在一个数据为王时代,数据安全视为一家企业命根子,因此如何保障企业数据安全尤为重要。本文主要从数据库容灾方案视角,基于当前客户业务并结合技术&产品,制定最佳容灾方案。主要从以下三个方面来介绍:
方案设计要素云上容灾方案云上客户案例数据库容灾方案设计要素主要数据同步,数据一致性以及数据修复三个方面 。
数据同步主要指两个可用区或者不同地域之间的数据同步,主要分为单向同步和双向同步。
同步方式 | 复制原理 | 具体场景 | 优势 | 劣势 |
|---|---|---|---|---|
单向同步 | 采用主从复制方式 | 上层业务单写模式 | 1.数据一致性挑战低 2.业务改动较小 | 业务延时依赖较强 |
双向同步 | 采用主主双向复制方式 | 上层业务单写或者双写模式 | 业务延时依赖较弱 | 1.数据一致性挑战高 2.业务改动较大 |
针对双向同步的业务单写场景进行说明:
业务流量单个游戏服务在单个地域承载,如下图通常情况下,红色框的业务不承载流量,而是作为业务紧急逃生通道;同时数据库读写均在同一地域,不同地域之间进行主主双向同步。
——数据库容灾建设")
数据一致性,主要指上层业务在读库时候,数据库集群主从库存储的数据保持一致。如果数据库集群不同库数据不一致,业务就会读到脏数据。举个例子,银行余额数据库存在数据不一致情况,某天当白领小王刚发工资,同时收到短信通知余额3万元,但是当小王登录银行APP查询发现余额仅有2000元,由于新增余额没有及时同步到所有主从库,导致数据不一致;试想一下这种情况,银行需要多少客服人员来支持呢?
1. 单写业务场景
单写业务场景,说明业务只有一套数据库系统,因此一致性保障依赖于数据库集群内主从库复制方式,包括异步,半同步,以及强同步。正常来讲,一般业务采用数据最终一致性,折中选择半同步复制方式居多。
复制方式 | 技术原理 | 一致性 | 性能 |
|---|---|---|---|
异步复制 | 应用发起更新请求,主节点完成相应操作后立即响应应用,主节点向从节点异步复制数据。 | 弱 | 强 |
半同步复制 | 应用发起更新请求,主节点在执行完更新操作后立即向 从节点 复制数据,从节点接收到数据并写到 relay log 中(无需执行) 后才向主节点返回成功信息,主节点必须在接受到从的成功信息后再向应用程序返回响应。 | 中 | 中 |
强同步 | 应用发起更新请求,主节点完成操作后向从节点复制数据,从节点接收到数据后向 主节点返回成功信息,主节点接到从的反馈后再应答给应用。Master 向 Slave 复制数据是同步进行的 | 强 | 弱 |
2.针对双写业务场景
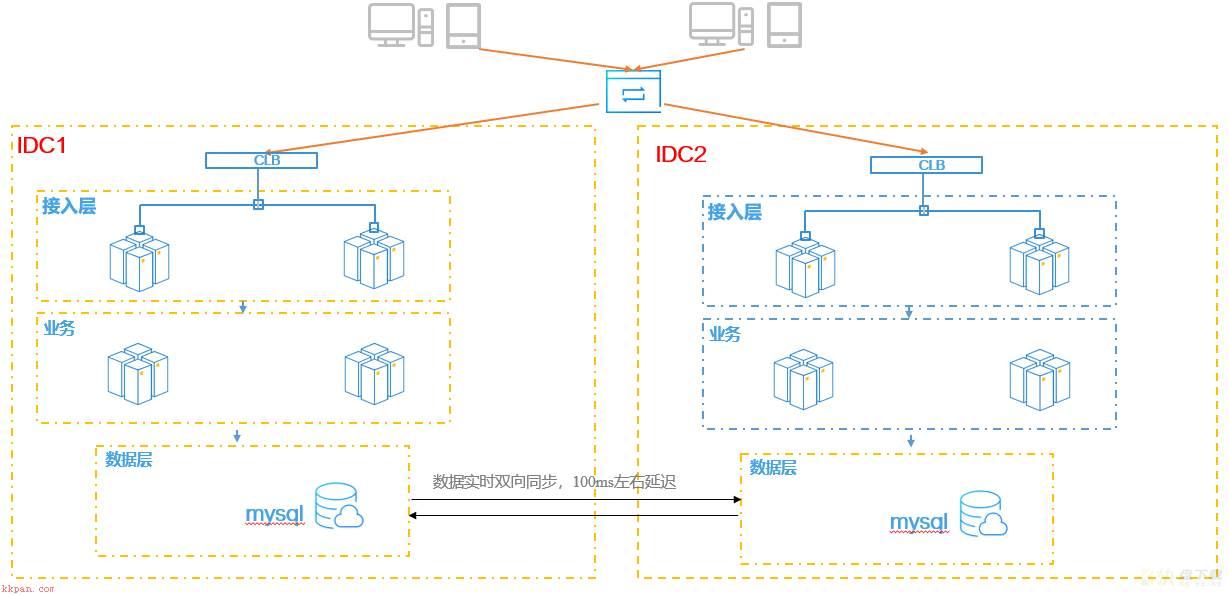
业务双写,说明业务系统有两套数据库集群,数据一致性保障一方面是集群内数据复制方式,另一方面两个集群间数据复制方式。双写数据一致性保障主要还是依赖于业务层。如下图是业内主流数据库双写方案,
1)根据用户信息划分不同IDC机房,通过API网关把不同用户转发到不同的IDC集群
2)数据库mysql数据已做单元化拆分,双入口可写,但是同一个用户数据仅在一个入口访问,来保障读数据一致性。
3)如果数据发生冲突,系统可以通过时间戳顺序覆盖旧数据。
数据库集群发生故障中断后,如何来保障数据一致性。
1)中断场景感知和切换
一般通过仲裁中心探测,在探测周期内,发现主节点异常,进行VIP的切换。MHA作为业内较为成熟的数据库高可用故障解决方案;而腾讯云采用ZK方式去感知切换,经过测试准备切换大约30s完成。
2)中断场景一致性保障
基于1.2章节描述保障数据一致性外,主要还是依赖实际业务场景来进行加固。通常来讲,对数据不是很敏感业务,主从切换不需要对比数据一致性的。如果有业务对数据一致性要求较为敏感,一般都有内部全量校对工具来校验,如果发现不一致,通过既定原则按照时间戳方式来覆盖自动修复,或者通过本地日志来分析人工处理来保障数据安全。
客户业务场景最常用腾讯云数据产品主要是redis,cdb,mongoDB以及TDSQL。
数据产品 | 跨区容灾 | 就近访问 | 跨地容灾 |
|---|---|---|---|
CDB | 支持 控制台自助配置 | 支持 跨AZ/跨地域RO实例 | 方案一:通过DTS支持,需要业务手工切换VIP 方案二:支持DTS双写能力,云上云下或多地域。 |
redis | 支持 控制台自助配置 | 支持 跨AZ/地域副本 | 方案一:通过DTS复制支持 方案二:通过DTS支持全球复制能力,多地就近读取 |
TDSQL | 支持 控制台自助配置 | 支持读写自动分离 跨AZ/跨地域 | 通过DCN复制来支持 |
MongoDB | 支持 控制台自助配置 | 支持 跨AZ副本 | 通过DTS复制支持 |
目前云上某家金融公司,使用云上TDSQL产品,数据库存放数据是订单业务,需要将当前单可用能力升级为多可用区能力。同时升级为多可用区能力,会引入以下风险因子
业务时延会有3ms左右网络延时,tdsql在proxy到db无就近原则极端情况下主从一致性问题概率变大跨可用区网络抖动会导写业务hang住同地域不同AZ会存在3ms网络延时,实现容灾建议这里性能进行取舍,对于2和3的诉求点,结合tdsql产品提供容灾建议。
基于当前tdsql核心数据库采用单可用区一主两从架构,数据复制方式为强同步,主要有三种方案,综合考虑采用方案三:
其中TDSQL强同步说明:https://cloud.tencent.com/document/product/557/10570
方案 | 方案详情 | 优势 | 劣势 |
|---|---|---|---|
方案一 | 双可用区部署:一个可用区一主一从,另一可用区一从 | 1.业务延时:业务延时受跨可用区延时影响较小,与同可用区延时几乎无差别,从强同步理论上多数ACK均由Slave1返回给Master节点。 2.写数据hang住:与同可用区业务场景一致。 | 1. 数据一致性:数据一致性较差,强同步均依赖于Slave1,对于slave2数据可能不是最新数据,可用区故障可能会存在数据不一致的情况 2. 读脏数据:AZ1和AZ2跨可用区之间网络异常,当ZK在判断剔除slave2期间(20s),只读业务有在slave2概率会读过期脏数据的情况(对延迟敏感业务,本身也不建议读取从节点数据) |
方案二 | 双可用区部署:一个可用区一主,另外一可用区两从 | 1. 数据一致性:master可用区故障,根据强同步规则,保证数据最终一致性。 2. 读脏数据:理论上两台slave返回ack时间差别较小,因此跨可用区之间网络异常,在两个slave节点读取脏数据可能性非常低。 | 1. 业务延时:跨AZ会有3ms网络延时,业务结合具体事务综合来评估。 2. 写数据hang住:逻辑链路跨可用区只有一条,依赖于可用区之间链路稳定性,会增加写数据hang住概率。 |
方案三 | 三可用区部署:三个可用区,每个可用区一个节点 | 1. 数据一致性:master可用区故障,根据强同步规则,保证数据最终一致性。 2. 读脏数据:理论上两台slave返回ack时间差别较小,因此跨可用区之间网络异常,在两个slave节点读取脏数据可能性非常低。 3. 写数据hang住:逻辑链路跨可用区有两条,增强跨AZ网络稳定性,会降低写数据hang住概率 | 跨AZ会有3ms网络延时,业务结合具体事务综合来评估 |


Navicat for MySQL怎么连接数据库?- Navicat for MySQL连接数据库教程攻略