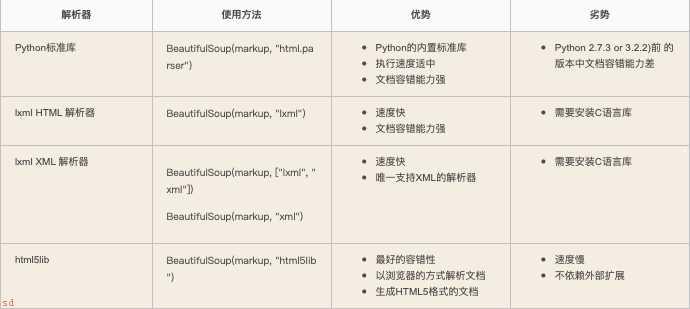
beautiful soup库:解析HTML页面信息标记与提取方法,也叫bs4库
# 2种载入bs4库的方法
from bs4 import BeautifulSoup
import bs4
利用管理员权限,启动cmd命令,运行下列代码
pip install beautifulsoup4
 beautifulsoup4 1.png
beautifulsoup4 1.png
Beautiful Soup小测试
演示HTML页面地址:https://python123.io/ws/demo.html
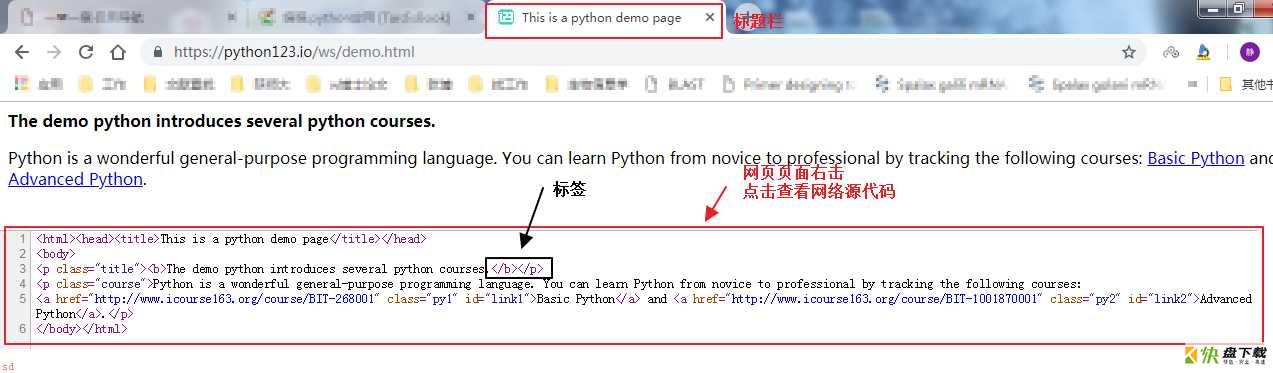 beautifulsoup4安装测试 1.png
beautifulsoup4安装测试 1.png
标题栏:表示的是title信息
源代码:对应的是HTML 5.0格式的代码。Requests库中.text获得的就是网络的源代码
标签:一对尖括号表示(<>······<>)
import requests
r = requests.get('https://python123.io/ws/demo.html')
r.text
# 给源代码命名一个变量
demo = r.text
# 使用bs4库中BeautifulSoup类
from bs4 import BeautifulSoup
# 定义一个变量,接收demo信息通过BeautifulSoup解析后的内容
# 需要给出解析demo的解释器(html.parser)
# 对demo进行html的解析,结果存储到soup中
soup = BeautifulSoup(demo, 'html.parser')
# 打印解析后内容
print(soup.prettify())
HTML文件源代码是由一组标签组成
标签之间存在上下游关系,形成标签树
Beautiful Soup库是解析、遍历、维护标签树的功能库
只要提供的文件类型是标签类型,Beautiful Soup库都能解析
 标签 1.png
标签 1.png
1.2.1 Beautiful Soup类
HTML文档=标签树= Beautiful Soup类
from bs4 import BeautifulSoup
# 解析网页爬取内容
soup = BeautifulSoup(r.text, 'html.parser')
# 解析HTML文档
soup2 = BeautifulSoup(open('文档路径和名称'), 'html.parser')
Beautiful Soup对应一个HTML/XML文档的全部内容
无论哪种解析器,都可以解析HTML和XML文档
1.2.1 Beautiful Soup类基本元素
获得标签
def 爬取网页(url):
'''获得并返回网页内容'''
import requests
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
demo = r.text
return demo
except:
print('爬取失败')
demo = 爬取网页('https://python123.io/ws/demo.html')
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, 'html.parser')
# 查看解析后页面title标签
soup.title # <title>This is a python demo page</title>
# 定义变量,接收解析中a标签的内容
tag_a = soup.a
tag_a # 【获得a标签内容】
当HTML中有多个相同标签,用
soup.<tag>只能获得其第一个tag
如上例中soup.a,只能得到第一个a标签
获得标签名字
def 爬取网页(url):
'''获得并返回网页内容'''
import requests
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
demo = r.text
return demo
except:
print('爬取失败')
def 解析网页(demo):
'''解析爬取网页的内容,并返回解析内容'''
from bs4 import BeautifulSoup
try:
soup = BeautifulSoup(demo, 'html.parser')
return soup
except:
print('解析失败')
demo = 爬取网页('https://python123.io/ws/demo.html')
soup = 解析网页(demo)
# 查看a标签名字
soup.a.name # 'a'
# 查看a标签的父亲标签的名字
soup.a.parent.name # 'p'
# 查看p标签的父亲标签 # 'body'
soup.a.parent.parent.name
使用
.name的方式获得的名字是以字符串形式展现
获得标签属性信息
demo = 爬取网页('https://python123.io/ws/demo.html')
soup = 解析网页(demo)
# 查看a标签属性
attrs_a = soup.a.attrs
attrs_a
# 因为属性是字典,可以以访问键值对的方式,访问属性中的信息
# 获得标签的class属性
attrs['class'] # ['py1']
# 获得标签的连接属性
attrs['href'] # 'http://www.icourse163.org/course/BIT-268001'
# 查看标签属性类型
type(attrs) # dict【表明是字典类型】
获得NavigableString内容
demo = 爬取网页('https://python123.io/ws/demo.html')
soup = 解析网页(demo)
string_a = soup.a.string
string_a # 'Basic Python'
Comment属性
newsoup = BeautifulSoup('<b><!--This is a comment--></b><p>This is not a coment</p>', 'html.parser')
newsoup.b.string # 'This is a comment'
# 查看类型
type(newsoup.b.string) # bs4.element.Comment
newsoup.p.string # 'This is not a coment'
# 查看类型
type(newsoup.p.string) # bs4.element.NavigableString
1.3 遍历HTML方法上例中
<!表示一个注释的开始
但是在显示NavigableString内容时,并没有标识是否是文本还是注释。即<!被去掉了
在分析文档时,对注释判断的依据是类型
 遍历HTML 1.png
遍历HTML 1.png
1.3.1 标签树的下行遍历
.contents
获得子节点的列表,将<tag>所有儿子结点存入列表
.chilren
子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
.descendants
子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
demo = 爬取网页('https://python123.io/ws/demo.html')
soup = 解析网页(demo)
# 查看body的儿子节点
soup.body.contents
len(soup.body.contents) # 5
soup.body.contents[1] # <p class="title"><b>The demo python introduces several python courses.</b></p>
# 遍历儿子节点
for child in soup.body.children:
print(child)
# 遍历子孙节点
for child in soup.body.descendants:
print(child)
.contents得到的是列表类型,则可以用列表方式操作其内容
.chilren、.descendants得到的是迭代类型,只能用在for循环的语句中
1.3.1 标签树的上行遍历
.parent
获得节点父亲标签
.cparents
节点先辈标签的迭代类型,用于循环遍历先辈节点
# 查看html标签父亲【html是文本的最高级标签,所以它的父亲就是它自己】
soup.html.parent
# soup本身的父亲标签【没有输出,说明soup的父亲是空】
soup.parent
# 对a标签进行,标签树的上行遍历
for parent in soup.a.parents:
if parent == None:
print(parent)
else:
print(parent.name) # p body html [document]
在遍历标签的所有先辈标签时,会遍历到soup本身,而soup的先辈并不存在
.name的信息
1.3.1 标签树的平行遍历
平行遍历发生在同一个父亲节点下的各个节点
.next_sibling
返回按照HTML文本顺序的下一个平行节点标签
.previous_sibling
返回按照HTML文本顺序的上一个平行节点标签
.next_siblings
迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings
迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
# a标签的平行节点
soup.a.next_sibling # 'and'【字符串形式】
# a标签的下下一个节点
soup.a.next_sibling.next_sibling
# a标签的上一个平行标签
soup.a.previous_sibling
# 遍历平行后续节点
for sibling in soup.a.next_siblings:
print(sibling)
# 遍历平行前续节点
for sibling in soup.a.previous_siblings:
print(sibling)
1.4 HTML格式输出标签树中,NavigableString也可以构成节点
即一个标签的儿子标签和平行标签时可能存在NavigableString类型
让HTML页面更加友好的显示
demo = 爬取网页('https://python123.io/ws/demo.html')
soup = 解析网页(demo)
# 直接显示解析内容
soup.prettify()
print(soup.prettify)
print(soup.a.prettify)
.prettify方法,能够为HTLM文本增加换行符
bs4库将任何读入的HTML文件或字符串,都转换成utf-8编码
Python3默认的编码是utf-8
1.5 单元小结utf-8编码是一种估计通用的编码格式
如果使用Python2,在编码中就需要转换
def 解析网页(demo):
'''解析爬取网页的内容,并返回解析内容'''
from bs4 import BeautifulSoup
try:
soup = BeautifulSoup(demo, 'html.parser')
return soup
except:
print('解析失败')
bs4库基本元素:Tag、name、Attributes、NavigableString、Comment
bs4库的遍历功能:.contents 、 .chilren 、.descendants、.parent 、.cparents、.next_sibling 、.previous_sibling、.next_siblings、.previous_siblings
HTML是WWW的信息组织形式,能够将声音、图像、视频等超文本信息嵌入到文本中。通过标签形式组织不同类型的信息
信息标记的3种形式:XML、JSON、YAML
2.1.1 XML
<name> ···</name>、<name />、(注释)
最早的通用信息标记语言,扩展性好,但是繁琐
主要用于Internet上的信息交互与传递
<person>
<firstName>Z</firstName>
<lastNmae>J</lastNmae>
<address>
<streetAddr>麻阳···</streetAddr>
<city>怀化</city>
<zipcode>100081</zipcode>
</address>
<prof>Computer System</prof><prof>Security</prof>
</person>
2.1.2 JSON
有类型的键值对,'信息类型' : '信息值'。'key' : 'value'、'key' : ['value1', 'value2']、'key' : {'subkey' : 'subvalue'}
信息有类型,适合程序处理,较XML简洁
主要用于移动云端和节点的信息通讯,无注释
{
'firstName' : 'Z',
'lastName' : 'J',
'address' : {
'streetAddr' : '麻阳',
'city' : '怀化',
'zipcode' : '100081'
},
'prof' : ['Computer System', 'Security']
}
2.1.3 YAML
无类型键值对,key : value。通过缩进表达所属关系,用-表达并列关系,用|表达整块数据(#表示注释)
信息无类型,文本信息比例高,可读性好
主要用于各种系统的配置文件,有注释
firstName : Z
lastName : J
address' :
streetAddr : 麻阳
city : 怀化
zipcode : 100081
prof :
-Computer System
-Security
从信息标记后,提取所关注的内容
形式解析:完整解析信息的标记形式,再提取关键信息。如用解析器解析XML、JSON、YAML(bs4库的标签树遍历)
优点:信息解析准确
确定:提取过程繁琐,速度慢
搜索查找:无视标记形式,直接搜索关键信息。需要对文本进行查找
优点:简洁、快速
缺点:提取结果准确性与信息内容相关
一般用融合方法:结合形式解析与搜索方法提取信息
2.3find_all()
find_all(name, attrs, recursive, string, **kwargs)
是基于bs4库的查找HTML内容的方法,一种普片的信息提取方法。可以在解析内容中查找里面的信息,返回一个列表类型,储存查找的结果。提供了5个参数
2.3.1 name:对标签名称的检索字符串
demo = 爬取网页('https://python123.io/ws/demo.html')
soup = 解析网页(demo)
# 查找a标签
for link in soup.find_all('a'):
# 获取href属性
print(link.get('href'))
# 查找所有标签
for tag in soup.find_all(True):
# 获得所有标签的名字
print(tag.name) # 【会显示HTML的所有标签名字】
如果需要打印所有以b开头的标签,如b标签、body标签等。则需要引入正则表达式库
正则表达式库所反馈的结果是以指定目标为开头的信息,作为查找的要素
# 引入正则表达式库
import re
# 用re.compile('b')给到find_all参数,表示查找所有以b开头的标签
for tag in soup.find_all(re.compile('b')):
print(tag.name)
2.3.2 attrs:对标签属性值的检索字符串,可标注属性检索
# 查找p属性中,有course属性的标签
soup.find_all('p', 'course')
# 对属性做相关约定,查找id属性是link1的标签
soup.find_all(id = 'link1')
# 查找id属性是link的标签
soup.find_all(id = 'link') # 【发现结果是空】
对属性进行赋值查找的时候,需要精确赋值信息
如果信息不全,则需要引入正则表达式库
import re
# 查找id属性以link开头的所有标签
soup.find_all(id = re.compile('link'))
2.3.3 recursive:是否对子孙全部检索,默认True
soup.find_all('a') # 【有内容】
soup.find_all('a', recursive=False) # 【空内容,说明从soup跟节点开始,儿子节点是没有a标签】
2.3.4 string:<>···</>中字符串区域的检索
# 所有HTML内容
soup
# 检索其中的一个字符串
soup.find_all(string = 'This is a python demo page')
需要精确输入字符串的所有内容
如果信息不全,则需要引入正则表达式库
import re
# 查找在字符串中出现'is'的标签
soup.find_all(string = re.compile('is'))
# 由于`find_all()`方法在bs4中非常常见,可以省略find_all(如下)
soup(string = re.compile('is'))
2.3.5 find_all()扩展方法
.find()
搜索且只返回一个结果,字符串类型
find_parents()
在先辈节点中搜索,返回列表类型
find_parent()
在先辈节点中返回一个结果,字符串类型
find_next_siblings()
在后续平衡节点中搜索,返回列表类型
find_next_sibling()
在后续平行节点中返回一个结果,字符串类型
find_previous_siblings()
在前续平衡节点中搜索,返回列表类型
find_previous_sibling()
在前续平行节点中返回一个结果,字符串类型
所有扩展方法的参数跟find_all一样,区别在于检索区域不同
信息标记的3种形式:XML(<>···</>)、JSON(有类型的键值对)、YAML(无类型的键值对)
信息提取的一般方法:find_all(name, attrs, recursive, string, **kwargs)
实例网址:http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html
目的:通过输入网页链接,输出大学排名信息(名称、名次、总分)
技术路线:requests-bs4
定向爬虫:仅对输入的url进行爬取,不扩展
确定定向爬虫可行性:所需信息是否写在HTML页面的代码中(有些数据可能通过Java等脚本语言生成的(动态的))
网页查询源代码,查找某一信息对应的代码部分,如下图,这段代码是使用tr标签来索引的一段信息,从这段信息中可知,所需要的信息都写在HTML页面信息中
 大学排名 1.png
大学排名 1.png
因为只有1个页面,手动查看网站的robots 协议:http://www.zuihaodaxue.com/robots.txt
如下图,说明网站并没有对爬虫做相关限制
 大学排名 2.png
3.1 程序结构设计
从网络上获取大学排名网页内容
提取网页内容中的信息,到合适的数据结构(二维列表)中
利用数据结构展示并输出结果
大学排名 2.png
3.1 程序结构设计
从网络上获取大学排名网页内容
提取网页内容中的信息,到合适的数据结构(二维列表)中
利用数据结构展示并输出结果
步骤一:书写程序结构
import requestse
from bs4 import BeautifulSoup
def getHTMLText(url):
'''
输入:获取的url信息
输出:url的内容
'''
return ''
def fillUnivList(html):
'''将一个HTML页面放到列表中'''
pass
def printUnivList(ulist, num):
'''
将列表信息打印出来
num:表示需要打印多少个
'''
print('Suc' + str(num))
虽然上面3个函数的内容不定,但是需要对3个函数的接口有清晰的定义
步骤二:主程序
def main():
url = 'http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html'
# 调用函数,将url转换成html
html = getHTMLText(url)
# 信息提取后,将html放在uinfo的变量中
uinfo = fillUnivList(html)
# 打印前20个排名的大学信息
printUnivList(uinfo, 20)
main()
步骤三:添加函数内容,使得整个程序可以运行
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
'''
输入:获取的url信息
输出:url的内容
'''
try:
# 设定timeout是30s
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
demo = r.text
return demo
except:
print('爬取失败')
def fillUnivList(html):
''' 将一个HTML页面放到列表中'''
try:
soup = BeautifulSoup(html, 'html.parser')
# 观察源代码,查找所有tbody标签,并对其儿子标签进行遍历
ulist = []
for tr in soup.find('tbody').children:
# 判断儿子标签类型,过滤掉非bs4.element.Tag类型(使用这个需要引入bs4)
if isinstance(tr, bs4.element.Tag):
# 将tr标签中的td标签赋值为tds
tds = tr('td')
# 定义ulist列表,并添加所需要的内容
ulist.append([tds[0].string, tds[1].string, tds[3].string])
except:
print('解析返回列表失败')
else:
return ulist
def printUnivList(ulist, num):
'''
将列表信息打印出来
num:表示需要打印多少个
'''
# 对表头的打印
print('{:^10} {:^6} {:^10}'.format('排名', '大学', '分数'))
for i in range(num):
u = ulist[i]
print('{:^10} {:^6} {:^10}'.format(u[0], u[1], u[2]))
def main():
url = 'http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html'
html = getHTMLText(url)
uinfo = fillUnivList(html)
printUnivList(uinfo, 20)
main()
观察源代码发现
所有大学信息被封装在tbody标签中,每一个大学的信息被封装在tr标签中,tr标签的每个信息又被td标签所包围
排名 大学 分数
1 清华大学(北京) 100
2 北京大学 80.5
3 香港中文大学 71.0
4 浙江大学 66.1
5 香港大学 62.0
6 中国科学技术大学 61.4
7 上海交通大学 58.9
8 复旦大学 56.8
9 清华大学(新竹) 56.5
10 台湾大学 54.8
11 北京师范大学 53.9
12 香港城市大学 50.1
13 香港科技大学 49.8
14 南京大学 46.9
15 华中科技大学 44.3
16 中山大学(广州) 43.9
17 香港理工大学 43.5
18 交通大学(新竹) 42.5
19 哈尔滨工业大学 42.0
20 澳门科技大学 41.9
:,<左对;>右对齐;^居中对齐
槽的设定输出宽度
数字的千位分隔符,适用于整数和浮点数
浮点数小数部分的精度或字符串的最大输出长度
整数类型b,c,d,o,x,X浮点数类型e,E,f,%
当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同
可以采用中文字符的空格填充chr(12288),解决中文对齐问题
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
'''
输入:获取的url信息
输出:url的内容
'''
try:
# 设定timeout是30s
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
demo = r.text
return demo
except:
print('爬取失败')
def fillUnivList(html):
''' 将一个HTML页面放到列表中'''
try:
soup = BeautifulSoup(html, 'html.parser')
ulist = []
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
except:
print('解析返回列表失败')
else:
return ulist
def printUnivList(ulist, num):
'''
将ulist的信息打印出来
num:表示需要打印多少个
'''
# 定义一个输出模板的变量
# 将变量的输出按顺序表示,增加学校的宽度
# {3}表示需要填充时,使用format函数的第3个变量进行填充,即中文空格填充
tplt = '{0:^10} {1:{3}^10} {2:^10}'
# 增加中文空格的变量位置
print(tplt.format('排名', '大学', '分数', chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
def main():
url = 'http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html'
html = getHTMLText(url)
uinfo = fillUnivList(html)
printUnivList(uinfo, 20)
main() # 【打印结果对齐】
目录
Python网络爬虫与信息提取
一、Requests库
二、Beautiful Soup库
三、Re库
四、Scrapy框架
汇总
 python网络爬虫与信息提取.jpg
python网络爬虫与信息提取.jpg