《python编程基础及应用》 陈波
补充知识;python的名字绑定机制会使得内存中除了保存真正的数据之外;还要保存同样数量的对象引用;会导致存储空间的浪费
import numpy as np
a = np.array([[1,2,3,4],[4,5,6,7]]) # array 可以将元组、列表或者嵌套元组、嵌套列表转为多维数组
b = np.array((1,2,3,4),dtype=np.float32) # dtype=np.float32 是将该数组的元素的数据类型设置为float32;32代表是32位 4字节
print(;a =
;,a)
print(;a.shape=;,a.shape) # a.shape = (2,4) 代表的是 2行4列;数据类型是元组类型;第一个元素是0轴 长度为2;第二个元素是1轴 长度为4
print(;a.type=;,type(a)) # type 是返回该数组的类型
print(;a.dtype=;,a.dtype) # dtype 可以返回该数组的元素的数据类型
a = [[1 2 3 4] [4 5 6 7]] a.shape= (2, 4) a.type= <class ;numpy.ndarray;> a.dtype= int32
import numpy as np
a = np.array([[1,2,3,4],[5,6,7,8]])
b = a.reshape(4,2) # 将a的形状改为4行2列;但是a和b是共享内存的;存储位置相同;可以理解为名字绑定问题;
b[0][1] = 9
print(;a=
;,a)
print(;b=
;,b) # 最后是a和b 都发生了改变
c = a.astype(np.float32) # 通过astype将数组元素的数据类型进行转换;生成了新的数组
c[0][1] = 2
print(;a=
;,a)
print(;a=
;,b)
print(;c=
;,c)
a= [[1 9 3 4] [5 6 7 8]] b= [[1 9] [3 4] [5 6] [7 8]] [[1 9 3 4] [5 6 7 8]] [[1 9] [3 4] [5 6] [7 8]] [[1. 2. 3. 4.] [5. 6. 7. 8.]]
import numpy as np
a = np.arange(0,1,0.1)
b = np.linspace(0,1,10,endpoint=0) # endpoint=0 代表的是不包含终值
c = np.linspace(0,1,10) # 默认包含终值
print(;a=;,a)
print(;不包含终值;b=;,b)
print(;包含终值;c=;,c)
a= [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9] b= [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9] c= [0. 0.11111111 0.22222222 0.33333333 0.44444444 0.55555556 0.66666667 0.77777778 0.88888889 1. ]
import numpy as np
a = np.logspace(0,2,5,endpoint=0)
b = np.logspace(0,2,5,base=2) # eg:2的0次方;2的1次方
print(;以10为底;;,a)
print(;以2为底:;,b)
以10为底; [ 1. 2.51188643 6.30957344 15.84893192 39.81071706] 以2为底: [1. 1.41421356 2. 2.82842712 4. ]
import numpy as np
print(np.zeros((2,2),np.float32)) # 生成2行2列的浮点型的数组
print(np.empty(2,np.int32))
print(np.ones((1,2)))
print(np.full(3,2)) # (3,2) 3代表是形状;2代表的是值;用2来填充
print(np.eye(2))
print(np.diag([1,2,3]))
# 这些函数的第一个参数都是形状;如果是一个;则生成一个一维数组;如果是多个整数的元组;则生成对应的多维数组
[[0. 0.] [0. 0.]] [ 0 1072693248] [[1. 1.]] [2 2 2] [[1. 0.] [0. 1.]] [[1 0 0] [0 2 0] [0 0 3]]
案列;生成一个长度为31的一维数组;每一个数组元素代表星期;eg;0代表是星期天
import numpy as np
def weekday(i):
return (i;6)%7 # 1号为星期六
print(np.fromfunction(weekday,(31,))) # float64
print(np.fromfunction(weekday,(31,)).astype(np.int)) # float64转为int
[6. 0. 1. 2. 3. 4. 5. 6. 0. 1. 2. 3. 4. 5. 6. 0. 1. 2. 3. 4. 5. 6. 0. 1. 2. 3. 4. 5. 6. 0. 1.] [6 0 1 2 3 4 5 6 0 1 2 3 4 5 6 0 1 2 3 4 5 6 0 1 2 3 4 5 6 0 1]
fromfunction(参数1;参数2): 参数1是函数名;参数2是数组的形状;数据类型为元组,默认的数组元素的类型为float64
上述例子中weekday的参数是数组元素的下标为参数;(31,)生成一维数组。
下面是测试;函数名的实参值是不是数组下标
import numpy as np
def i(i):
return i
print(np.fromfunction(i,(31,)))
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30.]
案例2:99乘法表
生成一个9行9列的二维数组
import numpy as np
def multi(i,j):
return (i;1)*(j;1)
print(np.fromfunction(multi,(9,9)).astype(np.int))
# i,j的参数分别是对应元素的行和列的下标
[[ 1 2 3 4 5 6 7 8 9] [ 2 4 6 8 10 12 14 16 18] [ 3 6 9 12 15 18 21 24 27] [ 4 8 12 16 20 24 28 32 36] [ 5 10 15 20 25 30 35 40 45] [ 6 12 18 24 30 36 42 48 54] [ 7 14 21 28 35 42 49 56 63] [ 8 16 24 32 40 48 56 64 72] [ 9 18 27 36 45 54 63 72 81]]
import numpy as np
a = np.arange(10)
print(;a=
;,a)
print(;a[2]= ;,a[2])
print(;a[1:3]=;,a[1:3])
print(;a[-1::-1]=;,a[-1::-1])
c = a[0:3] # 切片0到3的数组给c
a[:3] = 3,2,1
print(;修改后的a;,a)
print(;c=;,c)
# 注意;和列表的操作形式一样;但是列表进行切片操作的时候;解释器会复制元素创建型新的列表;而numpy进行数组切片的时候和原数组是共享内存的;原数组或新数组进行修改;二者都会修改;
a= [0 1 2 3 4 5 6 7 8 9] a[2]= 2 a[1:3]= [1 2] a[-1::-1]= [9 8 7 6 5 4 3 2 1 0] 修改后的a [3 2 1 3 4 5 6 7 8 9] c= [3 2 1]
import numpy as np
a = np.arange(10)
c = a[:5]
a[2] = 88
print(;c=;,c)
print(;a=;,a)
# 注意:需要保持独立性;可以使用copy
c= [ 0 1 88 3 4] a= [ 0 1 88 3 4 5 6 7 8 9]
通过给数组指定一个整数列表来选择指定下标的元素
import numpy as np
a = np.arange(1,13,2)
print(;a=
;,a)
x = a[[1,3,5]] # 1,3,5分别是指a的下标
print(;x=;,x)
x[0]=13
print(x[[1,2]]) # 获取x下标为1和2的元素
x[[1,2]] = 14,15
print(;x=;,x)
a1 = a[[3,1,-1,-2]]
print(;a1=;,a1)
a= [ 1 3 5 7 9 11] x= [ 3 7 11] [ 7 11] x= [13 14 15] a1= [ 7 3 11 9]
注意;a[[3,1,-1,-2]]是获取a中下标为3,1;-1;-2的元素
import numpy as np
a = np.arange(10) # 【0,1,2;3;】
print(a)
idx = np.array([[1,3,4,7],[3,3,-3,8]]) # 2行4列的数组
print(;idx={};.format(idx))
x = a[idx] # idx中的元素作为了a的下标进行索引
print(;x=
;,x)
# idx的形状大小;x也会根据idx的形状大小
[0 1 2 3 4 5 6 7 8 9] idx=[[ 1 3 4 7] [ 3 3 -3 8]] x= [[1 3 4 7] [3 3 7 8]]
import numpy as np
a = np.arange(5)
idex1 =[True,False,False,True,False]
print(;a=;,a)
print(a[idex1]) # 将True对应的下标作为索引进行取值
a= [0 1 2 3 4] [True, False, False, True, False] [0 3]
import numpy as np
a = [[ i;j for i in range(5)]for j in range(6)] # 快速生成5行6列的嵌套列表
arr = np.array(a)
print(;arr=
;,arr)
b = arr[1:5,1:3] # 两个切片结果为二维数组
print(;b=;,b)
b[1][1] = 6
print(;arr=;,arr)
print(;b=;,b)
# 请注意观察arr和b;b发生了修改;arr也发生了修改;说明切片会原数组和新数组有共享内存
arr= [[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8] [5 6 7 8 9]] b= [[2 3] [3 4] [4 5] [5 6]] arr= [[0 1 2 3 4] [1 2 3 4 5] [2 3 6 5 6] [3 4 5 6 7] [4 5 6 7 8] [5 6 7 8 9]] b= [[2 3] [3 6] [4 5] [5 6]]
# 三种方式访问同一个元素
print(arr[1][2])
print(arr[1,2])
idex = (1,2)
print(arr[idex])
3 3 3
利用item()获取元素的标准结果
import numpy as np
arr = np.arange(6).reshape(2,3).astype(np.int)
print(arr[1][1],type(arr[1,1]))
print(arr.item(1,1),type(arr.item(1,1))) # item(元素下标);确定数组的元素的数据类型
4 <class ;numpy.int32;> 4 <class ;int;>
补充知识;多维数组中用逗号分隔的下标可以视为一个“元组”
import numpy as np
a = np.arange(15).reshape(3,5)
print(;a=
;,a)
idx = slice(0,None,1),slice(1,4,2) #数据类型为元组 a[0::1,1:4:2]
print(;idx=;,idx,;数据类型;;,type(idx))
b =a[idx]
c = a[0::1,1:4:2]
print(b)
print(c)
a= [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]] idx= (slice(0, None, 1), slice(1, 4, 2)) 数据类型; <class ;tuple;> [[ 1 3] [ 6 8] [11 13]] [[ 1 3] [ 6 8] [11 13]]
补充知识;np.s_是一个特殊对象;生成切片下标对象 eg;np.s_[::3,2::2] 等于 slice(None,None,3),slice(2,None,2)等于数组名[::3,2::2]
import numpy as np
a = np.arange(10).reshape(5,2)
idx = np.s_[1::,0::]
print(;idx的数据类型为:;,type(idx)) #<class ;tuple;> 元组
b = a[idx]
b[1][1] = 666
print(a)
print(b)
# 注意;该方法会与原数组和新数组有共享内存
idx的数据类型为: <class ;tuple;> [[ 0 1] [ 2 3] [ 4 666] [ 6 7] [ 8 9]] [[ 2 3] [ 4 666] [ 6 7] [ 8 9]]
import numpy as np
a = [[x;y for x in range(5)] for y in range(7)]
a = np.array(a).astype(np.int)
print(;元组;a[(1,2,1,3),(0,0,2,1)=;,a[(1,2,1,3),(0,0,2,1)]) # 通过元组的对应位置来获取元素eg;[1,0];[2,0];[1,2],[3,1] [1 2 3 4]
print(;列表;a[4:,[0,2,4]]=;,a[4:,[0,2,4]]) # 获取4、5行中0、2、4列的元素
select = np.array([0,1,0,1,1,1,0],dtype=np.bool) # boolean index did not match indexed array along dimension 0; dimension is 7 but corresponding boolean dimension is 6
print(;布尔:a[select,1]=;,a[select,1]) # 布尔数组的长度要和数组列长度一致
元组;a[(1,2,1,3),(0,0,2,1)= [1 2 3 4] 列表;a[4:,[0,2,4]]= [[ 4 6 8] [ 5 7 9] [ 6 8 10]] 布尔:a[select,1]= [2 4 5 6]
了解数组的内存存储结构;便于理解切片和整数数组进行访问原数组与新数组内存的关系。
import numpy as np
a = np.array([[1,2,3],[4,5,6],[7,8,9]],dtype=np.float32)
print(;a=
;,a)
print(;a.dtype=;,a.dtype) # dtype是数据类型展示
print(;type(a.dtype)=;,type(a.dtype))
print(;a.ndim=;,a.ndim) # ndim代表为维度;2
print(;a.shape=;,a.shape)
print(;a.data=;,a.data) # <memory at 0x0000017F31211480> 数组的内存位置
print(;a.strides=;,a.strides)# ;12,4;
;;;
strides 作用是记录每一个轴相邻两个元素的地址差;返回的数据类型为元组;;12,4; 12代表是0轴的相邻两个元素地址差。eg;x行和x;1行;
且列相同的元素之间的地址差 。float32 是4字节;因此一个元素占了4字节;3个元素占3*4;12字节;;这是12的由来;
4 代表的是1轴相邻元素的地址差;eg; x列和x;1列;且行相同之间元素的地址差。 一个元素是4字节;应该差了4
;;;
a= [[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] a.dtype= float32 type(a.dtype)= <class ;numpy.dtype;> a.ndim= 2 a.shape= (3, 3) a.data= <memory at 0x0000017F31211480> a.strides= (12, 4) ; strides 作用是记录每一个轴相邻两个元素的地址差;返回的数据类型为元组;;12,4; 12代表是0轴的相邻两个元素地址差。eg;x行和x;1行; 且列相同的元素之间的地址差 。float32 是4字节;因此一个元素占了4字节;3个元素占3*4;12字节;;这是12的由来; 4 代表的是1轴相邻元素的地址差;eg; x列和x;1列;且行相同之间元素的地址差。 一个元素是4字节;应该差了4 ;

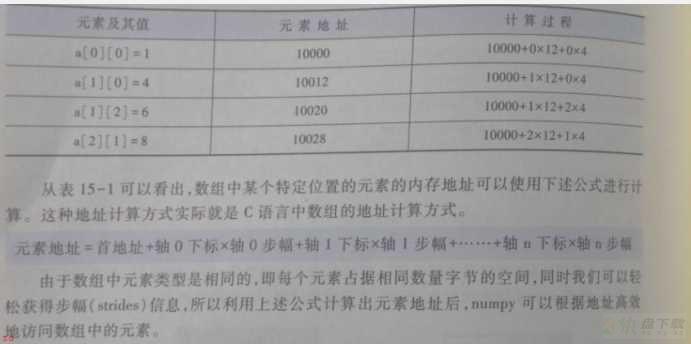
注意;上面的地址计算公式也是c语言的地址计算公式
import numpy as np
a = np.array([[1,2,3],[4,5,6],[7,8,9]],dtype=np.float32)
b = a[::2,::2]
print(;a=
;,a)
print(;b=
;,b)
print(;a.strides=;,a.strides) #;12,4;
print(;b.strides=;,b.strides) # ;24,8;
print(;a.data=;,a.data)
print(;b.data=;,b.data)
a= [[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] b= [[1. 3.] [7. 9.]] a.strides= (12, 4) b.strides= (24, 8) a.data= <memory at 0x000001C1DE4F0480> b.data= <memory at 0x000001C1DE4F0480>
上述案列分析;a形状是3行3列;b形状是2行2列。a.strides=;12,4; b.strides=;24,8; 。观察b中元素1和7;a中1和7的位置中相隔一行;正好是12的两倍 24;因此借助strides可以计算出数据的地址位置。注意;布尔类型、数组等进行访问时;strides就无法计算位置;只有复制元素进行操作
ufunc 是universal function的缩写;大多数的ufunc函数时都是通过C语言进行编写的。因为在对多维进行计算的时候需要进行循环;c语言的循环比python的循环效率要高。
下述代码我们以sin为列;;其他的三角函数;cos、tan、arctan;相似;
# 生产1~10pi 的1000个等差数列;并计算出对应的sin(),在通过matplotlib进行画图
import numpy as np
from matplotlib import pyplot as plt
x = np.linspace(0,10*np.pi,1000)
y = np.sin(x) # 会生成和x形状一样的数组
print(;x.shape=;,x.shape,;y.shape=;,y.shape)
# 展示10个
print(;x[::100]=;,x[::100])
print(;y[::100]=;,y[::100])
plt.plot(x,y)
plt.show()
x.shape= (1000,) y.shape= (1000,) x[::100]= [ 0. 3.14473739 6.28947478 9.43421217 12.57894956 15.72368695 18.86842435 22.01316174 25.15789913 28.30263652] y[::100]= [ 0. -0.00314473 0.00628943 -0.00943407 0.01257862 -0.01572304 0.0188673 -0.02201138 0.02515525 -0.02829886]

sin;;函数中还有一个参数是用来指定数据输出保存在那个一个数组中,是通过out
import numpy as np
x = np.linspace(0,10,10)
y = np.zeros(10)
t = np.sin(x,out=y) # sin()依然也会将数组赋值给t
print(;id(x)=;,id(x),;id(y)=;,id(y))
print(;y=;,y)
print(;t=;,t)
# 修改其中一个数组中值;发现是共享内存的
y[1] = 10
print(;y=;,y)
print(;t=;,t)
id(x)= 1932215179104 id(y)= 1932215354592 y= [ 0. 0.8961922 0.79522006 -0.19056796 -0.96431712 -0.66510151 0.37415123 0.99709789 0.51060568 -0.54402111] t= [ 0. 0.8961922 0.79522006 -0.19056796 -0.96431712 -0.66510151 0.37415123 0.99709789 0.51060568 -0.54402111] y= [ 0. 10. 0.79522006 -0.19056796 -0.96431712 -0.66510151 0.37415123 0.99709789 0.51060568 -0.54402111] t= [ 0. 10. 0.79522006 -0.19056796 -0.96431712 -0.66510151 0.37415123 0.99709789 0.51060568 -0.54402111]


import numpy as np
a = np.array([1,3,5],dtype=np.float32)
b = np.array([2,4,6],dtype=np.int)
c1 = np.add(a,b)
c2 = a;b
print(;c1=;,c1)
print(;c2=;,c2)
# 注意;由于a是float类型的数据;而b是int类型的数据;因此结果会转换为float
c1= [ 3. 7. 11.] c2= [ 3. 7. 11.]
import numpy as np
a = np.array([1,2,3])
b = np.array([3,2,1])
print(;a<b=;,a<b) # 注意是两个数组中对应下标的元素进行比较
print(;a<b=;,np.less(a,b)) # 但是建议还是直接使用运算符
a<b= [ True False False] a<b= [ True False False]
import numpy as np
a = np.array([1,2,3])
b = np.array([3,2,1])
print(a>b)
print(a==b)
print(;a>b or a==b:;,np.logical_or(a>b,a == b)) # a>b or a==b
print(;np.all(a>b):;,np.all(a>b)) # 只有全部a都大于b的时候;才是True
print(;np.any(a>b):;,np.any(a>b)) # 当其中只要有一个是a>b的时候;是True
[False False True] [False True False] a>b or a==b: [False True True]
当标准的ufunc函数不能满足我们使用的时候;我们可自定义ufunc函数。自定义ufunc函数一样可以作用域数组每一个元素。自定义ufunc函可用c语言、
python;缺点;执行效率低;、c和python交叉
import numpy as np
import math
from matplotlib import pyplot as plt
def signalcomp(x,freq):
y = math.cos(x)
y ;= 0.2*math.cos(freq*x)
retur
x = np.linspace(0,5*np.pi,1000)
ufunc1 = np.frompyfunc(signalcomp,2,1) # 构建自定义ufunc函数;第二个参数的2表示可以输入2个参数;第三个参数的1表示的是有1个结果返回
y = ufunc1(x,10).astype(np.float32) # 自定ufunc函数最后的结果是返回的object;因此我们需要对它进行数组类型转换
plt.plot(x,y)
plt.show()

数组形状相同可以进行运算操作;那么不同形状的数组如何进行操作;通过广播。

import numpy as np
a = np.arange(0,50,10).reshape(-1,1) # 5行1列的二维数组;通过确定列来确定行;
b = np.arange(0,4) # 生成长度为4的一维数组
c = a;b
print(;a.shape:;,a.shape,;b.shape:;,b.shape)
print(;a=
;,a)
print(;b=
;,b)
print(;c.shape:;,c.shape)
print(; c=
;,c)
;;;
c=a;b
1、满足上面广播规则第1条;将b数组转为二维数组;1,4; 1行4列的
2、满足广播规则第2条;输入数组;a是5行1列;b是1行4列 结果输出;为5行4列
3、满足广播规则第4条;c[3][2] = a[3][0];b[0][2]
;;;
a.shape: (5, 1) b.shape: (4,) a= [[ 0] [10] [20] [30] [40]] b= [0 1 2 3] c.shape: (5, 4) c= [[ 0 1 2 3] [10 11 12 13] [20 21 22 23] [30 31 32 33] [40 41 42 43]] ; c=a;b 1、满足上面广播规则第1条;将b数组转为二维数组;1,4; 1行4列的 2、满足广播规则第2条;输入数组;a是5行1列;b是1行4列 结果输出;为5行4列 ;
(1)、微实践–绘制二元函数曲面

补充知识;np.ogrid() 函数生成符合广播机制的数组
import numpy as np
x,y = np.ogrid[0:3:4j,0:4:5j]
print(;x=
;,x)
print(;y=
;,y)
print(;x.shape=;,x.shape) # x是4行1列的数组
print(;y.shape=;,y.shape) # y是1行5列的数组
x= [[0.] [1.] [2.] [3.]] y= [[0. 1. 2. 3. 4.]] x.shape= (4, 1) y.shape= (1, 5)
ogrid()是一个特殊函数;是通过切片的下标来生成数组;用于广播运算的数组;;注意;O:3:4j 类似于np.linsapce;0,3,4;生成0~3的长度为4的数组,而4j中j是语法格式。eg;x,y = np.ogrid[0:3:4j,0:4:5j] 生成x是4行1列;4,1;;y是1行5列的数组;1,5;
案例一;将x=[-2;;2],y=[-2;;2]的函数值矩阵绘制为平面图
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import cm
y,x = np.ogrid[-2:2:200j,-2:2:200j] # y 形状(200,1) x形状(1,200)
z = x*np.exp(-x**2-y**2)
extend1 = [np.min(x),np.max(x),np.min(y),np.max(y)] #x和y的界线
plt.imshow(z,cmap=cm.gray,extent=extend1) # 将z作为图像显示。cmap是指定颜色映射对象;该颜色映射对象负责把z中的元素值转换为像素点的颜色
plt.colorbar() # 通过颜色条来对应z中值与颜色的关系
plt.show()

案例二;将x=[-2;;2],y=[-2;;2]的函数值矩阵绘制为3d图
import numpy as np
import mpl_toolkits.mplot3d
from matplotlib import pyplot as plt
from matplotlib import cm
x,y = np.mgrid[-2:2:20j,-2:2:20j] #mgrid和ogrid是相似的;只是mgrid将形状扩充成为矩阵;20,1;->(20,20)
z = x*np.exp(-x**2--y**2)
fig = plt.figure(figsize=(8,6))
ax = fig.gca(projection=;3d;)
ax.plot_surface(x,y,z,cmap=cm.ocean) # ax是子图;由于ax.plot_surface()要求是x,y,z三个数组形状相同
plt.show()

from numpy import random as nr
r1 = nr.rand(3,3) # 生成0~1的随机数;3;3表示3行3列
r2 = nr.randn(3,3) # 标准正态分布的随机数 ;3行3列
r3 = nr.randint(0,10,(3,3)) # 生成3行3列;0~9;不包含10;的随机整数
print(r1)
print(r2)
print(r3)
[[0.42866666 0.01237853 0.84190471] [0.78209189 0.69903899 0.30133983] [0.69286253 0.0074816 0.43684253]] [[-0.37057477 -0.29598364 -0.32416453] [-1.14480703 0.19834707 0.3658034 ] [-0.63920883 -0.15876545 0.93713387]] [[5 8 1] [4 0 8] [4 6 5]] [0 0]
其他随机数表
python或者numpy中随机数;都是伪随机数;即随机数是以种子为基础迭代计算。从相同的随机数出发可以获取相同的随机数序列。
from numpy import random as nr
import numpy as np
from matplotlib import pyplot as plt
heights = nr.normal(170,30,(10000,)).astype(int) #生成标准值为170;方差为30,10000个样本的随机数组
stats = np.zeros((10000,)) # 生成一个 10000的一维数组
print(stats.shape,stats.ndim)
for i in range(10000):
stats[heights[i]];=1 # stats以身高为下标;统计heights中有多少人;将人数赋值个对应下标的元素;即人数就是stats的元素值
plt.plot(stats[:300])
plt.show()
[199 131 190 188 133 185 192 175 223 155] (10000,) 1

import numpy as np
from numpy import random as nr
nr.seed(2022) # 设置随机种子;可以使多次运行的结果相同
a = nr.randint(0,10,size=(3,5))
print(;a=
;,a)
print(;np.sum(a)=;,np.sum(a)) # 是数组中的全部元素进行统计
print(;np.sum(a,axis=1)=;,np.sum(a,axis=1)) # 相同行进行统计
print(;np.sum(a,axis=0)=;,np.sum(a,axis=0)) # 相同列进行统计
a= [[0 1 1 0 7] [8 2 8 0 5] [9 1 3 8 0]] np.sum(a)= 53 np.sum(a,axis=1)= [ 9 23 21] np.sum(a,axis=0)= [17 4 12 8 12]
平均函数 mean()与加权平均函数average()
import numpy.random as nr
import numpy as np
nr.seed(2022) #相同的随机种子;后面的随机序列的数组相同
a = nr.randint(0,10,(3,5))
print(;a=
;,a)
print(;np.mean(a)=;,np.mean(a))
print(;np.mean(a,axis=1)=;,np.mean(a,axis=1)) # 相同的行算平均数
a= [[0 1 1 0 7] [8 2 8 0 5] [9 1 3 8 0]] np.mean(a)= 3.533333333333333 np.mean(a,axis=1)= [1.8 4.6 4.2]
# 加权平均数
import numpy as np
score = np.array([66,77,88])
weights = np.array([0.3,0.5,0.2])
print(;np.average(score,weights=weights)=;,np.average(score,weights=weights)) # weight 是权数
np.average(score,weights=weights)= 75.9
补充知识;
比较函数与排序函数
# sort的案例
import numpy as np
from numpy import random as nr
nr.seed(2022) # 设置相同的随机数种子
a = nr.randint(0,10,size=(3,5))
print(;a=
;,a)
print(;np.sort(a)=
;,np.sort(a)) # sort 进行排序;axis默认是-1;一般是最大轴 eg;二维数 中轴1是最大的
print(;np.sort(a,axis=None)=
;,np.sort(a,axis=None)) # 如果axis为None会先将数组转为一维数组;在进行排序
print(;np.sort(a,axis=1)=
;,np.sort(a,axis=1)) # axis =1 是按照行进行排序;如果是axis=0是按照列进行排序
print(;np.argsort(a,axis=1)=
;,np.argsort(a,axis=1)) # argsort 是获取按行进行排序后数据的下标
a= [[0 1 1 0 7] [8 2 8 0 5] [9 1 3 8 0]] np.sort(a)= [[0 0 1 1 7] [0 2 5 8 8] [0 1 3 8 9]] np.sort(a,axis=None)= [0 0 0 0 1 1 1 2 3 5 7 8 8 8 9] np.sort(a,axis=1)= [[0 0 1 1 7] [0 2 5 8 8] [0 1 3 8 9]] np.argsort(a,axis=1)= [[0 3 1 2 4] [3 1 4 0 2] [4 1 2 3 0]]
# maximum、minimum
import numpy as np
a = np.array([2,4,6,8])
b = np.array([1,3,5,7])
print(;np.maximum(a,b)=;,np.maximum(a,b)) # 比较a、b对应下标的元素的大小;大的则保存新的数组中
print(;a[None,:]=;,a[None,:]) # a.reshape(1,-1) 生成1行4列的数组
print(;b[:,None]=
;,b[:,None]) # b.reshape(-1,1) 生成5行1列的数组
print(;np.maximum(a[None,:],b[:,None])=
;,np.maximum(a[None,:],b[:,None]))
np.maximum(a,b)= [2 4 6 8] a[None,:]= [[2 4 6 8]] b[:,None]= [[1] [3] [5] [7]] np.maximum(a[None,:],b[:,None])= [[2 4 6 8] [3 4 6 8] [5 5 6 8] [7 7 7 8]]
np.maximum(a[None,:],b[:,None])
需要将a和b广播机制成为4行4列的元素;下面分别是a和b广播机制后的
a 广播机制后的数组
b广播机制
# searchsorted;;折半查找法;确定插入位置
import numpy as np
a = np.array([0,2,4,9,10]) # 有序数组
b = np.array([0,1,2,2,4,4,5,8])
print(np.searchsorted(a,b)) # searchsorted会将b在a中进查找 eg; b[6] 属于的a[2]~~[3]之间所有返回下标3。 b[7] 在a[2]~~~[3]之间;下标为3
[0 1 1 1 2 2 3 3]
补充知识;
import numpy as np
from numpy import random as nr
nr.seed(2022)
a = nr.randint(0,5,(2,3)) # 2行3列
b = nr.randint(0,5,(3,2)) # 3行2列
print(;a=
;,a)
print(;b=
;,b)
c = np.dot(a,b) # a*b ;2;3;*;3;2; 构成了;2;2;
print(;c=
;,c)
d = np.dot(b,a) # b*a (3,2)*(2,3) 构成了;3;3;
print(d)
a= [[4 0 1] [1 0 0]] b= [[2 0] [0 1] [1 3]] c= [[9 3] [2 0]] [[8 0 2] [1 0 0] [7 0 1]]
分割;
import numpy as np
arr = np.arange(0,12).reshape(3,4) # 3行 4列
arr1 = np.arange(2,14).reshape(3,4)
print(np.concatenate((arr,arr1),axis=1)) # 行不变;列增加
print(np.concatenate((arr,arr1))) # 列不变;行增加
print(np.hstack((arr1,arr))) # 行不变;列增加
print(np.vstack((arr1,arr))) # 列不变;行增加
[[ 0 1 2 3 2 3 4 5] [ 4 5 6 7 6 7 8 9] [ 8 9 10 11 10 11 12 13]] [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [ 2 3 4 5] [ 6 7 8 9] [10 11 12 13]] [[ 2 3 4 5 0 1 2 3] [ 6 7 8 9 4 5 6 7] [10 11 12 13 8 9 10 11]] [[ 2 3 4 5] [ 6 7 8 9] [10 11 12 13] [ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]
import numpy as np
arr = np.arange(12).reshape(3,4)
print(arr.tolist(),type(arr.tolist()))
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]] <class ;list;>
import numpy as np
# 使用字符串来创建矩阵
str = ;1 2 3;4 5 6;7 8 9;
a = np.mat(str)
a[1,1] = 1
print(;查看修改后的a和str
;,a,;
;,str) # a矩阵发生了变化;但是str没有发生变化
# 使用嵌套序列创建矩阵
a1 = np.mat([[2,4,6,8],[1.0,3,5,7.0]])
print(;嵌套序列创建矩阵;
;,a1)
# 使用数组创建矩阵
arr = np.arange(9).reshape(3,3)
a2 = np.mat(arr)
print(;数组创建矩阵:
;,a2)
查看修改后的a和str [[1 2 3] [4 1 6] [7 8 9]] 1 2 3;4 5 6;7 8 9 嵌套序列创建矩阵; [[2. 4. 6. 8.] [1. 3. 5. 7.]] 数组创建矩阵: [[0 1 2] [3 4 5] [6 7 8]]
格式;numpy.savetxt(fname,array,fmt=“%.18e”,delimiter=None,newline=‘ ’,header=‘’,footer=‘’,comments=‘#’,encoding=None)
import numpy as np
arr = np.arange(12).reshape(3,4)
# fmt 默认是%.18(字符串),分隔符是空格
np.savetxt(;test1.txt;,arr)
# 写入文件的为十进制整数
np.savetxt(;test2.txt;,arr,fmt=%d;,delimiter=;,;)
#加上注释
np.savetxt(;test3.txt;,arr,fmt=%d;,delimiter=;,;,header=;练习在开头插入字符串啦;,footer=;和开头的字符串一样呀;)
# 修改comments注释符
np.savetxt(;test4.csv;,arr,fmt=%d;,delimiter=;,;,header=;注意观察开头的符号是什么;还是不是#开头的啦;,)
使用函数loadtxt(),该函数格式;numpy.loadtxt(fname,dtype=<type “float”>,comments=“#”,delimiter=None,converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0,encoding=“bytes”)
import numpy as np
arr = np.zeros((3,5),dtype=np.int32)
print(arr)
[[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0]]
import numpy as np
arr = np.arange(16).reshape(4,4)
# print(arr)
# 切片
print(arr[1,:])
#元组来进行切片
print(arr[(1,1,1,1),(0,1,2,3)])
# 数据进行切片
print(arr[[1,1,1,1],[0,1,2,3]])
print(arr[1:3,1:3])
[4 5 6 7] [4 5 6 7] [4 5 6 7] [[ 5 6] [ 9 10]]
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.show()

import matplotlib.pyplot as plt
plt.plot([1,2,3,4],[1,4,9,16],;rv;)
plt.axis([0,5,0,18]) # 前面两个是 x轴 起点和终点 ;后面两个是y轴的起点和终点
plt.show()

import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,10,100)
y = np.cos(x)
plt.plot(x,y)
plt.axis([0,10,-1,1])
plt.show()







