今天在线上遇到了一个TiDB服务器宕机的问题。这里总结下。
01
场景描述
TiDB集群中,某一台服务器宕机,这台服务器上部署的集群组件有PD、TiKV、TiDB。
宕机之后,服务器SSH不通了,其他机器无法登陆上去。我们使用下面的命令:
tiup cluster display cluster_name
查看拓扑的时候,发现拓扑中的Status一栏中显示Down,如下:

其实这种情况下,由于节点不可达,所以:
对于TiKV来说,会将这个节点上的Region Leader重新选举,而那些不是Leader的Region只是会少一个副本,影响相对较小;
对于TiDB来说,由于它是无状态的,业务可以通过其他的TiDB组件访问集群,没有什么影响;
对于PD来说,PD本身具有高可用,如果挂掉的机器是PD的Leader,那么会自动发生选举,如果不是Leader,那么对PD的影响也比较小,只是少了一个副本;
通常情况下,我们会使用prune命令来驱逐这些下线的节点,而在这种情况下,当我们使用:
tiup cluster prune cluster_name 命令
驱逐这个节点的时候,发现执行过后,这个Down的状态,还是没有消失。
此时查看TiDB的Dashboard,发现这个标记为Down状态的节点,不在TiDB的Dashboard中,如下:
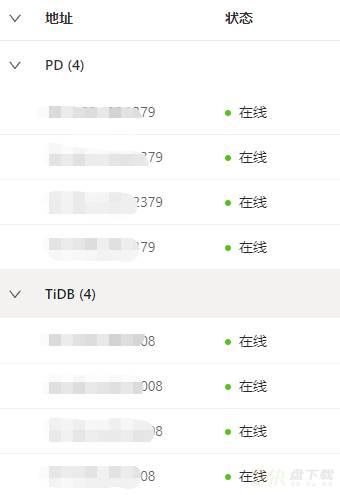
那么到底如何去掉display命令中这个Down的状态呢?
02
服务器宕机处理方法
正确的姿势是应该先使用scale-in来缩容这个TiDB节点。
你可能会说服务器都宕机了,SSH肯定不通了,缩容不会报错吗?答案确实是会报错,而且会提示我们这个节点已经无法通过SSH连接,集群无法直接摘掉了。
正确的处理方法如下:
这种情况下,需要借助scale-in操作里面的--force参数来将这个节点强制下线,因为节点宕机之后已经无法修复了。命令如下:
tiup cluster scale-in cluster_name --node xxxx --force
下线的时候,会提示如下:

我们需要按照提示,输入图中蓝色字体部分:
Yes,I know my data might be lost.
否则无法执行--force操作。
针对这个服务器,分别执行完TiKV、TiDB、PD的scale-in操作之后,可以发现再次使用display命令查看,标志Down 状态的节点就彻底下掉了。