微信公众号:DBA随笔
今天早晨遇到一个redis的线上的问题,也算是一个Redis的经典问题了,这里记录下分析和排查过程,希望对大家有所帮助。
问题背景:
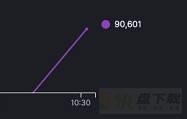
业务侧反馈服务有超时,10:30分左右出现了大量的IO timeout的报警

业务的监控图脱敏后如下,纵坐标是延时的请求次数,可以看到,10:30分左右,突然飙升很多。
报警信息中详细定位了报警的Redis端口和域名,可以确定到某一台服务器的IP地址上,那其实只要对这个特定的IP地址进行分析就好了。
首先先查看对应的连接数,发现10:32分的时候,确实有连接数上升的问题:

再次查看Redis日志中发现有大量重复的告警内容:
24:S 16 Aug 10:32:03.357 * Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis. 24:S 16 Aug 10:32:05.067 * Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis. 24:S 16 Aug 10:32:39.058 * Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis. 24:S 16 Aug 10:33:13.067 * Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis. 24:S 16 Aug 10:33:47.064 * Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis. 24:S 16 Aug 10:34:21.099 * Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.
日志的告警时间在大概10:32分左右,时间点也基本能够对得上。
翻译一下上面的报警日志:似乎是异步AOF的fsync刷盘动作花费了太长的时间,导致Redis直接将AOF文件写入到AOF buffer中,而不再等候fsync的返回,这个动作可能影响Redis的性能。
那既然是AOF写入磁盘时候的问题,那我们先来看看磁盘的使用情况吧:

可以看到,在10:32分左右,磁盘的util值已经达到了100%了。而且注意到这台服务器的磁盘类型是HDD,本身性能就不好,在加沙灰姑娘高负荷的写入,必定对Redis的性能产生影响。
到这里,其实我们已经可以给出一种解决方案了,那就是使用SSD来代替传统的HDD。但是这种方案不是一下子就能实现的,需要有一个成本评估之类的过程。
Redis相比mysql好的一点就是它的源码量少,完全可以通过源码来查看一个问题,今天我也尝试着从源码层面分析了一次:
打开IDE,全局搜索上述日志关键字,一下子就定位到了下面的函数,(代码很长,不想看可以直接看结论):
-----------函数注释-----------
/* Write the append only file buffer on disk.
*
* Since we are required to write the AOF before replying to the client,
* and the only way the client socket can get a write is entering when the
* the event loop, we accumulate all the AOF writes in a memory
* buffer and write it on disk using this function just before entering
* the event loop again.
*
函数的作用是:将AOF buffer的内容刷到磁盘上,一般情况下在回复客户端响应之前需要将AOF写入,
业务在事件循环结束的时候才能收到已经写入数据的反馈,我们把所有的AOF写入在一个内存buffer中,
然后使用这个函数将它写入磁盘,然后开始进入下一个时间循环
* About the 'force' argument:
*
* When the fsync policy is set to 'everysec' we may delay the flush if there
* is still an fsync() going on in the background thread, since for instance
* on Linux write(2) will be blocked by the background fsync anyway.
* When this happens we remember that there is some aof buffer to be
* flushed ASAP, and will try to do that in the serverCron() function.
*
* However if force is set to 1 we'll write regardless of the background
* fsync. */
---------------函数--------------
#define AOF_WRITE_LOG_ERROR_RATE 30 /* Seconds between errors logging. */
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
if (sdslen(server.aof_buf) == 0) return;
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = bioPendingJobsOfType(BIO_AOF_FSYNC) != 0;
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
/* With this append fsync policy we do background fsyncing.
* If the fsync is still in progress we can try to delay
* the write for a couple of seconds. */
if (sync_in_progress) {
if (server.aof_flush_postponed_start == 0) {
/* No previous write postponing, remember that we are
* postponing the flush and return. */
* 前面没有推迟过 write 操作,这里将推迟写操作的时间记录下来
* 然后就返回,不执行 write 或者 fsync
server.aof_flush_postponed_start = server.unixtime;
return;
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
/* We were already waiting for fsync to finish, but for less
* than two seconds this is still ok. Postpone again. */
* 如果之前已经因为 fsync 而推迟了 write 操作
* 但是推迟的时间不超过 2 秒,那么直接返回
* 不执行 write 或者 fsync
return;
}
/* Otherwise fall trough, and go write since we can't wait
* over two seconds. */
* 如果后台还有 fsync 在执行,并且 write 已经推迟 >= 2 秒
* 那么执行写操作(write 将被阻塞)
server.aof_delayed_fsync++;
serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
从代码中分析得知,当Redis后台有fsync操作,并且等待超过了2s,就会阻塞write操作,此时Redis是不可写入的,就会打印出这条log日志,触发业务超时。
下面的情况可能会导致Redis的fsync阻塞2s:
1、如果开启了appendfsync everysec的fsync策略,并且no-appendfsync-on-rewrite参数为no,则redis在做AOF重写的时候,也会每秒将命令fsync到磁盘上,而此时Redis的写入量大而磁盘性能较差,fsync的等待就会严重;
2、单纯的写入量大,大到磁盘无法支撑这个写入。例如appendfsync参数的值是everysec,每秒进行一次fsync,而磁盘的性能很差。
那其实我们的例子,经过排查发现,仅仅是第二种情况,在10:32分左右,业务的量翻倍了,导致了fsync写满了磁盘的util,导致业务超时。
为什么超过2s,Redis就会阻塞写入?
从上述代码的注释中,注意到有一句: .
这里就需要了解下Linux write(2)数据写缓存机制对Redis的影响,Redis采用IO多路复用,将网络请求转换成一个个事件,每个事件结束的时候,调用linux write(2)机制将数据写入到操作系统内核的buffer,如果这个时候write(2)被阻塞,Redis就不能执行下一个事件。

Linux中规定,当一个文件执行write(2)时候,如果对同一个文件正在执行fdatasync(2), write(2)就会被阻塞住。.如果Redis正在进行AOF重写或者RDB快照制作,由于要写入临时文件,则很有可能导致上述fdatasync(2)超时, write(2)就会被阻塞住,那么整个Redis也会被阻塞住。
针对这种情况,Redis中指定了一个缓解机制,当发现有fdatasync的时候,先不进行write,而直接将数据存储在Redis自身的cache中,但是如果超过2s还是这样,还是会继续调用write,然后打印日志,将aof_delayed_fsync变量加一。
因此,对于appendonly=everysec这个刷盘策略下最严谨的说法是:Redis意外关闭会造成最多不超过2s的数据丢失。
其实上文中已经提到了一种方案,就是利用SSD替换HDD磁盘,在你的写入量很大的时候,这可能是一个能够立竿见影的好方法。
当然,通过一些参数的简单调整,也能够一定程度上缓解这个问题:
方法一:配置修改
Redis在执行write的时候,由操作系统自身被动控制何时进行fsync。这里如果我们要主动触发操作系统的fsync,可以设置操作系统级别的参数:
# 查看内存的脏页字节大小,设置为0代表由系统自己控制何时调用fsync sysctl -a | grep vm.dirty_bytes vm.dirty_bytes = 0 # 修改为一个小的值,例如32MB,达到这个数据量就fsync,让操作系统fsync这个动作更频繁一点,避免单次fsync太多数据,导致阻塞 echo "vm.dirty_bytes=33554432" >> /etc/sysctl.conf
方法二:关闭RDB或者AOF(安全性换效率)
关闭RDB可减少RDB生成的时候,对磁盘的压力,而关闭AOF则可以减少AOF刷盘对磁盘的压力,从而让Redis的性能达到极致。不过这个方法只能用在纯缓存场景,如果有持久化的要求,则一般不靠谱,因为安全性大大降低,一旦宕机,则数据无法恢复。
一种折中的方案,是从库开启AOF,而主库关闭AOF。