据库。Kudu支持快速主键检索;并能在数据持续输入的同时进行分析;而 OLAP 数据库在这种场景下性能通常不是很好。Kudu的持久性保证和 OLTP 数据库更为接近。Kudu的Quorum 能力可以实现一种名为Fractured Mirrors的机制;即一个或两个节点使用行存储;另外的节点使用列存储。这样就可以在行存储的节点上执行OLTP类型的查询;在列存储的节点上执行OLAP查询;混合两种负载。5;与其他大数据组件比较
HDFS擅长大规模扫描;但不擅长随机读;严格来说;并不支持随机写;可以通过合并的方式模拟随机写;但成本很高。HBase和Cassandra擅长随机访问;随机读取和修改数据;但大规模扫描性能较差。Kudu的目标是把扫描性能做到HDFS的两倍;而随机读性能接 HBase和Cassandra;实际目标是在SSD上随机读/写的延迟在1ms以内。kudu设计是面向结构化存储,因此kudu需要用户在建表时定义它的schema信息;这些schema信息包含:列定义(含类型);Primary Key定义;用户指定的若干个列的有序组合;数据的唯一性;依赖于用户所提供的Primary Key中的Column组合的值的唯一性。Kudu提供了Alter命令来增删列;但位于Primary Key中的列是不允许删除的。
从用户角度来看;kudu是一种存储结构化数据表的存储系统;一个kudu集群中可以定义任意数量table;每个table都需要定义好schema;每个table的列数是确定的;每一列都需要名字和类型;表中可以把一列或者多列定义为主键,kudu更像关系型数据库;但是不支持二级索引。
KUDU分区数必须预先预定。在内存中对每个Tablet分区维护一个MemRowSet来管理最新更新的数据;默认是1G刷新一次或者是2分钟。后Flush到磁盘上形成DiskRowSet;多个DiskRowSet在适当的时候进行归并处理。和HBase采用的LSM;LogStructured Merge;很难对数据进行特殊编码;所以处理效率不高;方案不同的是;Kudu对同一行的数据更新记录的合并工作;不是在查询的时候发生的;HBase会将多条更新记录先后Flush到不同的Storefile中;所以读取时需要扫描多个文件;比较rowkey;比较版本等;然后进行更新操作;;而是在更新的时候进行;在Kudu中一行数据只会存在于一个DiskRowSet中;避免读操作时的比较合并工作。那Kudu是怎么做到的呢?对于列式存储的数据文件;要原地变更一行数据是很困难的;所以在Kudu中;对于Flush到磁盘上的DiskRowSet;DRS;数据;实际上是分两种形式存在的;一种是Base的数据;按列式存储格式存在;一旦生成;就不再修改;另一种是Delta文件;存储Base数据中有变更的数据;一个Base文件可以对应多个Delta文件;这种方式意味着;插入数据时相比HBase;需要额外走一次检索流程来判定对应主键的数据是否已经存在。因此;Kudu是牺牲了写性能来换取读取性能的提升。更新、删除操作需要记录到特殊的数据结构里;保存在内存中的DeltaMemStore或磁盘上的DeltaFIle里面。DeltaMemStore是B-Tree实现的;因此速度快;而且可修改。磁盘上的DeltaFIle是二进制的列式的块;和base数据一样都是不可修改的。因此当数据频繁删改的时候;磁盘上会有大量的DeltaFiles文件;Kudu借鉴了Hbase的方式;会定期对这些文件进行合并。

既然存在Delta数据;也就意味着数据查询时需要同时检索Base文件和Delta文件;这看起来和HBase的方案似乎又走到一起去了;不同的地方在于;Kudu的Delta文件与Base文件不同;不是按Key排序的;而是按被更新的行在Base文件中的位移来检索的;号称这样做;在定位Delta内容的时候;不需要进行字符串比较工作;因此能大大加快定位速度;但是无论如何;Delta文件的存在对检索速度的影响巨大。因此Delta文件的数量会需要控制;需要及时的和Base数据进行合并。由于Base文件是列式存储的;所以Delta文件合并时;可以有选择性的进行;比如只把变化频繁的列进行合并;变化很少的列保留在Delta文件中暂不合并;这样做也能减少不必要的IO开销。
除了Delta文件合并;DRS自身也会需要合并;为了保障检索延迟的可预测性;这一点是HBase的痛点之一;比如分区发生Major Compaction时;读写性能会受到很大影响;;Kudu的compaction策略和HBase相比;有很大不同;kudu的DRS数据文件的compaction;本质上不是为了减少文件数量;实际上Kudu DRS默认是以32MB为单位进行拆分的;DRS的compaction并不减少文件数量;而是对内容进行排序重组;减少不同DRS之间key的overlap;重复;;进而在检索的时候减少需要参与检索的DRS的数量。

KUDU 的数据模型与传统的关系型数据库类似;一个 KUDU 集群由多个表组成;每个表由多个字段组成;一个表必须指定一个由若干个;>=1;字段组成的主键。
Kudu的底层数据文件的存储;未采用HDFS这样的较高抽象层次的分布式文件系统;而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统主要是;
快速的列式查询;快速的随机更新;更为稳定的查询性能保障;
一张table会分成若干个tablet;其中Tablet的数量是根据hash或者是range进行设置的。每个tablet包括MetaData元信息及若干个RowSet;其中MetaData信息是block和block在data中的位置。
RowSet包含一个MemRowSet及若干个DiskRowSet;其中MemRowSet用于存储insert数据和update后的数据;写满后会刷新到磁盘中也就是多个DiskRowSet中;默认是1G刷新一次或者是2分钟。
1个DiskRowSet用于老数据的mutation;更新;;比如说数据的更新操作;后台定期对DiskRowSet进行合并操作;删除历史数据和没有的数据;减少查询过程中的IO开销。DiskRowSet中包含一个BloomFile、AdhocIndex、BaseData、DeltaMem及若干个RedoFile和UndoFile( UndoFile一般情况下只有一个 )
RowSet组成;
MemRowSet;用于新数据insert及已在MemRowSet中的数据的更新;一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。默认是1G或者或者120S
DiskRowSet;用于老数据的变更;后台定期对DiskRowSet做compaction;以删除没用的数据及合并历史数据;减少查询过程中的IO开销。
BloomFile;根据一个DiskRowSet中的key生成一个bloom filter;用于快速模糊定位某个key是否在DiskRowSet中。
AdhocIndex;是主键的索引;用于定位key在DiskRowSet中的具体哪个偏移位置。
BaseData;是MemRowSet flush下来的数据;按列存储;按主键有序。
UndoFile;是基于BaseData之前时间的历史数据;通过在BaseData上apply UndoFile中的记录;可以获得历史数据。
RedoFile;是基于BaseData之后时间的变更记录;通过在BaseData上apply RedoFile中的记录;可获得较新的数据。
DeltaMem;用于DiskRowSet中数据的变更;先写到内存中;写满后flush到磁盘形成
RedoFile。
MemRowSets与DiskRowSets的区别;
Kudu;

HBase;

对比可知;MemRowSets中数据Flush磁盘后;形成DiskRowSets;DiskRowSets中数据32M大小为单位;按序划分一个个DiskRowSet;DiskRowSet中的数据按照Column进行组织,类比Parquet;这是Kudu可支持一些分析性查询的基础;每一个Column存储在一个相邻的数据区域;而这个数据区域进一步细分为一个个小Page单元;与hbase的File中Block类似;对于每个Column Page可以采用一些Encoding算法;以及通用的Compression算法。
对于数据的更新和删除;Kudu与hbase蕾西,通过增加一条新记录来描述数据更新和删除;虽然对于DiskRowSet不可修改;Kudu将DiskRowSet划分两个部分;BaseData;DeltaStores;BaseData负责存储基础数据;DeltaStore负责存储BaseData中变更数据。

数据从 MemRowSet 刷到磁盘后就形成了一份 DiskRowSet;只包含 base data;;每份DiskRowSet 在内存中都会有一个对应的 DeltaMemStore,负责记录此 DiskRowSet 后续的数据变更映射到每个 row_offset 对应的数据变更。
DeltaMemStore 数据增长到一定程度后转化成二进制文件存储到磁盘;形成一个 DeltaFile;随着base data 对应数据的不断变更;DeltaFile 逐渐增长。下图是DeltaFile生成过程的示意图;更新、删除;。DeltaMemStore 内部维护一个 B-树索引。

Delta数据部分包含REDO与UNDO两部分;这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似;在关系型数据库中;REDO日志记录了更新后的数据;可以用来恢复尚未写入DataFile的已成功事务更新的数据。而UNDO日志用来记录事务更新之前的数据;可以用来在事务失败时进行回滚;;但也存在一些细节上的差异;
REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。Tablet 副本机制;1个副本为leader;其他副本为Follower;类似Kafka Topic中分区Partition。副本之间;基于Raft协议;实现高可用HA;当leader挂掉以后;从Follower中选取leader。副本数必须为奇数;例如为3个副本等。

MemRowSet
实现方式;B;Tree
DiskRowSet
1.实现方式;二叉平衡树
2.内部数据组织;DeltaMem 和 MemRowSet在存在中的组织方式是一致的;都是B;Tree;在磁盘上的存储都是放在CFile文件中的;右图为CFile的文件格式
3.Cfile;包含Header;Data;Index;Footer四块;Index有两种;posidx index是根据rowId找到Data中的偏移;validx index是根据key的值找到data中的偏移;
validx只针对只有一个column为key的情况下;这个时候DiskRowSet是没有Ad_hoc索引的;使用validx来代替。
这两个index内部实现了B-Tree;index不一定是联系的;在达到一定长度后就会刷盘;Footer是记录CFile的元数据;
包括posidx_index;validx_index两棵树根节点所在位置;数据条目、编码、压缩方式等
4.压缩;对于ad_hoc文件使用的prefix;delta fle使用的是plain;bloomfile使用的是plain
5.磁盘上每一个DiskRowSet有若*.metadata和*.data文件;metadata文件记录的是DiskRowSet的元信息;主要包括哪些block和block在data中的位置;
左图为block和DiskRowSet中各部分的映射关系;在写磁盘时是通过container来写入;每个container可以写很大的一块连续的磁盘空间;
用于给某一个CFile写数据;当一个CFile写完后会将container归还给BlockManager;这时container就可以用于下一个CFile写数据了;
当BlockManager中没有container可用是会创建一个新的container给新的CFile使用。
6.对应新建block先看看是否有container可用;若没有;目前默认的是在所在的配置中的data_dir中随机选取一个dir建一个新的metadata和data文件。
先写data;block落盘后再写metadata

MVCC
表的主键排序,受益于MVCC;Multi-Version Concurrency Control 多版本并发控制;一旦数据写入到MemRowSet;后续的reader能立马查询到
Compaction minor compaction;多个deltafile进行合并。默认是1000个deltafile进行合并一次
major compaction;deltafile文件的大小和basedata的文件的比例为0.1的时候;会进行合并操作在Kudu存储引擎中;如何将一个表Table数据划分为多个Tablet???有哪些分区策略;
在Kudu中;每个表的分区Tablet需要在创建表的时候指定;表创建以后不能被修改。

1;范围分区;Range Partitioning;类似HBase表划分
按照字段值范围进行分区;HBase 就采用了这种方式。

2;Hash Partitioning;按照字段的Hash 值进行分区;Cassandra 采用了这个方式。

3;多级分区;可以指定范围;再指定哈希或者指定多个哈希分析
KUDU 支持用户对一个表指定一个范围分区规则和多个 Hash 分区规则;如下图;

多级散列分区组合;如下图所示;

KUDU 是一个列式存储的存储引擎;其数据存储方式如下;

列式存储的数据库很适合于 OLAP 场景;其特点如下;
优势∶查询少量列时 IO 少;速度快;数据压缩比高;便于查询引擎性能优化∶延迟物化、直接操作压缩数据、向量化执行。
劣势∶查询列太多时性能下降;KUDU 建议列数不超过 300;;不适合 OLTP 场景。
1.kudu中的Tablet是负责Table表的一部分的读写工作;Tablet是有多个或一个Rowset组成的;其中一个Rowset处于内存中;叫做MemRowSet;MemRowSet主要是负责处理新的数据写入请求。
2.DiskRowSet是MemRowSet达到1G刷新一次或者是时间超过2分钟后刷新到磁盘后生成的;实际底层存储是是有Base Data;一个CFile文件;、
多个Delta file;Undo data、Redo data组成;的和Delta MemStore;其中位于磁盘中的Base data、Undo data、Redo data是不可修改的;
Delta Memstore达到一定程度后会刷新到磁盘中的生成Redo data;其中kudu后台有一个类似HBase的compaction线程策略进行合并处理;
1、Minor Compaction;多个DeltaFile进行合并生成一个大的DeltaFile。默认是1000个DeltaFile进行合并一次
2、Major Compaction;DeltaFile文件的大小和Base data的文件的比例为0.1的时候;会进行合并操作;生成Undo data
3、将多个DiskRowSet进行合并;减少DiskRowSet的数量
Base Data;是MemRowSet flush下来的数据;按照列存储;按照主键有序
Undo Data;是BaseData之前的数据历史数据
Redo Data;是BaseData之后的mutation记录;可以获得较新的数据
Delta Memstore;用于在内存中存储更新为磁盘中数据的mutation记录;先写到内存中;然后写满后flush到磁盘;形成DeltaFile
3.当创建Kudu客户端时;其会从主master上获取tablet位置信息;然后直接与服务于该tablet的服务器进行交谈。
为了优化读取和写入路径;客户端将保留该信息的本地缓存;以防止他们在每个请求时需要查询主机的tablet位置信息。
随着时间的推移;客户端的缓存可能会变得过时;并且当写入被发送到不是领导者的tablet服务器时;则将被拒绝。
然后;客户端将通过查询主服务器发现新领导者的位置来更新其缓存。
4.读流程
1.客户端连接TMaster获取表的相关信息;包括分区信息;表中所有tablet的信息
2.客户端找到需要读取的数据的tablet所在的TServer;Kudu接受读请求;并记录timestamp信息;如果没有显式指定;那么表示使用当前时间
3.从内存中读取数据;也就是MemRowSet和DeltaRowSet中读取数据;根据timestamp来找到对应的mutation链表
4.从磁盘中读取数据;从metadata文件中使用boom filter快速模糊的判断所有候选RowSet是否含有此key。
然后从DiskRowSet中读取数据;实际是根据B;树;判断key在那些DiskRowSet的range范围内;然后从metadata文件中;获取index来判断rowId在Data中的偏移;
或者是利用validex来判断数据的偏移;只有一个key;;根据读操作中包含的timestamp信息判断是否需要将base data进行回滚操作从而获取数据
5.写流程
1.Kudu插入一条新数据
1.客户端连接TMaster获取表的相关信息;包括分区信息;表中所有tablet的信息
2.客户端找到负责处理读写请求的tablet所负责维护的TServer。Kudu接受客户端的请求;检查请求是否符合要求;表结构;
3.Kudu在Tablet中的所有rowset;memrowset,diskrowset;中进行查找;看是否存在与待插入数据相同主键的数据;如果存在就返回错误;否则继续
4.写入操作先被提交到tablet的预写日志(WAL);并根据Raft一致性算法取得追随节点的同意;然后才会被添加到其中一个tablet的内存中;
插入会被添加到tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC);对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作
将被追加到MemRowSet中的原始行之后以生成REDO记录的列表
5.Kudu在MemRowset中写入一行新数据;在MemRowset;1G或者是120s;数据达到一定大小时;MemRowset将数据落盘;并生成一个diskrowset用于持久化数据;
还生成一个memrowset继续接收新数据的请求
2.Kudu对原有数据的更新
1.客户端连接TMaster获取表的相关信息;包括分区信息;表中所有tablet的信息
2.Kudu接受请求;检查请求是否符合要求
3.因为待更新数数据可能位于memrowset中;也可能已经flush到磁盘上;形成diskrowset。因 此根据待更新数据所处位置不同;kudu有不同的做法
4.当待更新数据位于memrowset时;找到待更新数据所在行;然后将更新操作记录在所在行中一个mutation链表中;
在memrowset将数据落盘时;Kudu会将更新合并到base data;并生成UNDO records用于查看历史版本的数据;REDO records实际上也是以DeltaFile的形式存放
6.应用场景
1.当待更新数据位于DiskRowset时;找到待更新数据所在的DiskRowset;每个DiskRowset都会在内存中设置一个DeltaMemStore;将更新操作记录在DeltaMemStore中;
在DeltaMemStore达到一定大小时;flush在磁盘;形成DeltaFile中。
2.实际上Kudu提交更新时会使用Raft协议将更新同步到其他replica(复制品)上去;当然如果在memrowset和DiskRowset中都没有找到这条数据;那么返回错误给客户端;
另外当DiskRowset中的deltafile太多时;Kudu会采用一定的策略对一组deltafile进行合并。
3.wal日志的作用是如果我们在做真正的操作之前;先将这件事记录下来;持久化到可靠存储中;因为日志一般很小;并且是顺序写;效率很高;;
然后再去执行真正的操作。这样执行真正操作的时候也就不需要等待执行结果flush到磁盘再执行下一步;因为无论在哪一步出错;我们都能够根据备忘录重做一遍;
得到正确的结果。
读;

先根据要扫描数据的主键范围;定位到目标的Tablets;然后读取Tablets 中的RowSets;在读取每个RowSet时;先根据主键过滤要scan范围;然后加载范围内的BaseData;再找到对应的DeltaMemStores;应用所有变更;最后union上MemRowSet中的内容;返回数据给Client。
写;

当CLient请求写数据时;先根据主键从Master获取要访问的目标Tablets;然后依次到对应的Tablet获取数据。
因为kudu表存在主键约束;所以需要进行主键是否已经存在的判断,这里涉及到之前说的索引结构对读写的优化,一个Tablet中存在多个RowSets,为了提升性能,尽可能减少扫描RowSets数量;首先;我们先通过每个 RowSet 中记录的主键的;最大最小;范围;过滤掉一批不存在目标主键的RowSets;然后在根据RowSet中的布隆过滤器;过滤掉确定不存在目标主键的 RowSets;最后再通过RowSets中的 B-树索引;精确定位目标主键是否存在。
如果主键已经存在;则报错;主键重复;;否则就进行写数据;写MemRowSet;。
更新;

数据更新的核心是定位到待更新数据的位置;这块与写入的时候类似;就不展开了;等定位到具体位置后;然后将变更写到对应的DeltaMemStore 中。
硬件;
一台或者多台机器跑kudu-master。建议跑一个master(无容错机制)、三个master(允许一个节点运行出错)或者五个master(允许两个节点出错)。一台或者多台机器跑kudu-tserver。当需要使用副本;至少需要三个节点运行kudu-tserver服务。操作系统(主要是linux系统;windows系统不支持);
RHEL 6, RHEL 7, CentOS 6, CentOS 7, Ubuntu 14.04 (Trusty), Ubuntu 16.04 (Xenial), Debian 8 (Jessie), or SLES 12.内核和文件系统支持 hole punching 选项。ntp服务。xfs or ext4 formatted drives存储;
尽量使用固态存储;将显著提高kudu性能。管理
如果你使用的是CDH;需要Cloudera Manager 5.4.3及以上的版本。
# cat /etc/ntp.conf
restrict default kod nomodify notrap nopeer noquery #拒绝IPV4用户
restrict -6 default kod nomodify notrap nopeer noquery #拒绝ipV6用户
restrict 127.0.0.1
restrict -6 ::1
restrict 172.31.217.0 mask 255.255.255.0 nomodify notrap #本地网段授权访问
server 172.31.217.173 #指定上级更新服务器
server 0.centos.pool.ntp.org
server 1.centos.pool.ntp.org
server 2.centos.pool.ntp.org
server 172.31.217.173 # local clock
fudge 172.31.217.173 stratum 10
# /etc/init.d/ntpd start 各个节点检查启动成功;否则启动kudu相关服务会报错安装;
# yum install kudu kudu-master kudu-client0 kudu-client-devel -y
基本配置;
# cat /etc/kudu/conf/master.gflagfile
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-master.
--fromenv=rpc_bind_addresses
--fromenv=log_dir
--fs_wal_dir=/opt/kudu/master
--fs_data_dirs=/opt/kudu/master设置权限;
# mkdir /opt/kudu && chown kudu:kudu /opt/kudu
启动;
# /etc/init.d/kudu-master start
安装;
# yum install kudu kudu-tserver kudu-client0 kudu-client-devel -y
基本配置;
# cat /etc/kudu/conf/tserver.gflagfile
# Do not modify these two lines. If you wish to change these variables,
# modify them in /etc/default/kudu-tserver.
--fromenv=rpc_bind_addresses
--fromenv=log_dir
--fs_wal_dir=/opt/kudu/tserver
--fs_data_dirs=/opt/kudu/tserver
--tserver_master_addrs=bd-dev-ops-173:7051设置权限;
# mkdir /opt/kudu && chown kudu:kudu /opt/kudu
启动;
# /etc/init.d/kudu-tserver start图形界面;
通过master端的web界面观察运行情况;http://172.31.217.173:8051。


可以看到所有组件都已安装完毕了。
Kudu提供三种方式;操作Kudu数据库;进行DDL操作和DML操作;
方式一;可通过Java client、C;; client、Python client操作Kudu表;要构建Client并编写应用程序。详见;Apache Kudu - Developing Applications With Apache Kudu方式二;可通过Impala的shell对Kudu表进行交互式的操作;因为Impala2.8及以上的版本已经集成了对Kudu的操作。直接定义Impala表数据存储在Kudu中;内部集成方式三;通过Kudu-Spark包集成Kudu与Spark;并编写Spark应用程序来操作Kudu表KuduContext;类似SparkContext;进行DDL操作和DML操作。SparkSession操作Kudu表数据;CRUD操作无论是Java Client API使用;还是Kudu集成Spark使用;添加Maven 依赖;
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark_2.11</artifactId>
<version>1.9.0-cdh6.2.1</version>
</dependency>Kudu 框架本身提供命令kudu管理Kudu集群;位于$KUDU_HOME/bin目录。

KUDU Client 在与服务端交互时;先从 Master Server 获取元数据信息;然后去 Tablet Server读写数据;如下图;

伟大网友提供KuduPlus工具;可视化工具;连接KuduMaster;创建表、删除表查询数据。
kudu-Plus一款针对Kudu可视化工具;GitHub地址;GitHub - Xchunguang/kudu-plus: kudu可视化工具
kudu-plus是可视化管理kudu的工具;由于kudu虽然是列式数据库;但是可以表达成关系数据库类似的表和字段等信息;某种情况下通过可视化管理更加轻松。kuduplus包括对表和数据的操作约束;可以帮助更好的理解kudu。
kudu-plus版本功能实现;
v0.0.1;当前;;
查看kudu集群所有表创建kudu表删除kudu表重命名kudu表更新kudu表结构;修改非主键列名、修改非主键列默认值、修改非主键列的是否允许为空、新增非主键字段、删除非主键字段查看kudu表分区信息预览kudu表数据编辑kudu表非主键列数据删除kudu表数据行新增kudu表数据行检索kudu表数据添加筛选条件v0.0.2功能;预期;;
创建kudu表可以添加hash分区和range分区编辑kudu表可以添加和删除range分区kudu表导出为MySQL或其他类型导出kudu表导入数据
kudu列类型
布尔8位有符号整数16位有符号整数32位有符号整数64位有符号整数unixtime_micros;Unix时代以来的64位微秒;单精度;32位;IEEE-754浮点数双精度;64位;IEEE-754浮点数十进制;详见十进制类型;UTF-8编码字符串;最多64KB未压缩;二进制;最多64KB未压缩;kudu分区
范围分区;
Kudu允许在运行时动态添加和删除范围分区;而不会影响其他分区的可用性。删除分区将删除属于该分区的平板电脑以及其中包含的数据。后续插入到已删除的分区中将失败。可以添加新分区;但它们不得与任何现有范围分区重叠。Kudu允许在单个事务更改表操作中删除和添加任意数量的范围分区。 动态添加和删除范围分区对于时间序列用例特别有用。随着时间的推移;可以添加范围分区以覆盖即将到来的时间范围。例如;存储事件日志的表可以在每个月开始之前添加月份分区;以便保存即将发生的事件。可以删除旧范围分区;以便根据需要有效地删除历史数据。
范围分区的键必须是主键列的一个子集在没有散列分区的范围分区表中;每个范围分区将恰好对应于一个tabletkudu允许在运行时添加或删除范围分区;而不会影响其他分区的可用性。删除分区将删除属于该分区的tablet以及其中包含的数据。后续插入到已删除的分区的数据将失败。添加的新分区不能与现有的范围分区重叠。动态添加和删除范围分区对于时间序列用例特别有用。随着时间的推移;可以添加范围分区以覆盖即将到来的时间范围。例如;存储事件日志的表可以在每个月开始之前添加月份分区;以便保存即将发生的事件。可以删除旧范围分区;以便在必要时有效地删除历史数据。哈希分区;
散列分区按散列值将行分配到许多存储桶之一。在单级散列分区表中;每个桶只对应一个tablet。在表创建期间设置桶的数量。通常;主键列用作要散列的列;但与范围分区一样;可以使用主键列的任何子集。 当不需要对表进行有序访问时;散列分区是一种有效的策略。散列分区对于在tablet之间随机传播写入非常有效;这有助于缓解热点和不均匀的tablet大小。
哈希分区不允许动态添加和删除优缺点;
散列分区可以最大限度地提高写入吞吐量;而范围分区可以避免无限制的tablet增长问题。这两种策略都可以利用分区修剪来优化不同场景下的扫描。使用多级分区;可以将这两种策略结合起来;以获得两者的好处;同时最大限度地减少每种策略的缺点。
java操作分区;
查看测试用例部分代码
kudu主键设计
每个Kudu表必须声明由一列或多列组成的主键。与RDBMS主键一样;Kudu主键强制执行唯一性约束。尝试插入具有与现有行相同的主键值的行将导致重复键错误。主键列必须是非可空的;并且可能不是boolean;float或double类型。在表创建期间设置后;主键中的列集可能不会更改。与RDBMS不同;Kudu不提供自动递增列功能;因此应用程序必须始终在插入期间提供完整的主键。行删除和更新操作还必须指定要更改的行的完整主键。Kudu本身不支持范围删除或更新。插入行后;可能无法更新列的主键值。但是;可以删除行并使用更新的值重新插入。kudu存在的已知限制
列数
默认情况下;Kudu不允许创建超过300列的表。我们建议使用较少列的架构设计以获得最佳性能。
单元格大小
在编码或压缩之前;单个单元不得大于64KB。在Kudu完成内部复合密钥编码之后;构成复合密钥的单元限制为总共16KB。插入不符合这些限制的行将导致错误返回给客户端。
行的大小
虽然单个单元可能高达64KB;而Kudu最多支持300列;但建议单行不要大于几百KB。
有效标识符
表名和列名等标识符必须是有效的UTF-8序列且不超过256个字节。
不可变主键
Kudu不允许您更新一行的主键列。
不可更改的主键
Kudu不允许您在创建表后更改主键列。
不可更改的分区
除了添加或删除范围分区之外;Kudu不允许您在创建后更改表的分区方式。
不可改变的列类型
Kudu不允许更改列的类型。
分区拆分
创建表后;无法拆分或合并分区。
主键列必须在非主键列之前
表的副本为奇数;且不能大于7;在建表时指定;且不可修改
impala操作界面里 可以执行;
invalidate metadata; 命令刷新元数据。
1;从Impala创建一个新的Kudu表
从Impala在Kudu中创建新表类似于将现有Kudu表映射到Impala表;除了您需要自己指定模式和分区信息。
Kudu建表是需要主键的;主键不能为空。
Impala首先创建表;然后创建映射;
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;在CREATE TABLE语句中;必须首先列出组成主键的列。此外;隐式标记主键列NOT NULL。
创建新的Kudu表时;您需要指定分发方案。请参阅分区表;Apache Kudu - Using Apache Kudu with Apache Impala
id为简单起见;上面的表创建示例通过散列列分布到16个分区中。有关分区的指导;请参阅 分区规则;Apache Kudu - Using Apache Kudu with Apache Impala
建普通表;
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null
)
stored as kudu建分区表;
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null,
primary key (date_timekey)
)
partition by range (date_timekey) (value=;20220417;)
stored as kudu2;在Impala中查询现有的Kudu表
Impala中创建映射Kudu表的外部映射表。通过Kudu API或其他集成;如Apache Spark;创建的表在Impala中不会自动显示。要查询它们;必须首先在Impala中创建外部表;以将Kudu表映射到Impala数据库;
CREATE EXTERNAL TABLE ;bigData; STORED AS KUDU
TBLPROPERTIES(
;kudu.table_name; = ;bigData;,
;kudu.master_addresses; = ;node1:7051,node2:7051,node3:7051;)3;Kudu分区
Kudu中的分区方法主要有两种;partition by hash 和 partition by range
kudu表基于其partition方法被拆分成多个分区;每个分区就是一个tablet;一张kudu表所属的所有tablets均匀分布并存储在tablet servers的磁盘上。
因此在创建kudu表的时候需要声明该表的partition方法;同时要指定primary key作为partition的依据。
基于hash的分区方法的基本原理是;
基于primary key的hash值将每个row;行;划分到相应的tablet当中;分区的个数即tablet的个数必须在创建表语句中指定;建表语句示例如*****;如果未指定基于某个字段的hash值进行分区;默认以主键的hash值进行分区。
create table test
(
name string,
age int,
primary key (name)
)
partition by hash (name) partitions 8
stored as kudu;基于range的分区方法的基本原理是;
基于指定主键的取值范围将每个row;行;划分到相应的tablet当中;用于range分区的主键以及各个取值范围都必须在建表语句中声明;建表语句示例如下;
例子;有班级、姓名、年龄三个字段;表中的每个row将会根据其所在的班级划分成四个分区;每个分区就代表一个班级。
create table test
(
classes int,
name string,
age int,
primary key (classes,name)
)
partition by range (classes)
(
partition value = 1,
partition value = 2,
partition value = 3,
partition value = 4
)
stored as kudu;kudu表还可以采用基于hash和基于range相结合的分区方式;使用方法与上述类似。
分区为多列
新建表;
drop table if exists test.test2;
create table test.test2 (
id String not null,
date_timekey String not null,
hour_timekey String not null,
username STRING,
password STRING,
interface_time String,
primary key (id,date_timekey,hour_timekey)
)
partition by range (date_timekey,hour_timekey) (partition value=(;20200601;,;20200601 0730;))
stored as kudu新增分区;
alter table test.test2_kudu add range partition value=(;20200601;,;20200601 0830;);
删除分区;
alter table test.test2_kudu drop range partition value=(;20200601;,;20200601 0830;)
4;删除表
drop table if exists test.test1;
5;查询数据
注意;查询数据的时候;最好是把要查询的列带上;这样可以减少查询的列;减轻查询的Loading。在写SQL的时候;使用指定的列对大数据集群压力更小;系统健壮性更加强。
select date_timekey,username from test.test1
6;添加数据
kudu表支持3种insert语句;
1.insert into test values(‘a’,12);
2.insert into test values(‘a’,12),(‘b’,13),(‘c’,14);
3.insert into test select * from other_table;注意;分区表插入数据之前;一定要先建好分区。
insert into test.test1 (date_timekey,username)values(;20200330;,;shuijianshiqing;);注意;添加的数据主键不能为空;否则数据进去不。
insert into test.test1 (date_timekey,b)values(null,;shuijianshiqing;);7;更新数据
kudu表的update操作不能更改主键的值;其他与标准sql语法相同。
upsert into test.test1 (date_timekey,username)values(;20200330;,;shuijianshiqing;);8;删除数据
注意;删除数据时候;不能使用别名删除;比如test.test t,然后条件里面是t.date_timekey;这样数据删除不了。
delete from test.test1 where date_timekey=;20200328;;
9;新增单个分区
alter table test.test1 add range partition value=;20200325;;
10;删除单个分区
alter table test.test1 drop range partition value=;20200325;;
11;新增多个分区
alter table test.test1 add range partition ;20200327;<=values<;20200331;;
12;删除多个分区
alter table test.test1 drop range partition ;20200327;<=values<;20200331;;
13;新增列
alter table test.test1 add columns(column_new string);
14;删除列
alter table test.test1 drop column column_new;
15;修改列名
username是列的原来的名称;username_new是新列的名称。
alter table test.test1 change column username username_new string;
16;upsert
如果指定的values中的主键值在表中已经存在;则执行update语义;反之;执行insert语义。
对于 upsert into test values (‘a’,12) 1;创建 HASH分区 ; RANGE分区 两者同时使用 的表、删除表
package src.main.sample;
import com.Google.common.collect.ImmutableList;
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import java.util.ArrayList;
import java.util.List;
public class CreateTable {
public static void main(String[] args) {
String tableName = ;bigData;;
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.241.128,192.168.241.129,192.168.241.130;).defaultAdminOperationTimeoutMs(60000).build();
KuduSession session = client.newSession();
// 此处所定义的是rpc连接超时
session.setTimeoutMillis(60000);
try {
// 测试;如果table存在的情况下;就删除该表
if(client.tableExists(tableName)) {
client.deleteTable(tableName);
System.out.println(;delete the table;;);
}
List<ColumnSchema> columns = new ArrayList();
// 创建列
columns.add(new ColumnSchema.ColumnSchemaBuilder(;id;, Type.INT64).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder(;user_id;, Type.INT64).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder(;start_time;, Type.INT64).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder(;name;, Type.STRING).nullable(true).build());
// 创建schema
Schema schema = new Schema(columns);
/*
创建 hash分区 ; range分区 两者同时使用 的表
addHashPartitions(ImmutableList.of(;字段名1;,;字段名2;,...), hash分区数量) 默认使用主键;也可另外指定联合主键
setRangePartitionColumns(ImmutableList.of(;字段名;))
*/
// id;user_id相当于联合主键;三个条件都满足的情况下;才可以更新数据;否则就是插入数据
ImmutableList<String> hashKeys = ImmutableList.of(;id;,;user_id;);
CreateTableOptions tableOptions = new CreateTableOptions();
/*
创建 hash分区 ; range分区 两者同时使用 的表
addHashPartitions(ImmutableList.of(;字段名1;,;字段名2;,...), hash分区数量) 默认使用主键;也可另外指定联合主键
setRangePartitionColumns(ImmutableList.of(;字段名;))
*/
// 设置hash分区;包括分区数量、副本数目
tableOptions.addHashPartitions(hashKeys,3); //hash分区数量
tableOptions.setNumReplicas(3); //副本数目
// 设置range分区
tableOptions.setRangePartitionColumns(ImmutableList.of(;start_time;));
// 设置range分区数量
// 规则;range范围为时间戳是1-10;10-20;20-30;30-40;40-50
int count = 0;
for(long i = 1 ; i <6 ; i;;) {
PartialRow lower = schema.newPartialRow();
lower.addLong(;start_time;,count);
PartialRow upper = schema.newPartialRow();
count ;= 10;
upper.addLong(;start_time;, count);
tableOptions.addRangePartition(lower, upper);
}
System.out.println(;create table is success!;);
// 创建table,并设置partition
client.createTable(tableName, schema, tableOptions);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// client.deleteTable(tableName);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
client.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}2;修改表;增加字段、删除字段
package src.main.sample;
import org.apache.kudu.Type;
import org.apache.kudu.client.AlterTableOptions;
import org.apache.kudu.client.KuduClient;
public class AlterTable {
public static void main(String[] args) {
String tableName = ;bigData;;
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.161.128,192.168.161.129,192.168.161.130;).defaultAdminOperationTimeoutMs(60000).build();
try {
Object o = 0L;
// 创建非空的列
client.alterTable(tableName, new AlterTableOptions().addColumn(;device_id;, Type.INT64, o));
// 创建列为空
client.alterTable(tableName, new AlterTableOptions().addNullableColumn(;site_id;, Type.INT64));
// 删除字段
// client.alterTable(tableName, new AlterTableOptions().dropColumn(;site_id;));
} catch (Exception e) {
e.printStackTrace();
}
}
}
3;插入表数据
package src.main.sample;
import org.apache.kudu.client.*;
public class InsertData {
public static void main(String[] args) {
try {
String tableName = ;bigData;;
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.241.128,192.168.241.129,192.168.241.130;).defaultAdminOperationTimeoutMs(60000).build();
// 获取table
KuduTable table = client.openTable(tableName);
// 获取一个会话
KuduSession session = client.newSession();
session.setTimeoutMillis(60000);
/**
* mode形式;
* SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND 后台自动一次性批处理刷新提交N条数据
* SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC 每次自动同步刷新提交每条数据
* SessionConfiguration.FlushMode.MANUAL_FLUSH 手动刷新一次性提交N条数据
*/
session.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH); //mode形式
session.setMutationBufferSpace(10000);// 缓冲大小;也就是数据的条数
// 插入时;初始时间
long startTime = System.currentTimeMillis();
int val = 0;
// 插入数据
for (int i = 0; i < 60; i;;) {
Insert insert = table.newInsert();
PartialRow row = insert.getRow();
// row.addString(;字段名;, 字段值)、row.addLong(第几列, 字段值)
row.addLong(0, i); //指第一个字段 ;id;;hash分区的联合主键之一;
row.addLong(1, i*100);//指第二个字段 ;user_id;;hash分区的联合主键之一;
row.addLong(2, i);//指第三个字段 ;start_time;;range分区字段;
row.addString(3, ;bigData;);//指第四个字段 ;name;
session.apply(insert);
if (val % 10 == 0) {
session.flush(); //手动刷新提交
val = 0;
}
val;;;
}
session.flush(); //手动刷新提交
// 插入时结束时间
long endTime = System.currentTimeMillis();
System.out.println(;the timePeriod executed is : ; ; (endTime - startTime) ; ;ms;);
session.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
4;四种刷新提交数据的模式
package src.main.sample;
import com.google.common.collect.ImmutableList;
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
/**
* 数据刷新策略对比
*/
public class InsertFlushData {
// 缓冲大小;也就是数据的条数
private final static int OPERATION_BATCH = 2000;
/**
* mode形式;
* SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND 后台自动一次性批处理刷新提交N条数据
* SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC 每次自动同步刷新提交每条数据
* SessionConfiguration.FlushMode.MANUAL_FLUSH 手动刷新一次性提交N条数据
*/
// 支持三个模式的测试用例
public static void insertTestGeneric(KuduSession session, KuduTable table, SessionConfiguration.FlushMode mode, int recordCount) throws Exception {
//设置 刷新提交模式
session.setFlushMode(mode);
//当刷新提交模式 不为 AUTO_FLUSH_SYNC;自动同步刷新;时;才设置缓冲大小;数据条数;
if (SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC != mode) {
// 缓冲大小;也就是数据的条数
session.setMutationBufferSpace(OPERATION_BATCH);
}
int commit = 0;
for (int i = 0; i < recordCount; i;;) {
Insert insert = table.newInsert();
PartialRow row = insert.getRow();
UUID uuid = UUID.randomUUID();
// row.addString(;字段名;, 字段值)、row.addLong(第几列, 字段值)
row.addString(;id;, uuid.toString());
row.addInt(;value1;, 16);
row.addLong(;value2;, 16);
Long gtmMillis;
/**
* System.currentTimeMillis() 是从1970-01-01开始算的毫秒数(GMT), kudu API是采用纳秒数, 所以需要时间*1000
* 另外, 考虑到我们是东8区时间, 所以转成Long型需要再加8个小时, 否则存到Kudu的时间是GTM, 比东8区晚8个小时
*/
// 第一步: 获取当前时间对应的GTM时区unix毫秒数
// 第二步: 将timestamp转成对应的GTM时区unix毫秒数
Timestamp localTimestamp = new Timestamp(System.currentTimeMillis());
gtmMillis = localTimestamp.getTime();
// 将GTM的毫秒数转成东8区的毫秒数量
Long shanghaiTimezoneMillis = gtmMillis ; 8 * 3600 * 1000;
row.addLong(;timestamp;, shanghaiTimezoneMillis);
session.apply(insert);
// 对于在MANUAL_FLUSH;手动刷新;模式时;进行 手动刷新提交
if (SessionConfiguration.FlushMode.MANUAL_FLUSH == mode) {
commit = commit ; 1;
// 对于手工提交, 需要buffer在未满的时候flush,这里采用了buffer一半时即提交
//如果要提交的数据条数 已经大于 缓冲大小;数据条数;除以2的值的话;则进行一次手动刷新提交
if (commit > OPERATION_BATCH / 2) {
session.flush();//手动刷新提交
commit = 0;
}
}
}
// 对于在MANUAL_FLUSH;手动刷新;模式时;进行 手动刷新提交
// 对于手工提交, 保证完成最后的提交
if (SessionConfiguration.FlushMode.MANUAL_FLUSH == mode && commit > 0) {
session.flush();//手动刷新提交
}
// 对于后台自动提交, 必须保证完成最后的提交, 并保证有错误时能抛出异常
if (SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND == mode) {
session.flush();//手动刷新提交
RowErrorsAndOverflowStatus error = session.getPendingErrors();
// 检查错误收集器是否有溢出和是否有行错误
if (error.isOverflowed() || error.getRowErrors().length > 0) {
if (error.isOverflowed()) {
throw new Exception(;kudu overflow exception occurred.;);
}
StringBuilder errorMessage = new StringBuilder();
if (error.getRowErrors().length > 0) {
for (RowError errorObj : error.getRowErrors()) {
errorMessage.append(errorObj.toString());
errorMessage.append(;;;);
}
}
throw new Exception(errorMessage.toString());
}
}
}
// 支持手动flush的测试用例
public static void insertTestManualFlush(KuduSession session, KuduTable table, int recordCount) throws Exception {
SessionConfiguration.FlushMode mode = SessionConfiguration.FlushMode.MANUAL_FLUSH;
session.setFlushMode(mode);
session.setMutationBufferSpace(OPERATION_BATCH);
int commit = 0;
for (int i = 0; i < recordCount; i;;) {
Insert insert = table.newInsert();
PartialRow row = insert.getRow();
UUID uuid = UUID.randomUUID();
row.addString(;id;, uuid.toString());
row.addInt(;value1;, 17);
row.addLong(;value2;, 17);
Long gtmMillis;
/**
* System.currentTimeMillis() 是从1970-01-01开始算的毫秒数(GMT), kudu API是采用纳秒数, 所以需要时间*1000
* 另外, 考虑到我们是东8区时间, 所以转成Long型需要再加8个小时, 否则存到Kudu的时间是GTM, 比东8区晚8个小时
*/
// 第一步: 获取当前时间对应的GTM时区unix毫秒数
// 第二步: 将timestamp转成对应的GTM时区unix毫秒数
Timestamp localTimestamp = new Timestamp(System.currentTimeMillis());
gtmMillis = localTimestamp.getTime();
// 将GTM的毫秒数转成东8区的毫秒数量
Long shanghaiTimezoneMillis = gtmMillis ; 8 * 3600 * 1000;
row.addLong(;timestamp;, shanghaiTimezoneMillis);
session.apply(insert);
// 对于手工提交, 需要buffer在未满的时候flush,这里采用了buffer一半时即提交
commit = commit ; 1;
//如果要提交的数据条数 已经大于 缓冲大小;数据条数;除以2的值的话;则进行一次手动刷新提交
if (commit > OPERATION_BATCH / 2) {
session.flush();//手动刷新提交
commit = 0;
}
}
// 对于手工提交, 保证完成最后的提交
if (commit > 0) {
session.flush();//手动刷新提交
}
}
// 自动flush的测试案例
public static void insertTestAutoFlushSync(KuduSession session, KuduTable table, int recordCount) throws Exception {
SessionConfiguration.FlushMode mode = SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC;
session.setFlushMode(mode);
for (int i = 0; i < recordCount; i;;) {
Insert insert = table.newInsert();
PartialRow row = insert.getRow();
UUID uuid = UUID.randomUUID();
row.addString(;id;, uuid.toString());
row.addInt(;value1;, 18);
row.addLong(;value2;, 18);
Long gtmMillis;
/**
* System.currentTimeMillis() 是从1970-01-01开始算的毫秒数(GMT), kudu API是采用纳秒数, 所以需要时间*1000
* 另外, 考虑到我们是东8区时间, 所以转成Long型需要再加8个小时, 否则存到Kudu的时间是GTM, 比东8区晚8个小时
*/
// 第一步: 获取当前时间对应的GTM时区unix毫秒数
gtmMillis = System.currentTimeMillis();
// 第二步: 将timestamp转成对应的GTM时区unix毫秒数
Timestamp localTimestamp = new Timestamp(System.currentTimeMillis());
gtmMillis = localTimestamp.getTime();
// 将GTM的毫秒数转成东8区的毫秒数量
Long shanghaiTimezoneMillis = gtmMillis ; 8 * 3600 * 1000;
row.addLong(;timestamp;, shanghaiTimezoneMillis);
// 对于AUTO_FLUSH_SYNC模式, apply()将立即完成数据写入;但是并不是批处理
session.apply(insert);
}
}
/**
* 测试案例
*/
public static void testStrategy() throws KuduException {
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.161.128,192.168.161.129,192.168.161.130;).build();
KuduSession session = client.newSession();
KuduTable table = client.openTable(;bigData2;);
SessionConfiguration.FlushMode mode;
long d1;
long d2;
long timeMillis;
long seconds;
int recordCount = 200000;
try {
// 自动刷新策略(默认的刷新策略;同步刷新)
mode = SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC;
System.out.println(mode ; ; is start;;);
d1 = System.currentTimeMillis();
insertTestAutoFlushSync(session, table, recordCount);
d2 = System.currentTimeMillis();
timeMillis = d2 - d1;
System.out.println(mode.name() ; ;花费毫秒数: ; ; timeMillis);
// 后台刷新策略;后台批处理刷新;
mode = SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND;
System.out.println(mode ; ; is start;;);
d1 = System.currentTimeMillis();
insertTestGeneric(session, table, mode, recordCount);
d2 = System.currentTimeMillis();
timeMillis = d2 - d1;
System.out.println(mode.name() ; ;花费毫秒数: ; ; timeMillis);
// 手动刷新
mode = SessionConfiguration.FlushMode.MANUAL_FLUSH;
System.out.println(mode ; ; is start;;);
d1 = System.currentTimeMillis();
insertTestManualFlush(session, table, recordCount);
d2 = System.currentTimeMillis();
timeMillis = d2 - d1;
System.out.println(mode.name() ; ;花费毫秒数: ; ; timeMillis);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (!session.isClosed()) {
session.close();
}
}
}
public static void createTable() {
String tableName = ;bigData2;;
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.161.128,192.168.161.129,192.168.161.130;).defaultAdminOperationTimeoutMs(60000).build();
KuduSession session = client.newSession();
session.setTimeoutMillis(60000);
try {
// 测试;如果table存在的情况下;就删除该表
if (client.tableExists(tableName)) {
client.deleteTable(tableName);
System.out.println(;delete the table is success;;);
}
List<ColumnSchema> columns = new ArrayList();
// 创建列
columns.add(new ColumnSchema.ColumnSchemaBuilder(;id;, Type.STRING).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder(;value1;, Type.INT32).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder(;value2;, Type.INT64).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder(;timestamp;, Type.INT64).key(true).build());
// 创建schema
Schema schema = new Schema(columns);
/*
创建 hash分区 ; range分区 两者同时使用 的表
addHashPartitions(ImmutableList.of(;字段名1;,;字段名2;,...), hash分区数量) 默认使用主键;也可另外指定联合主键
setRangePartitionColumns(ImmutableList.of(;字段名;))
*/
// id和timestamp 组成 联合主键
ImmutableList<String> hashKeys = ImmutableList.of(;id;, ;timestamp;);
CreateTableOptions tableOptions = new CreateTableOptions();
// 设置hash分区;包括分区数量、副本数目
tableOptions.addHashPartitions(hashKeys, 20); //hash分区数量
tableOptions.setNumReplicas(1);//副本数目
System.out.println(;create the table is success! ;);
// 创建table,并设置partition
client.createTable(tableName, schema, tableOptions);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
createTable();
testStrategy();
/**
*AUTO_FLUSH_SYNC is start;
AUTO_FLUSH_SYNC花费毫秒数: 588863
AUTO_FLUSH_BACKGROUND is start;
AUTO_FLUSH_BACKGROUND花费毫秒数: 12284
MANUAL_FLUSH is start;
MANUAL_FLUSH花费毫秒数: 17231
*/
} catch (KuduException e) {
e.printStackTrace();
}
}
}5;查询表数据
package src.main.sample;
import org.apache.kudu.Schema;
import org.apache.kudu.client.*;
import java.util.ArrayList;
import java.util.List;
public class SelectData {
public static void main(String[] args) {
try {
String tableName = ;bigData;;
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.161.128,192.168.161.129,192.168.161.130;).defaultAdminOperationTimeoutMs(60000).build();
// 获取需要查询数据的列
List<String> projectColumns = new ArrayList<String>();
projectColumns.add(;id;);
projectColumns.add(;user_id;);
projectColumns.add(;start_time;);
projectColumns.add(;name;);
KuduTable table = client.openTable(tableName);
// 简单的读取
KuduScanner scanner = client.newScannerBuilder(table).setProjectedColumnNames(projectColumns).build();
// 根据主键设置读取的上限和下限
// Schema schema = table.getSchema();
// PartialRow lower = schema.newPartialRow();
// lower.addLong(;id;, 10);
// lower.addLong(;user_id;, 10);
// lower.addLong(;start_time;, 50);
// PartialRow upper = schema.newPartialRow();
// upper.addLong(;id;, 50);
// upper.addLong(;user_id;, 50);
// upper.addLong(;start_time;, 50);
// KuduScanner scanner = client.newScannerBuilder(table)
// .setProjectedColumnNames(projectColumns)
// .lowerBound(lower)
// .exclusiveUpperBound(upper)
// .build();
while (scanner.hasMoreRows()) {
RowResultIterator results = scanner.nextRows();
// 15个tablet;每次从tablet中获取的数据的行数
int numRows = results.getNumRows();
System.out.println(;numRows count is : ; ; numRows);
while (results.hasNext()) {
RowResult result = results.next();
long id = result.getLong(0);
long user_id = result.getLong(1);
long start_time = result.getLong(2);
String name = result.getString(3);
System.out.println(;id is : ; ; id ; ; === user_id is : ; ; user_id ; ; === start_time : ; ; start_time ; ; === name is : ; ; name);
}
System.out.println(;--------------------------------------;);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
A6;修改表数据
package src.main.sample;
import org.apache.kudu.client.*;
public class UpsertData {
public static void main(String[] args) {
try {
String tableName = ;bigData;;
KuduClient client = new KuduClient.KuduClientBuilder(;192.168.161.128,192.168.161.129,192.168.161.130;).defaultAdminOperationTimeoutMs(60000).build();
// 获取table
KuduTable table = client.openTable(tableName);
/**
* mode形式;
* SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND 后台自动一次性批处理刷新提交N条数据
* SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC 每次自动同步刷新提交每条数据
* SessionConfiguration.FlushMode.MANUAL_FLUSH 手动刷新一次性提交N条数据
*/
// 获取一个会话
KuduSession session = client.newSession();
session.setTimeoutMillis(60000);
session.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH); //手动刷新一次性提交N条数据
session.setMutationBufferSpace(10000); // 缓冲大小;也就是数据的条数
// 插入时;初始时间
long startTime = System.currentTimeMillis();
int val = 0;
// 在使用 upsert 语句时;当前需要 三个条件;key;都满足的情况下;才可以更新数据;否则就是插入数据
// 三个条件;key; 分别指的是 hash分区的联合主键id、user_id;还有range分区字段 start_time
for (int i = 0; i < 60; i;;) {
//upsert into 表名 values (‘xx’,123) 如果指定的values中的主键值 在表中已经存在;则执行update语义;反之;执行insert语义。
Upsert upsert = table.newUpsert();
PartialRow row = upsert.getRow();
row.addLong(0, i); //指第一个字段 ;id;;hash分区的联合主键之一;
row.addLong(1, i*100); //指第二个字段 ;user_id;;hash分区的联合主键之一;
row.addLong(2, i); //指第三个字段 ;start_time;;range分区字段;
row.addString(3, ;bigData;;i); //指第四个字段 ;name;
session.apply(upsert);
if (val % 10 == 0) {
session.flush(); //手动刷新提交
val = 0;
}
val;;;
}
session.flush(); //手动刷新提交
// 插入时结束时间
long endTime = System.currentTimeMillis();
System.out.println(;the timePeriod executed is : ; ; (endTime - startTime) ; ;ms;);
} catch (Exception e) {
e.printStackTrace();
}
}
}
1.Kudu Tablet Server Maintenance Threads
解释;Kudu后台对数据进行维护操作;如flush、compaction、inserts、updates、and deletes;一般设置为4;官网建议的是数据目录的3倍
参数;maintenance_manager_num_threads
2.Kudu Tablet Server Block Cache Capacity Tablet
解释;分配给Kudu Tablet Server块缓存的最大内存量;建议是2-4G
参数;block_cache_capacity_mb
3.数据插入都kudu中;使用manual_flush策略
4.设置ntp服务器的时间误差不超过20s;默认是10s;
参数;max_clock_sync_error_usec=20000000
5.Kudu Tablet Server Hard Memory Limit Kudu
解释;写性能;Tablet Server能使用的最大内存量;建议是机器总内存的百分之80;master的内存量建议是2G;Tablet Server在批量写入数据时并非实时写入磁盘;
而是先Cache在内存中;在flush到磁盘。这个值设置过小时;会造成Kudu数据写入性能显著下降。对于写入性能要求比较高的集群;建议设置更大的值
参数;memory_limit_hard_bytes
6.建议每个表50columns左右;不能超过300个
7.kudu的wal只支持单目录;如果快达到极限了;就会初始化tablte失败。所以说在部署集群的时候要单独给wal设置一个单独的目录。
8.impala中创建表;底层使用kudu存储(Impala::TableName);通过kudu的client端读取数据;读取不出来。
9.kudu表如果不新建的情况下;在表中增加字段;对数据是没有影响的;kudu中增加一个字段user_id;之前impala已经和kudu进行关联操作了;
impala读取kudu的数据按照之前的所定义的字段读取的。
10.设置client长连接过期时间;默认是7天;实际生产环境中设置的是180天;
--authn_token_validity_seconds=604800
注意;设置到tserver的配置文件中
11.tserver宕掉后;5分钟后没有恢复的情况下;该机器上的tablet会移动到其他机器;因为我们通常设置的是3个副本;其中一个副本宕掉;也就是一台机器的tserver出现故障;
实际情况下;还存在一个leader和follower;读写还是能够正常进行的;所以说这个参数很重要;保证数据不会转移。
--follower_unavailable_considered_failed_sec=300
12.超过参数时间的历史数据会被清理;如果是base数据不会被清理。而真实运行时数据大小持续累加;没有被清理;默认是900s。
--tablet_history_max_age_sec=900
kudu性能报告;





报错一;tablet初始化时长很久
解决方案;
升级版本到kudu1.6.0以上版本 .参考;https://kudu.apache.org/2017/12/08/apache-kudu-1-6-0-released.html
查看io使用情况 iostat -d -x -k 1 200.;可能是IO瓶颈;
Recommended maximum number of tablet servers is 100.
Recommended maximum number of tablets per tablet server is 2000.

报错二;rpc连接超时;IO问题;
RPC can not complete before timeout: KuduRpc(method=CreateTable, tablet=null, attempt=26, DeadlineTracker(timeout=30000, elapsed=29427)
解决方案;session.setTimeoutMillis(60000)
报错三;移动tablet;权限不能访问
解决方案;--superuser_acl=*
报错四;新增master找不到元数据
解决方案;
因为master的存储全部在本地磁盘文件;如果额外的添加了一个master;会报错;找不到consensus-meta,也就是master的容错机制;需要对master的元数据数据格式化;
初始化的时候直接设计好。
Recommended maximum number of masters is 3.
报错五;minidumps文件;存储crash信息;出错
[New I/O worker #1] WARN org.apache.kudu.client.GetMasterRegistrationReceived - None of the provided masters (hadoop6:7051) is a leader, will retry.
解决方案;
rm -rf /home/var/lib/kudu/master/log_dir/minidumps
补充;
minidump文件包含有关崩溃的进程的重要调试信息;包括加载的共享库及其版本;崩溃时运行的线程列表;处理器寄存器的状态和每个线程的堆栈内存副本;
以及CPU和操作系统版本信息。Minitump可以通过电子邮件发送给Kudu开发人员或附加到JIRA;以帮助Kudu开发人员调试崩溃。
报错六;impala操作kudu超时
解决方案;kudu_operation_timeout_ms = 1800000

报错七;CDH安装kudu设置master
解决方案;
--master_addresses=hadoop4:7051,hadoop5:7051,hadoop6:7051

总结;
impala命令刷新元数据
1.impala-shell 命令进入交互界面 执行 invalidate metadata; 命令刷新元数据
2.Hue的wen页面中;在impala执行sql的窗口 执行 invalidate metadata; 命令刷新元数据
--------------------------------------------------------------------------
从Impala创建一个新的Kudu表
从Impala在Kudu中创建新表类似于将现有Kudu表映射到Impala表;除了您需要自己指定模式和分区信息。
使用以下示例作为指导。Impala首先创建表;然后创建映射。
Impala 中创建一个新的 Kudu 表
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;
在CREATE TABLE语句中;必须首先列出组成主键的列。此外;隐式标记主键列NOT NULL。
创建新的Kudu表时;您需要指定分发方案。
请参阅分区表;https://kudu.apache.org/docs/kudu_impala_integration.html#partitioning_tables
为了为简单起见;上面的表创建示例通过散列 id 列分成 16 个分区。
有关分区的指导;请参阅 分区规则;https://kudu.apache.org/docs/kudu_impala_integration.html#partitioning_rules_of_thumb
CREATE TABLE AS SELECT
您可以使用 CREATE TABLE ... AS SELECT 语句查询 Impala 中的任何其他表或表来创建表。
以下示例将现有表 old_table 中的所有行导入到 Kudu 表 new_table 中。
new_table 中的列的名称和类型 将根据 SELECT 语句的结果集中的列确定。
请注意;您必须另外指定主键和分区。
CREATE TABLE new_table
PRIMARY KEY (ts, name)
PARTITION BY HASH(name) PARTITIONS 8
STORED AS KUDU
AS SELECT ts, name, value FROM old_table;
--------------------------------------------------------------------------
在Impala中查询现有的Kudu表;Impala中创建映射Kudu表的外部映射表
通过Kudu API或其他集成;如Apache Spark;创建的表在Impala中不会自动显示。
要查询它们;必须首先在Impala中创建外部表;以将Kudu表映射到Impala数据库;
CREATE EXTERNAL TABLE ;bigData; STORED AS KUDU
TBLPROPERTIES(
;kudu.table_name; = ;bigData;,
;kudu.master_addresses; = ;node1:7051,node2:7051,node3:7051;)
查询 Impala 中现有的 Kudu 表;Impala中创建映射表(外部表)映射Kudu中的表;
通过 Kudu API 或其他集成;如 Apache Spark ;创建的表不会在 Impala 中自动显示。
要查询它们;您必须先在 Impala 中创建外部表以将 Kudu 表映射到 Impala 数据库中;
CREATE EXTERNAL TABLE my_mapping_table
STORED AS KUDU
TBLPROPERTIES (
;kudu.table_name; = ;my_kudu_table;
);
--------------------------------------------------------------------------
内部和外部 Impala 表
使用 Impala 创建新的 Kudu 表时;可以将表创建为内部表或外部表。
Internal ( 内部表 )
内部表由 Impala 管理;当您从 Impala 中删除时;数据和表确实被删除。当您使用 Impala 创建新表时;通常是内部表。
External ( 外部表 )
外部表;由 CREATE EXTERNAL TABLE 创建;不受 Impala 管理;并且删除此表不会将表从其源位置;此处为 Kudu;丢弃。
相反;它只会去除 Impala 和 Kudu 之间的映射。这是 Kudu 提供的用于将现有表映射到 Impala 的语法。
--------------------------------------------------------------------------
Kudu中的分区方法主要有两种;partition by hash 和 partition by range
kudu表基于其partition方法被拆分成多个分区;每个分区就是一个tablet;一张kudu表所属的所有tablets均匀分布并存储在tablet servers的磁盘上。
因此在创建kudu表的时候需要声明该表的partition方法;同时要指定primary key作为partition的依据。
基于hash的分区方法的基本原理是;
基于primary key的hash值将每个row;行;划分到相应的tablet当中;分区的个数即tablet的个数必须在创建表语句中指定;建表语句示例如*****;如果未指定基于某个字段的hash值进行分区;默认以主键的hash值进行分区。
create table test
(
name string,
age int,
primary key (name)
)
partition by hash (name) partitions 8
stored as kudu;
基于range的分区方法的基本原理是;
基于指定主键的取值范围将每个row;行;划分到相应的tablet当中;用于range分区的主键以及各个取值范围都必须在建表语句中声明;建表语句示例如下;
例子;有班级、姓名、年龄三个字段;表中的每个row将会根据其所在的班级划分成四个分区;每个分区就代表一个班级。
create table test
(
classes int,
name string,
age int,
primary key (classes,name)
)
partition by range (classes)
(
partition value = 1,
partition value = 2,
partition value = 3,
partition value = 4
)
stored as kudu;
kudu表还可以采用基于hash和基于range相结合的分区方式
/*
创建 hash分区 ; range分区 两者同时使用 的表
addHashPartitions(ImmutableList.of(;字段名1;,;字段名2;,...), hash分区数量) 默认使用主键;也可另外指定联合主键
setRangePartitionColumns(ImmutableList.of(;字段名;))
*/
// 设置hash分区;包括分区数量、副本数目
tableOptions.addHashPartitions(hashKeys,3); //hash分区数量
tableOptions.setNumReplicas(3); //副本数目
// 设置range分区
tableOptions.setRangePartitionColumns(ImmutableList.of(;start_time;));
--------------------------------------------------------------------------
kudu表支持3种insert语句;
1.insert into test values(‘a’,12);
2.insert into test values(‘a’,12),(‘b’,13),(‘c’,14);
3.insert into test select * from other_table;
update语句
kudu表的update操作不能更改主键的值;其他与标准sql语法相同。
upsert 语句
对于 upsert into test values (‘a’,12)
如果指定的values中的主键值 在表中已经存在;则执行update语义;反之;执行insert语义。
注意;如果同时存在 主键/联合主键、hash分区字段、range分区字段时;那么便要求三个条件都符合的情况下;才可以更新数据;否则就是插入数据。
delete语句
与标准sql语法相同。
--------------------------------------------------------------------------
Impala 中创建一个新的 Kudu 表
create table test
(
classes int,
name string,
age int,
primary key (classes,name)
)
partition by range (classes)
(
partition value = 1,
partition value = 2,
partition value = 3,
partition value = 4
)
stored as kudu;
insert into test values(1,;nagisa;,16);
select * from test;
kudu webUI页面显示
impala::default.test
Impala中创建映射Kudu表的外部映射表
CREATE EXTERNAL TABLE ;EXTERNAL_test; STORED AS KUDU
TBLPROPERTIES(
;kudu.table_name; = ;impala::default.test;,
;kudu.master_addresses; = ;node1:7051,node2:7051,node3:7051;);
insert into test values(2,;ushio;,5);
select * from EXTERNAL_test;
--------------------------------------------------------------------------
指定 Tablet Partitioning ( Tablet 分区 )
表分为每个由一个或多个 tablet servers 提供的 tablets 。理想情况下;tablets 应该相对平等地拆分表的数据。
Kudu 目前没有自动;或手动;拆分预先存在的 tablets 的机制。在实现此功能之前;您必须在创建表时指定分区。
在设计表格架构时;请考虑使用主键;您可以将表拆分成以类似速度增长的分区。
使用 Impala 创建表时;可以使用 PARTITION BY 子句指定分区;
注意;Impala 关键字;如 group;在关键字意义上不被使用时;由背面的字符包围。
CREATE TABLE cust_behavior
(
_id BIGINT PRIMARY KEY,
salary STRING,
edu_level INT,
usergender STRING,
;group; STRING,
city STRING,
postcode STRING,
last_purchase_price FLOAT,
last_purchase_date BIGINT,
category STRING,
sku STRING,
rating INT,
fulfilled_date BIGINT
)
PARTITION BY RANGE (_id)
(
PARTITION VALUES < 1439560049342,
PARTITION 1439560049342 <= VALUES < 1439566253755,
PARTITION 1439566253755 <= VALUES < 1439572458168,
PARTITION 1439572458168 <= VALUES < 1439578662581,
PARTITION 1439578662581 <= VALUES < 1439584866994,
PARTITION 1439584866994 <= VALUES < 1439591071407,
PARTITION 1439591071407 <= VALUES
)
STORED AS KUDU;
如果您有多个主键列;则可以使用元组语法指定分区边界;;;va;;1;;;;ab;;2;。该表达式必须是有效的 JSON
Impala 数据库和 Kudu
每个 Impala 表都包含在称为数据库的命名空间中。默认数据库称为默认数据库;用户可根据需要创建和删除其他数据库
当从 Impala 中创建一个受管 Kudu 表时;相应的 Kudu 表将被命名为 my_database :: table_name
不支持 Kudu 表的 Impala 关键字
创建 Kudu 表时不支持以下 Impala 关键字; - PARTITIONED - LOCATION - ROWFORMAT
--------------------------------------------------------------------------
优化评估 SQL 谓词的性能
如果您的查询的 WHERE 子句包含与 operators = ; <= ; ; ; ;; ; > = ; BETWEEN 或 IN 的比较;则 Kudu 直接评估该条件;只返回相关结果。
这提供了最佳性能;因为 Kudu 只将相关结果返回给 Impala 。
对于谓词 != ; LIKE 或 Impala 支持的任何其他谓词类型; Kudu 不会直接评估谓词;而是将所有结果返回给 Impala ;并依赖于 Impala 来评估剩余的谓词并相应地过滤结果。
这可能会导致性能差异;这取决于评估 WHERE 子句之前和之后的结果集的增量。
分区表
根据主键列上的分区模式将表格划分为 tablets 。每个 tablet 由至少一台 tablet server 提供。
理想情况下;一张表应该分成多个 tablets 中分布的 tablet servers ;以最大化并行操作。您使用的分区模式的详细信息将完全取决于您存储的数据类型和访问方式。关于 Kudu 模式设计的全面讨论;请参阅 Schema Design。
Kudu 目前没有在创建表之后拆分或合并 tablets 的机制。创建表时;必须为表提供分区模式。在设计表格时;请考虑使用主键;这样您就可以将表格分为以相同速率增长的 tablets 。
您可以使用 Impala 的 PARTITION BY 关键字对表进行分区;该关键字支持 RANGE 或 HASH 分发。分区方案可以包含零个或多个 HASH 定义;后面是可选的 RANGE 定义。 RANGE 定义可以引用一个或多个主键列。基本 和 高级分区 的示例如下所示。



