Flink简介
Flink 是一个框架和分布式处理引擎;用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务;DataSet API、DataStream API、Table API等
Flink跟Spark Streaming的区别
Flink 是标准的实时处理引擎;基于事件驱动。而 Spark Streaming 是微批的模型。
下面我们就分几个方面介绍两个框架的主要区别;
1;架构模型Spark Streaming 在运行时的主要角色包括;Master、Worker、Driver、Executor;Flink 在运行时主要包含;Jobmanager、Taskmanager和Slot。
2;任务调度Spark Streaming 连续不断的生成微小的数据批次;构建有向无环图DAG;Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成 StreamGraph;经过优化生成 JobGraph;然后提交给 JobManager进行处理;JobManager 会根据 JobGraph 生成 ExecutionGraph;ExecutionGraph 是 Flink 调度最核心的数据结构;JobManager 根据 ExecutionGraph 对 Job 进行调度。
3;时间机制Spark Streaming 支持的时间机制有限;只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义;处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
4;容错机制对于 Spark Streaming 任务;我们可以设置 checkpoint;然后假如发生故障并重启;我们可以从上次 checkpoint 之处恢复;但是这个行为只能使得数据不丢失;可能会重复处理;不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。
Flink架构
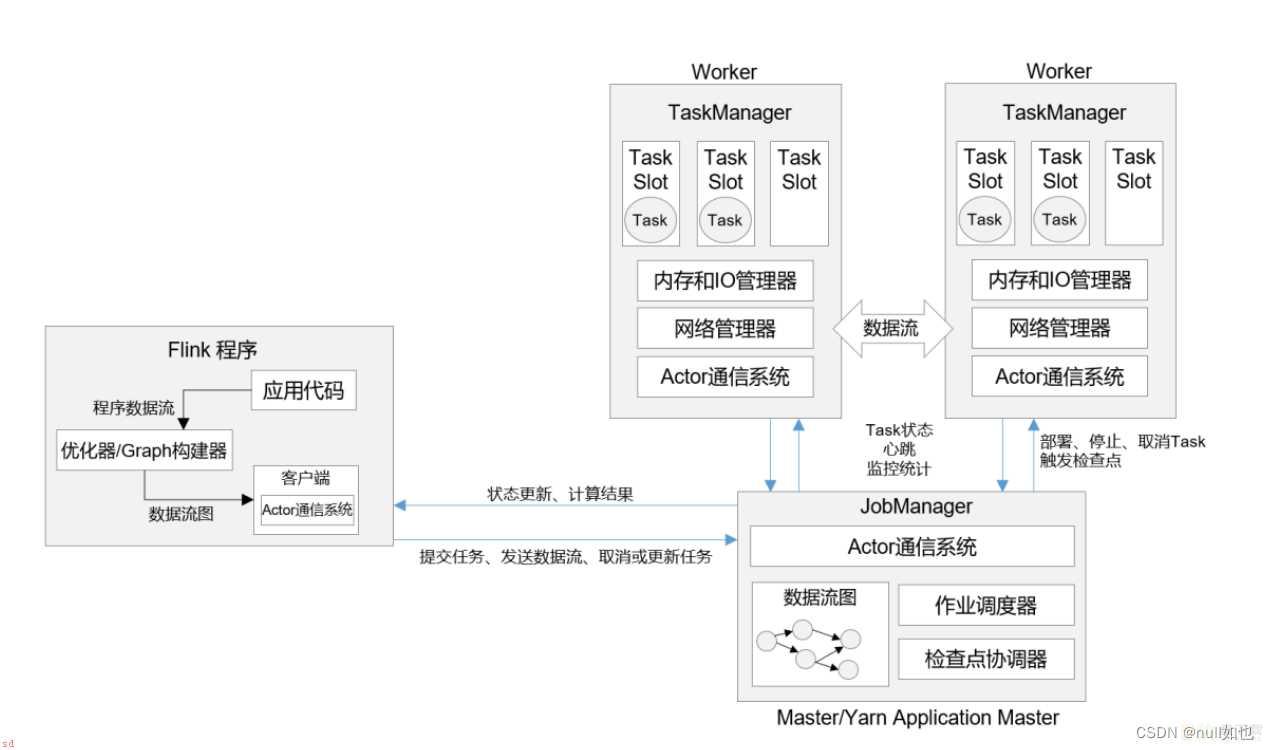
Flink程序在运行时主要有TaskManager;JobManager;Client三种角色。
JobManager
扮演着集群中的管理者Master的角色;它是整个集群的协调者;负责接收Flink Job;协调检查点;Failover 故障恢复等;同时管理Flink集群中从节点TaskManager。
JobManger 又包含 3 个不同的组件
JobMaster 是 JobManager 中最核心的组件;负责处理单独的作业;Job;。所以 JobMaster 和具体的 Job 是一一对应的;多个 Job 可以同时运行在一个 Flink 集群中, 每个 Job 都有一个 自己的 JobMaster。
在作业提交时;JobMaster 会先接收到要执行的应用。这里所说“应用”一般是客户端提 交来的;包括;Jar 包;数据流图;dataflow graph;;和作业图;JobGraph;。
JobMaster 会把 JobGraph 转换成一个物理层面的数据流图;这个图被叫作“执行图” ;ExecutionGraph;;它包含了所有可以并发执行的任务。 JobMaster 会向资源管理器 ;ResourceManager;发出请求;申请执行任务必要的资源。一旦它获取到了足够的资源;就会将执行图分发到真正运行它们的 TaskManager 上。
而在运行过程中;JobMaster 会负责所有需要中央协调的操作;比如说检查点;checkpoints; 的协调。
ResourceManager 主要负责资源的分配和管理;在 Flink 集群中只有一个。所谓“资源”; 主要是指 TaskManager 的任务槽;task slots;。任务槽就是 Flink 集群中的资源调配单元;包含 了机器用来执行计算的一组 CPU 和内存资源。每一个任务;Task;都需要分配到一个 slot 上 执行。
Flink 的 ResourceManager;针对不同的环境和资源管理平台;比如 Standalone 部署;或者 YARN;;有不同的具体实现。在 Standalone 部署时;因为 TaskManager 是单独启动的;没有 Per-Job 模式;;所以 ResourceManager 只能分发可用 TaskManager 的任务槽;不能单独启动新 TaskManager。 而在有资源管理平台时;就不受此限制。当新的作业申请资源时;ResourceManager 会将 有空闲槽位的 TaskManager 分配给 JobMaster。如果 ResourceManager 没有足够的任务槽;它 还可以向资源提供平台发起会话;请求提供启动 TaskManager 进程的容器。另外; ResourceManager 还负责停掉空闲的 TaskManager;释放计算资源。
Dispatcher 主要负责提供一个 REST 接口;用来提交应用;并且负责为每一个新提交的作 业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI;用来方便地展示和监控作 业执行的信息。Dispatcher 在架构中并不是必需的;在不同的部署模式下可能会被忽略掉。
TaskManager
是实际负责执行计算的Worker;在其上执行Flink Job的一组Task;每个TaskManager负责管理其所在节点上的资源信息;如内存、磁盘、网络;在启动的时候将资源的状态向JobManager汇报。
每一个 TaskManager 都包含了一定数量的任务槽;task slots;。Slot 是资源调度的最小单位;slot 的数量限制了 TaskManager 能够并行处理的任务数量。
启动之后;TaskManager 会向资源管理器注册它的 slots;收到资源管理器的指令后; TaskManager 就会将一个或者多个槽位提供给 JobMaster 调用;JobMaster 就可以分配任务来执 行了。
在执行过程中;TaskManager 可以缓冲数据;还可以跟其他运行同一应用的 TaskManager 交换数据。
Client
Flink程序提交的客户端;当用户提交一个Flink程序时;会首先创建一个Client;该Client首先会对用户提交的Flink程序进行预处理;调用程序的 main 方法;将代码转换成数据流图并最终生成作业图;一并发送给 JobManager;;并提交到Flink集群中处理;所以Client需要从用户提交的Flink程序配置中获取JobManager的地址;并建立到JobManager的连接;将Flink Job提交给JobManager。
Yarn集群下作业提交流程
会话;Session;模式
在会话模式下;我们需要先启动一个 YARN session;这个会话会创建一个 Flink 集群。

这里只启动了 JobManager;而 TaskManager 可以根据需要动态地启动。在 JobManager 内 部;由于还没有提交作业;所以只有 ResourceManager 和 Dispatcher 在运行
在这里插入图片描述
;1;客户端通过 REST 接口;将作业提交给分发器。
;2;分发器启动 JobMaster;并将作业;包含 JobGraph;提交给 JobMaster。
;3;JobMaster 向资源管理器请求资源;slots;。
;4;资源管理器向 YARN 的资源管理器请求 container 资源。
;5;YARN 启动新的 TaskManager 容器。
;6;TaskManager 启动之后;向 Flink 的资源管理器注册自己的可用任务槽。
;7;资源管理器通知 TaskManager 为新的作业提供 slots。
;8;TaskManager 连接到对应的 JobMaster;提供 slots。
;9;JobMaster 将需要执行的任务分发给 TaskManager;执行任务。
单作业;Per-Job;模式;详细流程;

;1;脚本启动执行;解析参数;创建对应的客户端。客户端执行用户代码;生成StreamGraph;调用YarnJobClusterExecutor生成JobGraph;其中YarnClusterDescriptor上传jar包、配置、数据流图和作业图到HDFS;封装提交参数和命令通过YarnClient提交任务信息给ResourceManager
;2;ResourceManager选择一个nodeManger创建Container启动ApplicationMaster
;3;ApplicationMaster启动Dispatcher和ResourceManger;Dispatcher启动JobMaster;JobMaster生成ExecutionGraph
;4;JobMaster中的SlotPool向ResourceManger中的SlotManger注册、请求slot
;5;ResourceManager向Yarn的ResourceManager申请资源
;6;找到合适的NodeManager创建Container;启动TaskManager
;7;YarnTaskExcutorRunner调用runTaskManager启动TaskExecutor
;8;TaskExecutor向ResourceManager的SlotManager注册slot
;9;ResourceManager分配slot给TaskExecutor
;10;TaskExecutor提供slot给JobMaster中的SlotPool
;11;JobMaster 将需要执行的任务分发给 TaskManager;执行任务。
Task
Task的生成流程

逻辑流图;StreamGraph; 这是根据用户通过 DataStream API 编写的代码生成的最初的 DAG 图;用来表示程序的拓 扑结构。这一步一般在客户端完成。
作业图;JobGraph; StreamGraph 经过优化后生成的就是作业图;JobGraph;;这是提交给 JobManager 的数据结构;确定了当前作业中所有任务的划分。主要的优化为: 将多个符合条件的节点链接在一起 合并成一个任务节点;形成算子链;这样可以减少数据交换的消耗。JobGraph 一般也是在客 户端生成的;在作业提交时传递给 JobMaster。 在图 4-12 中;分组聚合算子;Keyed Aggregation;和输出算子 Sink(print)并行度都为 2; 而且是一对一的关系;满足算子链的要求;所以会合并在一起;成为一个任务节点。
执行图;ExecutionGraph; JobMaster 收到 JobGraph 后;会根据它来生成执行图;ExecutionGraph;。ExecutionGraph 是 JobGraph 的并行化版本;是调度层最核心的数据结构。 与 JobGraph 最大的区别就是按照并行度对并行子任务进行了拆分; 并明确了任务间数据传输的方式。
物理图;Physical Graph; JobMaster 生成执行图后; 会将它分发给 TaskManager;各个 TaskManager 会根据执行图部署任务;最终的物理执行过程也会形成一张“图”;一般就叫作物理图;Physical Graph;。 这只是具体执行层面的图;并不是一个具体的数据结构。 物理图主要就是在执行图的基础上;进一步确定数据存放的位置和收发的具体方式。有了物理图;TaskManager 就可以对传递来的数据进行处理计算了。 一共有 5 个并行子任务;最终需要 5 个线程来执行。
算子链;Operator Chain;
在 Flink 中;并行度相同的一对一;one to one;算子操作;可以直接链接在一起形成一个 “大”的任务;task;;这样原来的算子就成为了真正任务里的一部分。每个 task 会被一个线程执行。这样的技术被称为“算子链”;Operator Chain;。
算子操作间除了一对一;one to one;的关系;还有由keyBy和并行度改变引起的重分区;redistributing;关系
任务槽;Task Slots;
slot 目前仅仅用来隔离内存;不会涉及 CPU 的隔离。在具体应用时;可 以将 slot 数量配置为机器的 CPU 核心数;尽量避免不同任务之间对 CPU 的竞争。这也是开发 环境默认并行度设为机器 CPU 数量的原因。
任务槽默认开启子任务共享

Flink的并行度
Flink中的任务被分为多个并行任务来执行;其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。我们在实际生产环境中可以从四个不同层面设置并行度;
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级;算子层面>环境层面>客户端层面>系统层面。
并行度的设置;一般设为kafka的分区数;达到1;1
遵循2的n次方;比如2、4、8、16…..
分区、分组
分区;算子的一个并行实例可以理解成一个分区;是物理上的资源
分组;数据根据key进行区分;是一个逻辑上的划分
一个分区可以有多个分组;同一个分组的数据肯定在同一个分区
DataStream API;基础;
执行环境;Execution Environment;
getExecutionEnvironment;根据上下文;自行判断返回 本地执行环境 还是 集群执行环境
createLocalEnvironment;本地执行环境
createRemoteEnvironment;集群执行环境
源算子;Source;
fromCollection;从集合中读取数据
readTextFile;从文件读取数据
socketTextStream;从 Socket 读取数据
addSource();自定义输入
转换算子;Transformation;
map;映射
filter;过滤
flatMap;扁平映射
keyBy;按键分区;得到KeyedStream
sum()/min()/max()/minBy()/maxBy();keyBy后简单聚合;得到DataStream
reduce();keyBy后归约聚合;得到DataStream
自定义函数
shuffle();随机分区
rebalance();轮询分区
rescale();重缩放分区
broadcast();广播
global();全局分区
自定义分区
windowAll();开窗;得到WindowedStream
window();keyedStream开窗;得到WindowedStream
窗口函数;
reduce(ReduceFunction);来一条聚合一条
aggregate(AggregateFunction);取消类型一致的限制;来一条聚合一条
appl(WindowFunction);全部要来了聚合;有窗口信息
process(ProcessWindowFunction);处理函数;有更多信息
输出算子;Sink;
print();控制台打印输出
addSink();自定义输出
程序执行;execute;
显式地调用执行环境的 execute()方法;来触发程序执行
处理函数
;1;ProcessFunction
最基本的处理函数;基于 DataStream 直接调用.process()时作为参数传入。
;2;KeyedProcessFunction
对流按键分区后的处理函数;基于 KeyedStream 调用.process()时作为参数传入。要想使用 定时器;比如基于 KeyedStream。
;3;ProcessWindowFunction
开窗之后的处理函数;也是全窗口函数的代表。基于 WindowedStream 调用.process()时作 为参数传入。
;4;ProcessAllWindowFunction
同样是开窗之后的处理函数;基于 AllWindowedStream 调用.process()时作为参数传入。
;5;CoProcessFunction
合并;connect;两条流之后的处理函数;基于 ConnectedStreams 调用.process()时作为参 数传入。关于流的连接合并操作;我们会在后续章节详细介绍。
;6;ProcessJoinFunction
间隔连接;interval join;两条流之后的处理函数;基于 IntervalJoined 调用.process()时作为 参数传入。
;7;BroadcastProcessFunction
广播连接流处理函数;基于 BroadcastConnectedStream 调用.process()时作为参数传入。这 里的“广播连接流”BroadcastConnectedStream;是一个未 keyBy 的普通 DataStream 与一个广 播流;BroadcastStream;做连接;conncet;之后的产物。
;8;KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数;同样是基于 BroadcastConnectedStream 调用.process()时 作为参数传入。与 BroadcastProcessFunction 不同的是;这时的广播连接流;是一个 KeyedStream 与广播流;BroadcastStream;做连接之后的产物。
算子实现原理
Keyby实现原理
对指定的key调用自身的hashCode方法=》hash1
调用murmruhash算法;进行第二次hash =》键组ID 通过一个公式;计算出当前数据应该去往哪个下游分区; 键组id * 下游算子并行度 / 最大并行度;默认128;
interval join实现原理
底层调用的是keyby;connect ;处理逻辑;
1;判断是否迟到;迟到就不处理了; 2;每条流都存了一个Map类型的状态;key是时间戳;value是List存数据; 3;任一条流;来了一条数据;遍历对方的map状态;能匹配上就发往join方法 4;超过有效时间范围;会删除对应Map中的数据;不是clear;是remove;
整个处理逻辑都是基于数据时间的;也就是intervaljoin 必须基于EventTime语义;在between 中有做TimeCharacteristic是否为EventTime校验, 如果不是则抛出异常。
多流转换
分流;侧输出流
合流;Union、Connect、Window Join、Interval Join、Window CoGroup
Flink的状态
状态分类;
托管状态
算子状态
列表状态、联合列表状态、广播状态
键控状态
值状态、列表状态、映射状态、归约状态、聚合状态
原始状态
算子状态;作用范围是算子;算子的多个并行实例各自维护一个状态
键控状态;每个分组维护一个状态
状态后端;两件事=》 本地状态存哪里、checkpoint存哪里
1.13前 本地状态 Checkpoint 内存 TaskManager的内存 JobManager内存 文件 TaskManager的内存 HDFS RocksDB RocksDB HDFS 1.13 本地状态 Checkpoint
哈希表 TaskManager的内存 JobManager内存/HDFS
RocksDB RocksDB HDFS
Flink的三种时间语义
Event Time;是事件创建的时间。它通常由事件中的时间戳描述;例如采集的日志数据中;每一条日志都会记录自己的生成时间;Flink通过时间戳分配器访问事件时间戳。
Ingestion Time;是数据进入Flink的时间。
Processing Time;是每一个执行基于时间操作的算子的本地系统时间;与机器相关;默认的时间属性就是Processing Time。
Flink 中的Watermark机制
Watermark的简介
1;Watermark 是一种衡量 Event Time 进展的机制;可以设定延迟触发
2;Watermark 是用于处理乱序事件的;而正确的处理乱序事件;通常用Watermark 机制结合 window 来实现;
3;基于事件时间;用来触发窗口、定时器等
4;watermark主要属性就是时间戳;可以理解一个特殊的数据;插入到流里面
5;watermark是单调不减的
6;数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据;都已经到达了;如果后续还有timestamp 小于 Watermark 的数据到达;称为迟到数据
Watermark的生成
Watermark是一条携带时间戳的特殊数据;从代码指定生成的位置;插入到流里面。
间歇性;来一条数据;更新一次watermark
周期性;固定周期更新watermark
官方提供的api是基于周期的;默认200ms;因为间歇性会给系统带来压力。
Watermark=当前最大事件时间-乱序时间-1ms
Watermark的传递
一对多;广播
多对一;取最小
多对多;拆分来看;其实就是上面两种的结合
Flink的窗口
1;窗口分类; Keyed Window和Non-keyed Window
基于时间;滚动、滑动、会话 基于数量;滚动、滑动
2;Window口的4个相关重要组件;
assigner;分配器;;如何将元素分配给窗口
function;计算函数;;为窗口定义的计算。其实是一个计算函数;完成窗口内容的计算。
triger;触发器;;在什么条件下触发窗口的计算
evictor;退出器;;定义从窗口中移除数据
3;窗口的划分;如;基于事件时间的滚动窗口
start=按照数据的事件时间向下取窗口长度的整数倍;timestamp-(timestamp-offset;windowSize)%windowSize;
end=start;size
比如开了一个10s的滚动窗口;第一条数据是857s;那么它属于[850s,860s)
4;窗口的创建;当属于某个窗口的第一个元素到达;Flink就会创建一个窗口;
5;窗口的销毁;当时间超过其结束时间;用户指定的允许延迟时间;Flink保证只删除基于时间的窗口;而不能删除其他类型的窗口;例如全局窗口;。
6;窗口为什么左闭右开;属于窗口的最大时间戳=end-1ms
7;窗口什么时候触发;如基于事件时间的窗口 watermark>=end-1ms
Flink迟到数据的处理
设置水位线延迟时间
水位线一旦延迟;窗口的关闭;定时器的触发都会延迟
允许窗口处理迟到数据
在水位线到达窗口结束时间时;先快速地输出一个近似正确的计算结果;
然后保持窗口继续等到延迟数据;每来一条数据;窗口就会再次计算;并将更新后的结果输出。
将迟到数据放入窗口侧输出流
用窗口的侧输出流来收集关窗以后的迟到数据。
Flink的检查点
检查点主要配置
1;间隔;1min~10min;3min
2;模式;exactly-once;默认;;at-least-once
因为一些异常原因可能导致某些barrier无法向下游传递;造成job失败;对于一些时效性要求高、精准性要求不是特别严格的指标;可以设置为至少一次。
3;超时 ; 参考间隔; 0.5~2倍之间; 建议0.5倍
4;最小等待间隔;上一次ck结束 到 下一次ck开始 之间的时间间隔;设置间隔的0.5倍
5;最大并发检查点数量;用于指定运行中的检查点最多可以有多少个
6;不对齐检查点;不再执行检查点的分界线对齐操作;启用之后可以大大减少产生背压时的检查点保存时 间。这个设置要求检查点模式;CheckpointingMode;必须为 exctly-once;并且并发的检查点 个数为 1。
7;开启外部持久化存储;DELETE_ON_CANCELLATION;在作业取消的时候会自动删除外部检查点;但是如果是作业失败退出;则会保留检查点。 RETAIN_ON_CANCELLATION;作业取消的时候也会保留外部检查点。
检查点算法
在数据流中插入一个特殊的数据结构; 专门用来表示触发检查点保存的时间点。收到保存检查点的指令后;Source 任务可以在当前 数据流中插入这个结构;之后的所有任务只要遇到它就开始对状态做持久化快照保存。
与水位线很类似;检查点分界线也是一条特殊的数据;由 Source 算子注入到常规的数据 流中;它的位置是限定好的;不能超过其他数据;也不能被后面的数据超过。检查点分界线中 带有一个检查点 ID;这是当前要保存的检查点的唯一标识。
Flink 使用了 Chandy-Lamport 算法的一种变体;被称为“异步分界线快照” ;asynchronous barrier snapshotting;算法。算法的核心就是两个原则;当上游任务向多个并行 下游任务发送 barrier 时;需要广播出去;而当多个上游任务向同一个下游任务传递 barrier 时; ;exactly-once模式下;需要在下游任务执行“分界线对齐”操作;也就是需要等到所有并行分区 的 barrier 都到齐;才可以开始状态的保存。分界线在等待对齐的时候;可能需要缓存下一个检查点要保存的内容;在作业出现反压时可能会成为不定时炸弹。
ABS算法步骤;
a) Source算子接收到 Jobmanager产生的屏障,生成自己状态的快照(其中包含数据源对应的 offset/ position信息),并将屏障广播给下游所有数据流
b)下游非 Sources的算子从它的某个输入数据流接收到屏障后,会阻塞这个输入流,继续接收其他输入流,直到所有输入流的屏障都到达;这个等待的过程就叫做对齐( alignment),注意算子内部有个输入缓冲区,用来在对齐期间缓存数据;。一旦算子收齐了所有屏障,它就会生成自己状态的快照,并继续将屏障广播给下游所有数据流
c)快照生成后,算子解除对输入流的阻塞,继续进行计算。Sink算子接收到屏障之后会向 Jobmanager确认,所有Sink都确认收到屏障;标记着这周期 checkpoint过程结東,快照成功保存。
3.分界线不对齐;barrier unalignment;
at-least-once 模式下分界线不需要对齐;
Flink 1.11 之后提供了exactly-once模式下不对齐的检查点保存方式;这样其他分区的有些数据的状态就没有保存到检查点;所以还需要将未处理的缓冲数据;in-flight data;也保存进检查点才是当前完整的“快照”。
总而言之;当我们遇到一个分区 barrier 时就不需等待对齐;而是可以直接启动状态和未处理数据的保存。
Flink的保存点
它的原理和算法与检查点完全相同;只是多了一些额外的元数据。检查点是自动触发的;而保存点需要命令行触发或者web控制台触发。
事实上;保存点就是通过检查点的机制来创建流式作业状态的一致性镜像;consistent image;的。
保存点中的状态快照;是以算子 ID 和状态名称组织起来的;相当于一个键值对。从保存 点启动应用程序时;Flink 会将保存点的状态数据重新分配给相应的算子任务。
端到端精确一次;end-to-end exactly-once;
一般说的是端到端一致性;要考虑source和sink;
Source;数据源可重放数据;或者说可重置读取数据偏移量;加上 Flink 的 Source 算子将偏移量作为状态保存进检查点;就可以保证数据不丢。
Flink内部;Checkpoint机制;介绍Chandy-Lamport算法、barrier对齐;
Sink;幂等写入 事务写入;预写日志;WAL;和两阶段提交;2PC;;
预写日志;WAL;就是一种非常简单的方式。具体步骤是; ①先把结果数据作为日志;log;状态保存起来 ②进行检查点保存时;也会将这些结果数据一并做持久化存储 ③在收到检查点完成的通知时;将所有结果一次性写入外部系统。
两阶段提交先做“预提交”;等检查点完成之后再正式提交。 具体的实现步骤为; ①当第一条数据到来时;或者收到检查点的分界线时;Sink 任务都会启动一个事务。 ②接下来接收到的所有数据;都通过这个事务写入外部系统;这时由于事务没有提交;所 以数据尽管写入了外部系统;但是不可用;是“预提交”的状态。 ③当 Sink 任务收到 JobManager 发来检查点完成的通知时;正式提交事务;写入的结果就 真正可用了。
我们使用的Source和Sink主要是Kafka;
作为source可以重发;由Flink维护offset;作为状态存储 作为sink官方的实现类是基于两阶段提交;能保证写入的Exactly-Once
如果下级存储不支持事务;
具体实现是幂等写入;需要下级存储具有幂等性写入特性。
比如结合HBase的rowkey的唯一性、数据的多版本;实现幂等
Table API 和 SQL
JOIN
状态TTL;tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(10))
状态更新策略;
join;左表OnCreateAndWrite 右表OnCreateAndWrite
left join;左表OnReadAndWrite 右表OnCreateAndWrite
right join;左表OnCreateAndWrite右表OnReadAndWrite
full join;左表OnReadAndWrite右表OnReadAndWrit
lookup join:

Fink内存模型
JobManager 内存模型

TaskManager 内存模型

Flink数据倾斜
相同 Task 的多个 Subtask 中;个别 Subtask 接收到的数据量明显大于其他 Subtask 接收到的数据量;通过 Flink Web UI 可以精确地看到每个 Subtask 处理了多 少数据;即可判断出 Flink 任务是否存在数据倾斜。通常;数据倾斜也会引起反压。
keyBy 之前发生数据倾斜
如果 keyBy 之前就存在数据倾斜;上游算子的某些实例可能处理的数据较多;某些实 例可能处理的数据较少;产生该情况可能是因为数据源的数据本身就不均匀;例如由于某些 原因 Kafka 的 topic 中某些 partition 的数据量较大;某些 partition 的数据量较少。对于不存在 keyBy 的 Flink 任务也会出现该情况。
这种情况;需要让 Flink 任务强制进行 shuffle。使用 shuffle、rebalance 或 rescale 算子即可将数据均匀分配;从而解决数据倾斜的问题。
keyBy后的(无窗口)聚合操作存在数据倾斜
ocalKeyBy
在 keyBy 上游算子数据发送之前;首先在上游算子的本地对数据进行聚合后;再发送 到下游;使下游接收到的数据量大大减少;从而使得 keyBy 之后的聚合操作不再是任务的 瓶颈。类似 MapReduce 中 Combiner 的思想;但是这要求聚合操作必须是多条数据或 者一批数据才能聚合;单条数据没有办法通过聚合来减少数据量。从 Flink LocalKeyBy 实 现原理来讲;必然会存在一个积攒批次的过程;在上游算子中必须攒够一定的数据量;对这 些数据聚合后再发送到下游。
实现方式
➢ DataStreamAPI 需要自己写代码实现
➢ SQL 可以指定参数;开启 miniBatch 和 LocalGlobal 功能
keyBy后的窗口聚合操作存在数据倾斜
因为使用了窗口;变成了有界数据;攒批;的处理;窗口默认是触发时才会输出一条结 果发往下游;所以可以使用两阶段聚合的方式;
实现思路;
➢ 第一阶段聚合;key 拼接随机数前缀或后缀;进行 keyby、开窗、聚合 注意;聚合完不再是 WindowedStream;要获取 WindowEnd 作为窗口标记作为第二 阶段分组依据;避免不同窗口的结果聚合到一起;
➢ 第二阶段聚合;按照原来的 key 及 windowEnd 作 keyby、聚合
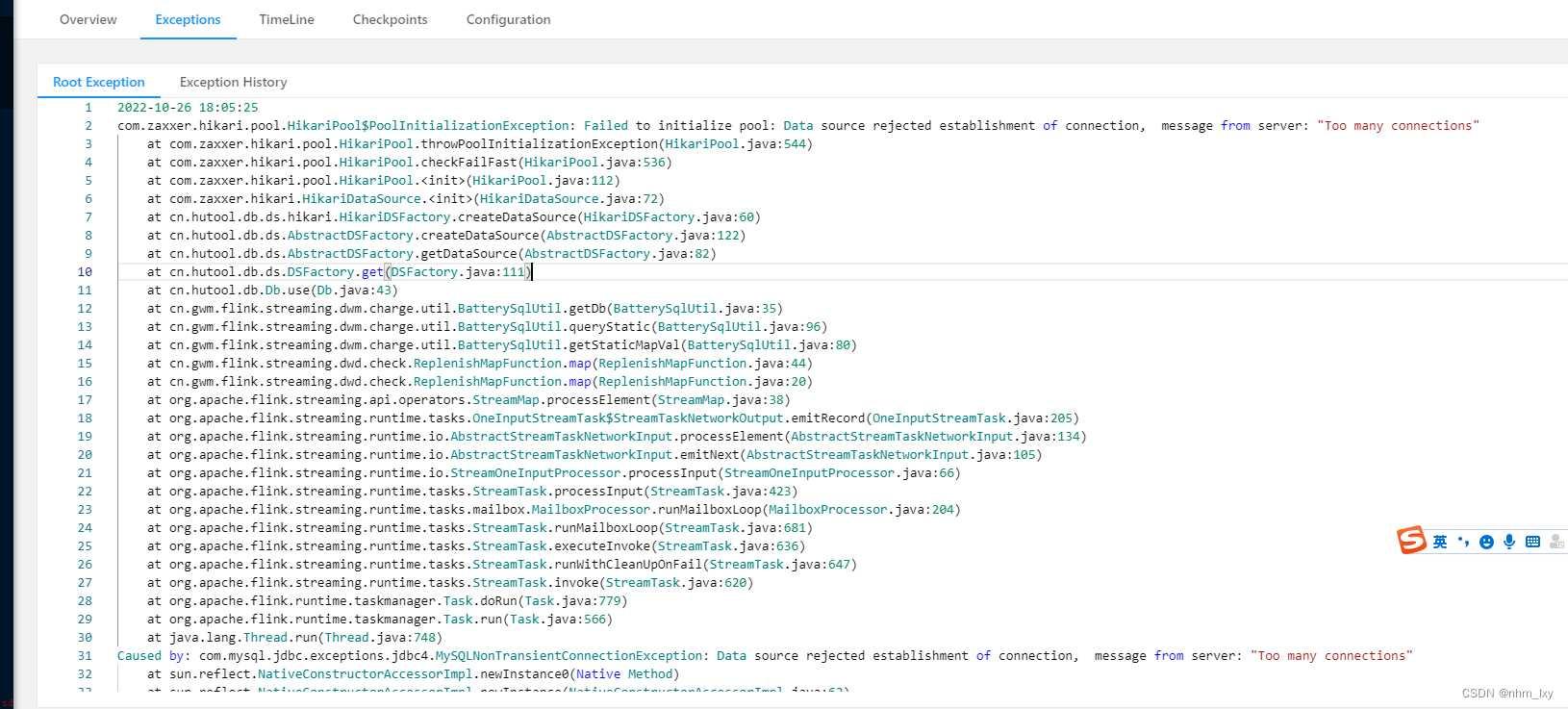
flink任务启动抛出mysql数据库连接过多异常message-from-server:“Too-many-connections“解决办法





