数据加载速度是评判数据库性能的重要指标,能否提高数据加载速度,对文件数据进行并行解析,直接影响数据库运维管理效率。基于此,AntDB分布式数据库提供了两种数据加载方式:
一是类似于PostgreSQL的Copy命令,二是通过AntDB提供的并行加载工具。Copy命令是大家都比较熟悉的,但Copy命令导入数据需要通过CN节点,制约了数据的导入性能,无法实现并行、高效的加载。而AntDB并行加载工具可以绕过CN节点,直连数据节点,大大提高了加载的速率。
并行加载工具有两种线程,一种是文本处理线程,另外一种是数据处理线程。文本处理线程只有1个,用来读取文件,并按行进行拆分,拆分后将行数据发送到数据处理线程。数据处理线程是多个,并行分析行数据,并加载到相应数据节点。

并行加载工具支持Text和Csv两种格式的文件,下面简要说明下。Text和Csv文件都是以纯文本形式存储表格数据的,文件的每一行都是一个数据记录。每个记录由一个或多个字段组成,用分隔符分隔。文本处理线程的任务就是从文件中提取一行完整的记录,然后发送给数据处理线程。
文件中每一行数据以字符’ ’或者’ ’结尾。当是Csv文件是,由于Csv文件支持引用字符,当‘ ’、’ ’出现在引用字符中间时,作为普通字符处理,不能作为行结尾。Csv的引用字符为单字节字符,用户可以根据需要自己指定,未指定的话默认是双引号。
数据处理线程用来分析文本处理线程发来的行数据,行数据由一个或多个字段组成,用分隔符分隔,分隔符可以指定。
数据处理线程从CN获取数据库及表相关信息,包括数据库编码方式,表分片方式,表的分片键等。
AntDB数据库中的表支持以下4中分布方式:
复制表Hash分片表取模分片表随机分片表并行加载工具会根据表的分布方式生成相应的导入策略。以下以不同的表分布方式说明并行加载工具的导入策略。
复制表在每个DN数据节点都保留完整的数据,复制表的数据导入时,需要将行数据插入到所有DN节点。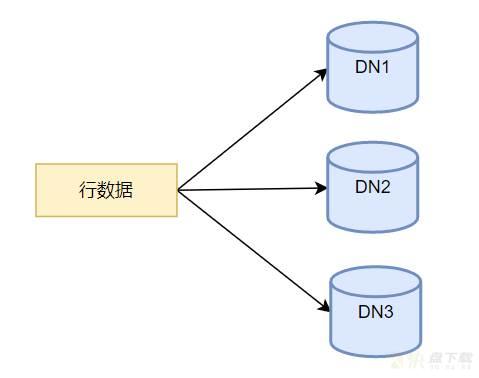


本节对并行加载工具的部分支持的功能进行简要说明。
1.支持表类型
并行加载工具支持普通表、分区表。
2.支持指定导入字段
文件中并不是必须包含表中所有的字段,用户可以指定导入某些字段,但是指定的字段数要和文件中的字段数保持一致。
3.支持导入部分记录
并行加载工具支持指定Where条件,只将符合条件的记录导入到数据库中。
4.自动生成序列字段值
本工具支持自动生成序列字段值,有些表的字段设置了Default值为序列,用户可能需要数据库自己生成,并没有包含在文件中。 当该字段为非分片键时,我们可以使用数据库自有的功能,在插入时自动生成该字段值。但是当该字段为分片键时,我们需要先在加载工具中生成该值,然后根据该值进行分片,插入到对应的DN节点。
5.无分片键文件导入
当文件中不包含分片键,并且没有Default值时,加载工具将该字段置为Null计算并插入相应节点。
6.触发器
当导入的表包含触发器时,并行加载工具并不会做特殊的处理,当触发器涉及非本数据节点时,并行加载工具并不支持。例如一个表的触发器,该触发器会插入另外一张表,但是该表分片与原表不同,此时将会涉及多个数据节点。
7.不支持辅助表
AntDB有辅助表功能,用来优化SQL语句的性能,该表中存放数据表的相应数据。当数据表有辅助表时,并行加载工具只能将文件导入到数据表,并不会修改相应的辅助表。
8.支持编码转换
并行加载工具支持数据编码转换,在文件中数据和数据库的编码不同时,工具会对文件中数据编码的转换之后再插入数据库。
并行加载工具相比Copy命令,有效提升了数据加载的效率。由于表字段的个数、类型及数据的不同,并行加载工具相对Copy命令所提升的倍率并不完全相同。下面以TPCC的数据导入进行性能的对比。
1000仓的数据,需要导入到表Bmsql_Stock的记录有1亿条,数据文件Stock.csv文件的大小为29GB。测试的AntDB集群有2个DN主节点。在此场景的测试中,加载效率提升了7倍左右,加载速度对比图如下所示:

Bmsql_Stock表结构如下:

本文介绍了AntDB并行加载工具的实现方式和使用方法,通过多线程的方式实现并行处理文件数据,并加载到AntDB数据库,有效提升了加载的效率。
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。