这是很早时候写的一篇文章,今天翻看历史文章的时候发现的,觉得还是有收获,就分享出来了。以下是文章原文:
问题背景
前几天的一个晚上,要下班的时候,业务方忽然有一个需求,是需要恢复一个表里面的数据。
问了下误删除的具体情况,大概是这样的:业务方不小心在一个表里面做了一个update的操作,where条件没有写对,导致表里面的数据被写脏了,现在要求恢复到之前的数据。
听到这里,我先检查了下当前这个实例的备份,万幸,备份是存在的。这份数据是平台上某些商品的价格,基本上是有限个商品,然后价格值也都是固定的,之前有对这个价格表进行备份,于是给他直接重新导入了一份价格表的数据,这个问题也算是解决了。
数据恢复的思考
本次数据恢复,由于提前备份了这个价格表,所以直接导入就可以了,那么,如果没有备份价格表呢?或者说这个价格表是个动态变化的表,又该如何快速处理呢?现在想起来,其实有一些其他办法。
方法一:DML闪回
由于是DML的误操作,使用binlog2sql工具或者flashBack工具,能够很好的解决这个问题。
方法二:传统方法(备份+binlog回放)
如果我们使用传统的备份+binlog回放的方法,确实在处理速度上不占优势,尤其是备份文件的时间比较久远的场景下,这种方法会花费大量时间。想要加速这个过程,可以通过调整buffer pool以及刷盘策略等参数。但是,这种方法终究还是逃脱不了binlog单线程回放的陷阱。
使用mysqlbinlog工具重放事务,这种方法会有一些陷阱:
1、只能每次运行一个mysqlbinlog命令,一次对一个binlog文件执行重放,无法并行多命令运行,因为在执行重放的时候会产生一个临时表,会有冲突,造成失败。
2、它是一个原子操作。如果它在运行到半途中间的时候失败,将很难知道它在哪失败,也很难基于先前的时间点重新开始。导致失败的理由会有很多:一些并发事务引起的Innodb lock wait timeout ,server和client设置的max_allowed_packet不同,以及查询过程中失去跟mysql server的连接,等等。
方法三:空间换时间,加速binlog回放
由于回放binlog有一些限制,于是翻了翻Percona的博客,找到一种方法,看了看精髓,就大概记录了下来,大体思路如下:
1、准备2台额外机器,这里简称A、B,A服务器用做备份数据的恢复,B服务器用于将原主的binlog拷贝至该服务器
2、在B服务器启动空实例,然后用原主库的binlog替换自动生成的binlog,模拟原主
3、然后服务器A与服务器B建立主从关系,A服务器是从库,B服务器是主库,修改B服务器的Server-id和原主库一致,然后在A服务器上change master to B服务器,位置点位从备份文件中取,分别取xtrabackup_binlog_info中的binlog和binlog pos
4、start slave开启主从复制,然后同步至误操作点停止,这里可以利用到MySQL的并行复制,binlog的应用就会有加速效果
5、将恢复的表,导出,然后恢复至生产原主。
附录:
Percona官网上给的具体的步骤翻译过来如下:
1、准备一台机器,用于将该实例的最新备份的结果数据,进行备份还原
2、准备另外一台机器了,新实例,将原master的binlog文件,拷贝至该实例的数据目录下, 启动一个空实例(server-id跟原主一致, --log_bin=master-bin binlog文件名保持跟原主一致;),然后停掉它,删除所有它自动创建的binlogs,解压缩并拷贝所有需要的binlogs(来自于原生产实例)到它的数据目录下,然后重新启动它。
最新备份数据的位置:

如果启动正常,则连接mysql,查看binlog相关信息:
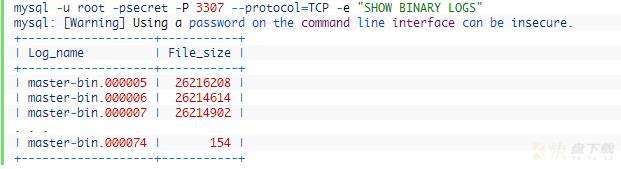
3、建立同步关系,并同步到误操作动作的位置前停止
CHANGE MASTER TO MASTER_HOST='127.0.0.1', MASTER_PORT=3307, MASTER_USER='root', MASTER_PASSWORD='secret', MASTER_LOG_FILE='master-bin.000007', MASTER_LOG_POS=1518932; START SLAVE UNTIL MASTER_LOG_FILE = 'log_name', MASTER_LOG_POS = log_pos 或者 START SLAVE SQL_THREAD UNTIL SQL_AFTER_GTIDS =3E11FA47-71CA-11E1-9E33-C80AA9429562:11-56 SHOW SLAVE STATUSG;
总结:
整个过程中,相当于多用了2台服务器(其实这个可以缩减成1台),提高二进制日志的应用速率,提高二进制日志的应用的成功率。
按照文章中作者讲述的思想来看,是比单实例应用binlog的方法好,因为一旦发生了应用binlog过程中的错误,它能够快速确定是在那个点位发生的错误,有助于我们快速解决问题。
具体操作没有实践,有兴趣的同学可以实践一下
















