事情的经过是这样的;
我正在学习B站up主同济子豪兄的视频Pytorch迁移学习训练自己的图像分类模型【两天搞定AI毕设】
up主使用的Linux系统;我自己使用的本地的windows11系统。
在写到如下代码时;
# 定义数据加载器
from torch.utils.data import DataLoader
BATCH_SIZE = 32
# 分别定义训练集和测试集的数据加载器
# 训练集的数据加载器
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=1
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=1
)
#查看一个batch的图像和标注
# DataLoader 是 python生成器;每次调用返回一个 batch 的数据
images, labels = next(iter(train_loader))
up主那边可以正常运行;我这边报错如下;
)报错BrokenPipeError:-[Errno")
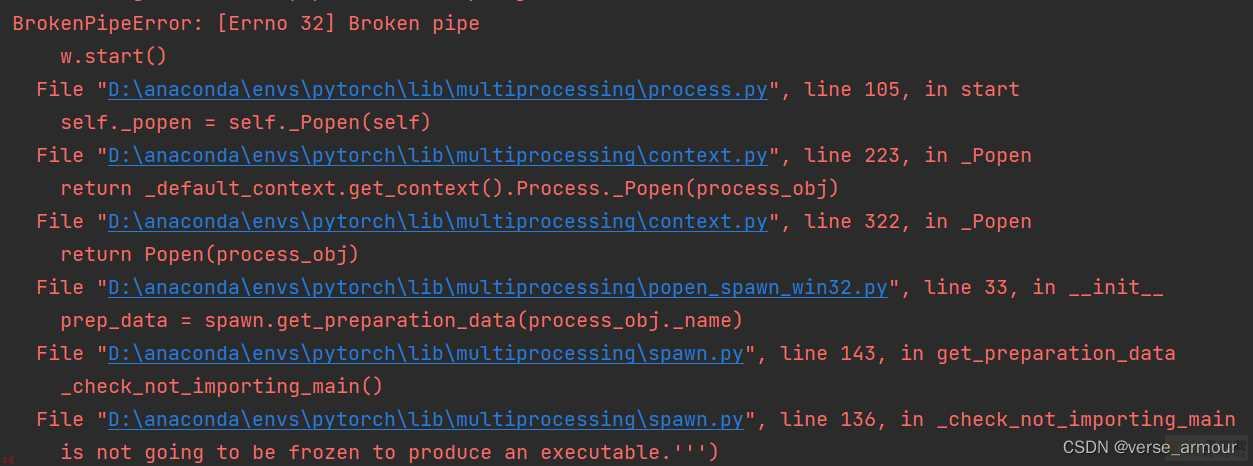

在网上冲浪一段时间之后发现是因为windows系统 pytorch不能使用多进程;num_workers只能设置为0;但是导致GPU训练时速度太慢。
在Windows上;FileMapping对象应必须在所有相关进程都关闭后;才能释放。
启用多线程处理时;子进程将创建FileMapping;然后主进程将打开它。
之后当子进程将尝试释放它的时候;因为父进程还在引用;所以它的引用计数不为零;无法释放。
但是当前代码没有提供在可能的情况下再次关闭它的机会。这个版本官方说num_workers=1是可以用的;更多的线程还在解决;不过现在即便是用2个子进程也已经可以了。
我先将num_workers设为0;报错消失。
还有一种解决方法;可以在不降低线程数量的同时解决这个问题;
在使用DataLoader读取之前加上 if name == ‘main’ : 就可以了。
;这个方法我试了没有成功?这是为什么?;
# 分别定义训练集和测试集的数据加载器
# 训练集的数据加载
if __name__ == ;__main__;:
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4#设为单线程
)
#查看一个batch的图像和标注
# DataLoader 是 python生成器;每次调用返回一个 batch 的数据
# images, labels = next(iter(train_loader))
# print(images.shape)
# print(labels)
# DataLoader 是 python生成器;每次调用返回一个 batch 的数据
# if __name__ == ;__main__;:
images, labels = next(iter(train_loader))
依然在报同样的错;大家知道的给我留个言~
以上方法参考博客;
DataLoader windows平台下 多线程读数据报错 | BrokenPipeError: [Errno 32] Broken pipe | freeze_support()_Jemary_的博客-程序员信息网


Vue3---Pinia-状态管理(环境搭建安装及各属性使用教程)详细使用教程