今天在线上遇到了一个MongoDB的问题,这里记录一下。
场景:
1、监控报警某个业务的连接数很高,具体情况如下:
+-------------+---------+---+-------+-----------+-----------+--------+---------+ |HOST |STATE |LAG|VERSION|node_CONF |CONNECTIONS|MEM_USED|DISK_USED| +-------------+---------+---+-------+-----------+-----------+--------+---------+ | | | | | | | | | |10.xx.xxx.xxx|PRIMARY |0 |4.0.4 |P:1;D:0;H:0|1217/10000 |9.3GB |54G | |10.xx.xxx.xxx|SECONDARY|0 |4.0.4 |P:1;D:0;H:0|53/10000 |9.3GB |53G | |10.xx.xxx.xxx|SECONDARY|2 |4.0.4 |P:1;D:0;H:0|50/10000 |10.3GB |54G | +-------------+---------+---+-------+-----------+-----------+--------+---------+
可以看到,Primary节点的连接数有1217,最大连接数是10000.
2、业务反馈某个节点的写入非常慢。超时严重。
1、服务器层面
一般出现这种问题,首先需要排查的,就是服务器层面的问题,服务器层面的问题排除之后,再去看数据库层面的问题。
登录到MongoDB主库所在的服务器,查看服务器层面的监控,可以发现如下现象:

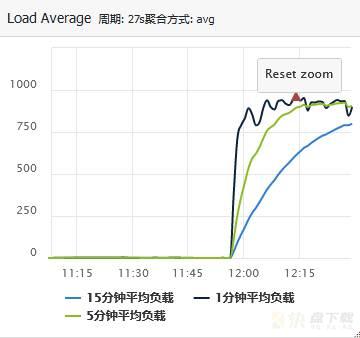
可以看到,服务器的CPU使用率异常,从10%以下上升到100%了;同时,服务器负载异常,从1上升到了900多。
这里,问题基本定位,就是这台服务器的问题,导致业务的响应时间变长,然后由于程序迟迟拿不到结果,所以发起重连,连接数也就自然上升了。
2、数据库层面
然后,我们来看看这台服务器上哪个进程使用的CPU最多。
使用top -c命令,查看当前进程,发现就是当前这个MongoDB占用的CPU最多。
现在问题,就转变成了排查这个MongoDB正在进行的操作,看看到底是什么原因导致的占用CPU这么高的。
先来看看这个MongoDB实例的状态:
mongostat
insert query update delete getmore command dirty used flushes vsize res qrw arw net_in net_out conn set repl time
*0 65 42 *0 8 316|0 4.4% 80.0% 0 14.7G 9.32G 0|808 2|128 518k 890k 1192 index PRI Dec 20 14:31:41.276
*0 26 15 *0 4 122|0 4.5% 80.0% 0 14.7G 9.32G 0|806 1|128 154k 268k 1208 index PRI Dec 20 14:31:45.328
*0 40 21 *0 7 159|0 4.5% 80.0% 0 14.7G 9.32G 0|790 1|128 228k 359k 1222 index PRI Dec 20 14:31:47.988
*0 134 132 *0 16 646|0 4.6% 80.0% 0 14.7G 9.32G 0|803 2|128 987k 1.32m 1213 index PRI Dec 20 14:31:49.494
*0 36 66 *0 4 150|0 4.7% 79.9% 0 14.7G 9.32G 0|814 3|127 218k 389k 1203 index PRI Dec 20 14:31:54.656
*0 46 90 *0 7 289|0 4.8% 80.0% 0 14.7G 9.32G 0|764 2|128 230k 336k 1239 index PRI Dec 20 14:31:57.625
*0 90 179 *0 8 379|0 4.8% 80.0% 0 14.8G 9.32G 0|791 2|127 490k 779k 1271 index PRI Dec 20 14:31:59.123
发现没有insert操作,大部分都是update操作。
然后根据这个update操作,查看这个MongoDB的日志,可以看到很多的update慢日志:
2021-12-20T14:34:10.052+0800 I WRITE [conn1573045] update db.tbl
command: { q: { unique_id: "community:9394+315186" }, u: { unique_id: "community:9394+315186", object_id: "9394+315186",
from: "community", tags: [], tag_scores: [], quality_score: 0.001, online: "1",
update_time: new Date(1639981985000), create_time: new Date(1639981323000) },
multi: false, upsert: true }
planSummary: COLLSCAN keysExamined:0 docsExamined:574333 nMatched:0 nModified:0 fastmodinsert:1
upsert:1 keysInserted:3 numYields:4510 locks:{ Global: { acquireCount: { r: 4512, w: 4512 } },
Database: { acquireCount: { w: 4512 } }, Collection: { acquireCount: { w: 4512 } } }
32618 ms
2021-12-20T14:34:10.160+0800 I WRITE [conn1573082] update db.tbl
command: { q: { unique_id: "community:9394+315187" },
u: { unique_id: "community:9394+315187", object_id: "9394+315187",
from: "community", tags: [], tag_scores: [], quality_score: 0.001, online: "1",
update_time: new Date(1639981986000), create_time: new Date(1639981377000) },
multi: false, upsert: true }
planSummary: COLLSCAN keysExamined:0 docsExamined:574379 nMatched:0 nModified:0 fastmodinsert:1
upsert:1 keysInserted:3 numYields:4505 locks:{ Global: { acquireCount: { r: 4507, w: 4507 } },
Database: { acquireCount: { w: 4507 } }, Collection: { acquireCount: { w: 4507 } } }
30591 ms
可以看到,MongoDB的慢日志有很多时间超过30s的,扫描方法是全表扫描,扫描行数有57w行左右。
同时,update更新的条件是unique_id=“community:9394+315187”
到这里,问题可以定位了。
这个集合中的unique_id字段没有索引,但是却根据这个字段进行更新,导致所有的更新匹配都会扫描全表。而业务侧是今天才大量上线这个update语句,所以是突然大量超时。
这个问题的解决方案,其实也比较简单,就是给对应的数据库集合添加索引即可:
db.coll.createIndex({ "unique_id": 1 },{background:true});
注意,这里使用了background后台添加,是为了不阻塞前台的业务访问。
添加了索引之后,业务反馈响应超时问题解决,查看相关监控,监控显示如下:


可以看到,CPU使用率从100%降低到了10%以下,而负载从800多,降低到了1左右。
再来看连接数:
+-------------+---------+---+-------+-----------+-----------+--------+---------+ |HOST |STATE |LAG|VERSION|NODE_CONF |CONNECTIONS|MEM_USED|DISK_USED| +-------------+---------+---+-------+-----------+-----------+--------+---------+ | | | | | | | | | |10.xx.xxx.xxx|PRIMARY |0 |4.0.4 |P:1;D:0;H:0|86/10000 |9.5GB |54G | |10.xx.xxx.xxx|SECONDARY|0 |4.0.4 |P:1;D:0;H:0|58/10000 |9.5GB |54G | |10.xx.xxx.xxx|SECONDARY|0 |4.0.4 |P:1;D:0;H:0|51/10000 |10.4GB |54G | +-------------+---------+---+-------+-----------+-----------+--------+---------+
连接数也从1217变成了86个,回归正常。
至此,问题得到了解决。
这个问题本身比较简单,处理方法也比较简单,但是,这个排查并定位问题的过程值得总结,其实任何一种数据库问题的排查,都可以采用这种方法,无论是mysql、MongoDB、redis、MC、还是TiDB,我们尝试总结一下:
1、搞清楚问题背景,此时的业务现象;
2、搞清楚当前出问题数据库的架构,确认是主库问题还是从库问题,如果是分布式集群,要先定位到是哪一个节点的问题;
3、排查当前数据库所在的服务器的情况,例如CPU、内存、磁盘、网卡流量、负载等
4、如果服务器不存在问题,进一步定位服务器上的数据库状态,先确定数据库目前正在进行的操作。这里可以借助监控信息或者数据库本身自带的一些命令。
5、定位出具体的数据库操作,联系业务方解决,通常给出优化建议即可。
这个问题中,其实只是一个小小的索引没有创建,就会导致CPU的负载飙升800多倍,其实还是挺吓人的。在数据量小的时候,加不加索引,其实问题不大,但是当数据量很大,访问频繁的时候,没有索引就会导致灾难。
对于线上环境,任何一个隐患都不能放过,以上。
















