文章目录
- YARN的基础配置
- nodeManager CPU配置
- NodeManager 内存配置
- NodeManager 本地目录
- MapReduce内存配置
- HDFS副本数配置
- Hive配置及优化
- HiveServer2的Java堆栈
- Hive动态生成分区的线程数
- Hive监听输入文件线程数
- 压缩配置
- Map输出压缩
- Reduce结果压缩
- Hive多个Map-Reduce中间数据压缩
- Hive最终结果压缩
YARN的基础配置
NodeManager CPU配置
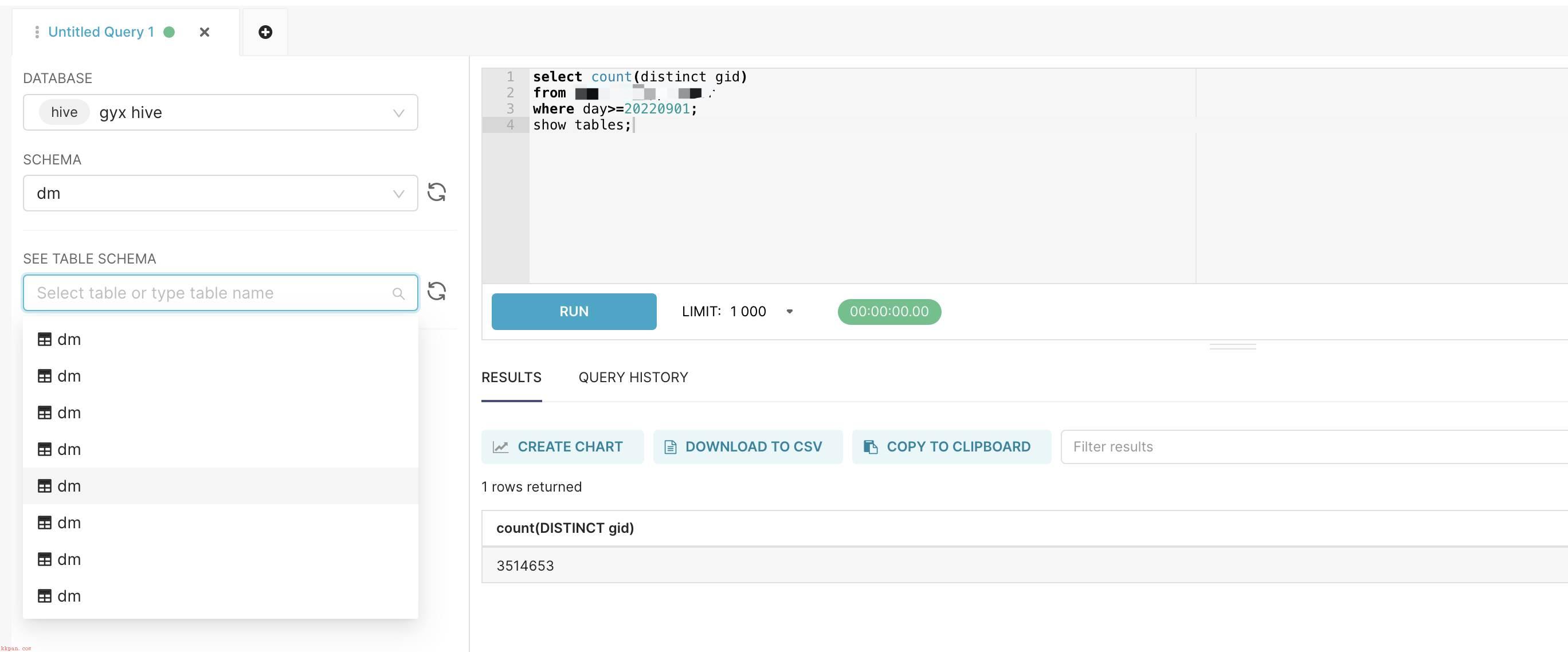
- 在YARN界面中;点击配置;然后搜索配置项;yarn.nodemanager.resource.cpu-vcores


- 此选项表示该节点服务器上yarn可以使用的虚拟CPU个数;默认值是8;推荐将值配置与物理CPU线程数相同;如果节点CPU核心不足8个;要调小这个值;yarn不会智能的去检测物理核心数;实际生产环境要比这个大很多;测试环境核数比较小;。
- 在CDH主机的界面中我们可以看到每台虚机的核数;如下图所示;


- 同样我们也可以在使用命令linux上面查看每台虚机的CPU核数;
grep ;processor; /proc/cpuinfo | sort -u | wc -l

NodeManager 内存配置
- 在YARN界面中;点击配置;然后搜索配置项;yarn.nodemanager.resource.memory-mb

- 设置该NodeManager节点上可以为容器分配的总内存;默认为8G;如果节点内存资源不足8G;要减少这个值;yarn不会智能的去检测内存资源;一般按照服务器剩余可用内存资源进行配置。生产上根据经验一般要预留15-20%的内存;那么可用内存就是实际内存*0.8。
- Tips;注意要同时设置yarn.scheduler.maximum-allocation-mb为一样的值;yarn.app.mapreduce.am.command-opts;JVM内存;的值要同步修改为略小的值。


- 在CDH主机的界面中我们可以看到每台虚机的内存;如下图所示;

- 同样我们也可以在使用命令linux上面查看每台虚机的内存;
free -mh

NodeManager 本地目录
- 在YARN界面中;点击配置;然后搜索配置项;yarn.nodemanager.local-dirs;NodeManager 存储中间数据文件的本地文件系统中的目录列表。如果单台服务器上有多个磁盘挂载;则配置的值应当是分布在各个磁盘上目录;这样可以充分利用节点的IO读写能力。

MapReduce内存配置
-
当MR内存溢出时;可以根据服务器配置进行调整
-
为作业的每个 Map 任务分配的物理内存量(MiB);默认为0;自动判断大小配置项为;mapreduce.map.memory.mb。

-
为作业的每个 Reduce 任务分配的物理内存量(MiB);默认为0;自动判断大小配置项为;mapreduce.reduce.memory.mb。。

-
Map和Reduce的JVM配置选项;配置项为;mapreduce.map.java.opts、mapreduce.reduce.java.opts。


-
Tips;
mapreduce.map.java.opts一定要小于mapreduce.map.memory.mb;大约为0.9倍;。
mapreduce.reduce.java.opts一定要小于mapreduce.reduce.memory.mb;大约为0.9倍;。
HDFS副本数配置
-
在HDFS界面中;点击配置;然后搜索配置项;

-
文件副本数通常默认值为3;此配置项不建议修改;如果在开发或测试环境中只有两台node;建议讲此数值修改为2。
-
hadoop3.x以上的版本, 支持设置副本数量为 1.5。其中 0.5 不是指的存储了一半, 而是采用纠删码来存储这一份数据的信息, 而纠删码只占用数据的一半。
Hive配置及优化
HiveServer2的Java堆栈
- 如果Hiveserver2异常退出;导致连接失败的问题;如下图

- 此类报错通常情况下是OOM的情况;需要修改HiveServer2的Java堆栈。在Hive界面中;点击配置;然后搜索配置项;HiveServer2 的 Java 堆栈大小

- 设置完成之后重启Hive服务即可。
Hive动态生成分区的线程数
-
在Hive界面中;点击配置;然后搜索配置项;hive.load.dynamic.partitions.thread。

-
此配置项用于加载动态生成的分区的线程数。加载需要将文件重命名为它的最终位置;并更新关于新分区的一些元数据。默认值为 15 。
-
当有大量动态生成的分区时;增加这个值可以提高性能。根据服务器配置修改。
Hive监听输入文件线程数
- 在Hive界面中;点击配置;然后搜索配置项;hive.exec.input.listing.max.threads。

- 此配置项用来监听输入文件的最大线程数。默认值;15。
- 当需要读取大量分区时;增加这个值可以提高性能。根据服务器配置进行调整。
压缩配置
Map输出压缩
- 除了创建表时指定保存数据时压缩;在查询分析过程中;Map的输出也可以进行压缩。由于map任务的输出需要写到磁盘并通过网络传输到reducer节点;所以通过使用LZO、LZ4或者Snappy这样的快速压缩方式;是可以获得性能提升的;因为需要传输的数据减少了。
- 在YARN界面中;点击配置;然后搜索配置项;mapreduce.map.output.compress/mapreduce.map.output.compress.codec。

- 此配置项设置是否启动map输出压缩;默认为false。在需要减少网络传输的时候;可以设置为true。
- 此配置项map输出压缩编码解码器;默认org.apache.hadoop.io.compress.DefaultCodec;推荐使用SnappyCodec;org.apache.hadoop.io.compress.SnappyCodec。
Reduce结果压缩
- 是否对任务输出结果压缩;默认值false。对传输数据进行压缩;既可以减少文件的存储空间;又可以加快数据在网络不同节点之间的传输速度。
- 在YARN界面中;点击配置;然后搜索配置项;mapreduce.output.fileoutputformat.compress
mapreduce.output.fileoutputformat.compress.codec
mapreduce.output.fileoutputformat.compress.type

- 是否启用 MapReduce 作业输出压缩
- 指定要使用的压缩编码解码器;推荐SnappyCodec
- 指定MapReduce作业输出的压缩方式;默认值RECORD;可配置值有;NONE、RECORD、BLOCK;推荐使用BLOCK;批量压缩;。
Hive多个Map-Reduce中间数据压缩
- 控制Hive在多个map-reduce作业之间生成的中间文件是否被压缩。压缩编解码器和其他选项由上面Hive通用压缩mapreduce.output.fileoutputformat.compress.*确定。
- 通常在hue的查询页面中输入以下命令;
set hive.exec.compress.intermediate=true;
Hive最终结果压缩
- 控制是否压缩查询的最终输出(到 local/hdfs 文件或 Hive table)。压缩编解码器和其他选项由 上面Hive通用压缩mapreduce.output.fileoutputformat.compress.*确定。
- 通常在hue的查询页面中输入以下命令;
set hive.exec.compress.output=true;